Microsoft Foundry で gpt-5.2, gpt-5-mini, gpt-5-nano を使った場合のreasoning effort の違いを少し調べました。
結論
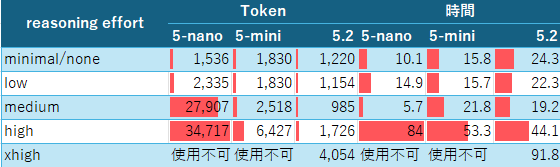
各モデルごとのreasoning effortでのToken使用量(Output)と処理時間の結果です(呼び出し方は後述)。
- モデルによって使えないモードがあります。
- gpt-5.2 の最小reasoning effort はnoneですが、gpt-5-nano/mini の最小はminimal です(gpt-5.2はminimal非対応)。
- 時間はPython側で計測しており、ネットワーク時間も含んでいて概算での値です(秒単位)
以下はAIに結果を分析させた内容です。特に検証はしておらず、誤りを含んでいるかもしれません。
分析結果
概要
reasoning effort は「推論の強さ」ではなく
「モデル内部アルゴリズムを切り替えるスイッチ」である
ということが、数値的に明確に確認できた。
測定結果(要約)
Output Tokens
| reasoning effort | gpt-5-nano | gpt-5-mini | gpt-5.2 |
|---|---|---|---|
| minimal / none | 1,536 | 1,830 | 1,220 |
| low | 2,335 | 1,830 | 1,154 |
| medium | 27,907 | 2,518 | 985 |
| high | 34,717 | 6,427 | 1,726 |
| xhigh | 使用不可 | 使用不可 | 4,054 |
処理時間(秒)
| reasoning effort | gpt-5-nano | gpt-5-mini | gpt-5.2 |
|---|---|---|---|
| minimal / none | 10.1 | 15.8 | 24.3 |
| low | 14.9 | 15.7 | 22.3 |
| medium | 5.7 | 21.8 | 19.2 |
| high | 84.0 | 53.3 | 44.1 |
| xhigh | 使用不可 | 使用不可 | 91.8 |
重要な観測ポイント
1. gpt-5-nano / mini では medium 以上で挙動が激変する
-
gpt-5-nano
-
low → mediumで Output Tokens が 約12倍 -
highでは 3万トークン超・80秒超
-
-
gpt-5-mini
-
medium → highで tokens / 時間が 指数的に増加
-
👉 reasoning effort を上げた瞬間に、内部モードが切り替わっている
2. gpt-5.2 は唯一「制御された増加」を示す
-
effort を上げても
- トークン数・時間が 線形に近い増え方
-
xhighを 唯一サポート -
特に
mediumで 最小トークン を記録
👉 gpt-5.2 は reasoning 前提で設計されたモデル
3. gpt-5.2 では「reasoning を入れると出力が短くなる」
-
none:流れで生成 → 冗長 -
medium:内部で整理 → 無駄な出力が削減
👉 reasoning effort は
「考える量を増やす」スイッチではない
モデル別の内部挙動の解釈
gpt-5-nano
-
none / low:非推論・高速モード -
medium 以上:
→ 軽量モデルが推論を試みて暴走
結論
- nano は 推論用途ではない
-
medium以上は設計想定外
gpt-5-mini
-
none / low:安定 -
medium:標準推論(スイートスポット) -
high:推論ステップが過剰に増加
結論
- mini は medium が最適
- high は「賢くなる」より「遅くなる」
gpt-5.2
- effort に対する挙動が最も安定
- medium が 品質・コスト・速度の最適点
- high / xhigh は高度推論専用
結論
- reasoning effort を使うなら gpt-5.2 一択
実務向けベストプラクティス
gpt-5-nano
推奨: reasoning effort = none / low
非推奨: medium 以上
用途: 整形、要約、分類、RAG後段、低レイテンシ
gpt-5-mini
推奨: reasoning effort = medium
次点: low
非推奨: high
用途: 軽い推論、条件分岐、業務ロジック補助
gpt-5.2
推奨: reasoning effort = medium
高度推論: high / xhigh(限定用途)
用途: 複雑な判断、設計、分析、意思決定支援
本分析の本質的な結論
reasoning effort は「知能レベル調整」ではなく
「内部推論アルゴリズム切替スイッチ」である
- nano / mini は 推論を前提としていない
- gpt-5.2 は 推論を前提に最適化されている
- effort を上げれば良くなる、は誤解
まとめ(短く)
- gpt-5-nano で
medium以上は 地雷 - gpt-5-mini は medium が最適解
- gpt-5.2 は medium が最小トークンかつ高品質
- reasoning effort は 用途別に明示指定すべき
計測したScript
環境
GitHub Codespaces で以下のdevcontainerで動かしています。
// For format details, see https://aka.ms/devcontainer.json. For config options, see the
// README at: https://github.com/devcontainers/templates/tree/main/src/python
{
"name": "Python 3",
// Or use a Dockerfile or Docker Compose file. More info: https://containers.dev/guide/dockerfile
"image": "mcr.microsoft.com/devcontainers/python:3-3.11-bookworm",
"features": {
"ghcr.io/devcontainers-extra/features/uv:1": {},
"ghcr.io/devcontainers/features/git-lfs:1": {}
},
// Configure tool-specific properties.
"customizations": {
"vscode": {
"extensions": [
"ms-python.python",
"ms-python.vscode-pylance",
"ms-toolsai.jupyter"
]
}
}
// Uncomment to connect as root instead. More info: https://aka.ms/dev-containers-non-root.
// "remoteUser": "root"
}
雑に作ったプログラムです。Responses APIと Chat Completionsで違うかもと思い、どちらでも呼べるようにしています(結果は変わらず)。
ユーザプロンプトは、Reasoningの結果に差が出るようにAIに作ってもらったものをそのまま採用。
import os
import time
from dotenv import load_dotenv
from openai import OpenAI
import pandas as pd
load_dotenv(override=True)
def create_openai_client():
"""
Create and return an Azure OpenAI client instance.
Returns:
OpenAI: Configured OpenAI client
"""
client = OpenAI(
base_url=os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
)
return client
client = create_openai_client()
def call_llm(
client: OpenAI,
messages: list,
api_kind: str,
deployment_name: str,
reasoning_effort: str ):
api_params = {
"model": deployment_name,
}
if deployment_name == "gpt-5.2" and reasoning_effort == "none":
api_params["temperature"] = 0.0
start_time = time.time()
if api_kind == "chat_completions":
api_params["messages"] = messages
api_params["reasoning_effort"] = reasoning_effort
response = client.chat.completions.create(**api_params)
result = {
"deployment": deployment_name,
"reasoning_effort": reasoning_effort,
"process_time_ms": (time.time() - start_time) * 1000,
"output_tokens": response.usage.completion_tokens,
"response": response.choices[0].message.content,
}
else:
api_params["input"] = messages
api_params["reasoning"] = {"effort": reasoning_effort}
response = client.responses.parse(**api_params)
result = {
"deployment": deployment_name,
"reasoning_effort": reasoning_effort,
"process_time_ms": (time.time() - start_time) * 1000,
"output_tokens": response.usage.output_tokens,
"response": response.output_text,
}
return result
user_prompt = """
あなたはSaaSのプロダクトマネージャーです。
以下の制約をすべて満たす料金プランを設計してください。
- ユーザーは3種類(個人 / SMB / エンタープライズ)
- 月額売上を最大化したいが、解約率も抑えたい
- 個人ユーザーは価格に敏感
- エンタープライズはサポート品質を重視
- プランは最大3つまで
- 各プランの価格と理由を説明すること
"""
# responses APIでも、共通化させるためにあえてこの形式
messages = [
{"role": "system", "content": "あなたは親切なアシスタントです。"},
{"role": "user", "content": user_prompt}
]
result = call_llm(client, messages, "chat-completions", "gpt-5.2", "minimal")
print(result)
results = []
#"minimal",
for reasoning in ["none", "low", "medium", "high", "xhigh"]:
result = call_llm(client, messages, "responses", "gpt-5.2", reasoning)
results.append(result)
print(result)
for deployment in ["gpt-5-mini", "gpt-5-nano"]:
for reasoning in ["minimal", "low", "medium", "high"]:
result = call_llm(client, messages, "responses", deployment, reasoning)
results.append(result)
print(result)
df = pd.DataFrame(results)
エラー
reasoning effort エラー
使えないreasoning effort選ぶと以下のようなエラー
BadRequestError: Error code: 400 - {'error':
{'message': "Unsupported value: 'minimal' is not supported with the 'gpt-5.2-2025-12-11' model. Supported values are: 'none', 'low', 'medium', 'high', and 'xhigh'.", 'type': 'invalid_request_error', 'param': 'reasoning.effort', 'code': 'unsupported_value'}}
BadRequestError: Error code: 400 - {'error':
{'message': "Unsupported value: 'none' is not supported with the 'gpt-5-nano-2025-08-07' model. Supported values are: 'minimal', 'low', 'medium', and 'high'.", 'type': 'invalid_request_error', 'param': 'reasoning.effort', 'code': 'unsupported_value'}}
temperature エラー
あと、gpt-5-nano、gpt-5-mini は temperatureを1以外にするとエラー。reasoning effortがnoneにできないので、0に設定できないのはわかりますが、0.1とかにはしたいです。
gpt-5.2でもreasoning effort をnone以外に設定するとtemperatureは1以外に設定できないです。
Error calling Chat Completion API: Error code: 400 - {'error':
{'message': "Unsupported value: 'temperature' does not support 0.7 with this model. Only the default (1) value is supported.", 'type': 'invalid_request_error', 'param': 'temperature', 'code': 'unsupported_value'}}
参考
reasoning
OpenAI公式ページ
使用可能なreasoning effort
使用可能なreasoning effort に関する記述
class Reasoning(TypedDict, total=False):
"""**gpt-5 and o-series models only**
Configuration options for
[reasoning models](https://platform.openai.com/docs/guides/reasoning).
"""
effort: Optional[ReasoningEffort]
"""
Constrains effort on reasoning for
[reasoning models](https://platform.openai.com/docs/guides/reasoning). Currently
supported values are `none`, `minimal`, `low`, `medium`, `high`, and `xhigh`.
Reducing reasoning effort can result in faster responses and fewer tokens used
on reasoning in a response.
- `gpt-5.1` defaults to `none`, which does not perform reasoning. The supported
reasoning values for `gpt-5.1` are `none`, `low`, `medium`, and `high`. Tool
calls are supported for all reasoning values in gpt-5.1.
- All models before `gpt-5.1` default to `medium` reasoning effort, and do not
support `none`.
- The `gpt-5-pro` model defaults to (and only supports) `high` reasoning effort.
- `xhigh` is supported for all models after `gpt-5.1-codex-max`.
"""