Azure AI Foundryでgpt-4o-miniのQAタスクのファインチューニングしてみます。
基本的には以下の方法に従っています。
上記に記載がありますが、フルファインチューニングではなく、PEFT-LoRaでファインチューニングします。LoRaが何かはここには記載をしませんが、記事「LLM入門: 無料講座「Generative AI with Large Language Models」で入門してみた」で勉強元を書いています。多分、検索すればすぐに解説サイトなどあると思います。
LoRA (低ランク近似) を使用して、パフォーマンスに大きな影響を与えることなく複雑さを軽減する方法でモデルを微調整します。
Python SDKでやった場合の記事はこちらに記載しています。
ファインチューニングそのものは100データで1レコードのTokenも少ないので100円程度で終わりました。ただ、モデルデプロイを放置すると結構課金されるので注意しましょう。
処理
0. 前提
Azure AI Foundryの基本的なリソースはAzure Portalから作成済です。AI Projectも作成済です。すべてrg-finetune-ncusというリソースグループにひもづけています。
$ az resource list -g rg-finetune-ncus -o table
Name ResourceGroup Location Type Status
------------------------ ---------------- -------------- -------------------------------------------- --------
aihfinetunencu3189227722 rg-finetune-ncus northcentralus Microsoft.CognitiveServices/accounts
aihfinetunencu0261894237 rg-finetune-ncus northcentralus Microsoft.Storage/storageAccounts
aihfinetunencu9989517679 rg-finetune-ncus northcentralus Microsoft.KeyVault/vaults
aih-finetune-ncus rg-finetune-ncus northcentralus Microsoft.MachineLearningServices/workspaces
admin-finetune-nucs rg-finetune-ncus northcentralus Microsoft.MachineLearningServices/workspaces
1. 訓練/検証ファイル準備
訓練および検証に使うファイルを準備します。UTF-8 でエンコードしてバイトオーダー マーク (BOM) ありでJSONLファイルを作成します。
1.1. CSV準備
このプロセスは、私がファイルを作った過程なので必須ではありませんし、実行するにしても好きに作ってください。1.3.のプロセスから直接始めてもOKです。
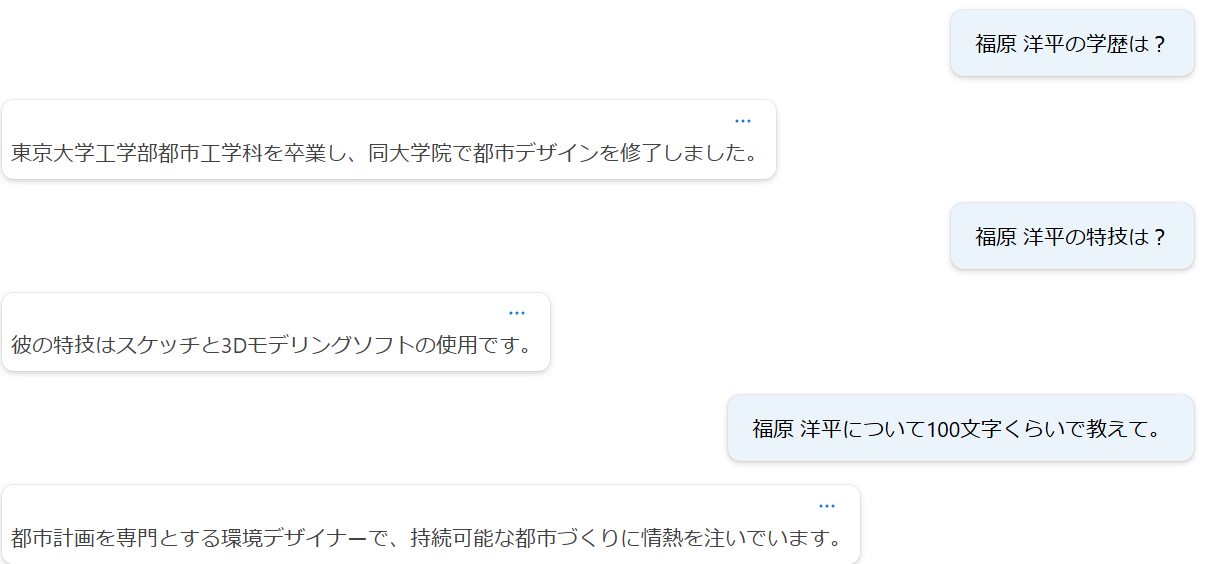
まずは、「福原洋平」という人物の架空のプロフィールを作成し、そのプロフィールに対してCSV形式でQA形式のファイルを作成しました。100レコードのファイルです。
prompt,completion
福原洋平さんの職業は何ですか?,福原洋平さんは都市計画コンサルタント兼環境デザイナーとして活躍しています。
福原洋平さんの出身地はどこですか?,福原洋平さんは神奈川県横浜市の出身です。
福原洋平さんの学歴について教えてください。,福原洋平さんは東京大学工学部都市工学科を卒業後、カリフォルニア大学バークレー校で環境デザイン学の修士課程を修了しました。
後略
1.2. JSONL形式変換プログラム作成
ファインチューニングする形式に変換するPythonプログラムを作成します。
環境
| 種類 | バージョン | 備考 |
|---|---|---|
| Python(Pyenv) | 3.10.2 | 古いのに特に意味はないです。たまたますぐ使えた環境 |
| Ubuntu(WSL2) | 22.04.5 LTS | |
| Poetry | 1.7.1 |
Python 追加パッケージ
あまりたいしたことに使っていませんがpandasのみ。
| 種類 | バージョン | 備考 |
|---|---|---|
| pandas | 2.2.3 |
Pythonプログラム
パッケージインポート
import json
import pandas as pd
CSVファイル読込
ディレクトリdata配下に先ほどのcsvファイルを置いていて、そこから読込。
df = pd.read_csv('./data/test.csv')
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 100 entries, 0 to 99
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 prompt 100 non-null object
1 completion 100 non-null object
dtypes: object(2)
memory usage: 1.7+ KB
jsonl形式に変換
JSONL形式に変換しています。systemロールのメッセージは適当です。
def output_jsonl(file_name: str, df: pd.DataFrame) -> None:
with open('./data/'+file_name, "w", encoding="utf-8") as f:
for _, row in df.iterrows():
data = {
"messages": [
{"role": "system", "content": "情報を見つけるのに役立つ AI アシスタントです。"},
{"role": "user", "content": row["prompt"]},
{"role": "assistant", "content": row["completion"]}
]
}
f.write(json.dumps(data, ensure_ascii=False) + "\n")
output_jsonl('train.jsonl', df.head(80))
output_jsonl('validation.jsonl', df.tail(20))
1.3. JSONLファイル作成
先ほどのPythonプログラムを実行して訓練用と検証用のJSONLファイルを作成します。
{"messages": [{"role": "system", "content": "情報を見つけるのに役立つ AI アシスタントです。"}, {"role": "user", "content": "福原洋平さんの職業は何ですか?"}, {"role": "assistant", "content": "福原洋平さんは都市計画コンサルタント兼環境デザイナーとして活躍しています。 "}]}
{"messages": [{"role": "system", "content": "情報を見つけるのに役立つ AI アシスタントです。"}, {"role": "user", "content": "福原洋平さんの出身地はどこですか?"}, {"role": "assistant", "content": "福原洋平さんは神奈川県横浜市の出身です。 "}]}
{"messages": [{"role": "system", "content": "情報を見つけるのに役立つ AI アシスタントです。"}, {"role": "user", "content": "福原洋平さんの学歴について教えてください。"}, {"role": "assistant", "content": "福原洋平さんは東京大学工学部都市工学科を卒業後、カリフォルニア大学バークレー校で環境デザイン学の修士課程を修了しました。 "}]}
{"messages": [{"role": "system", "content": "情報を見つけるのに役立つ AI アシスタントです。"}, {"role": "user", "content": "福原洋平さんがプロジェクトで最初に行う作業は?"}, {"role": "assistant", "content": "現地調査と住民の意見収集を最初に行います。 "}]}
{"messages": [{"role": "system", "content": "情報を見つけるのに役立つ AI アシスタントです。"}, {"role": "user", "content": "福原洋平さんが得意なプレゼン方法は?"}, {"role": "assistant", "content": "3Dモデルを使った視覚的なプレゼンを得意としています。 "}]}
{"messages": [{"role": "system", "content": "情報を見つけるのに役立つ AI アシスタントです。"}, {"role": "user", "content": "福原洋平さんが写真撮影を始めた理由は?"}, {"role": "assistant", "content": "都市の変化を記録するために写真を撮り始めました。 "}]}
2. ファインチューニング実施
2.1. ファインチューニングのWizard起動まで
https://oai.azure.com/ で Azure AI Foundry ポータルを開き、Azure OpenAI リソースにアクセスできる資格情報を使用してサインインします。
Azure AI Foundry の OpenAI にフォーカスした画面なので注意
以下のメニュー構成です。
メニューで「微調整」を選択して「+モデルの微調整」ボタンをクリック
2.2. ファインチューニングWizard
2.2.1. モデル選択
「gpt-4o-mini」を選択して「次へ」
2.2.2. 基本設定
画面の入力で「次へ」

2.2.3. トレーニングデータ
前のステップで作成したファイルを選択して、アップロード。
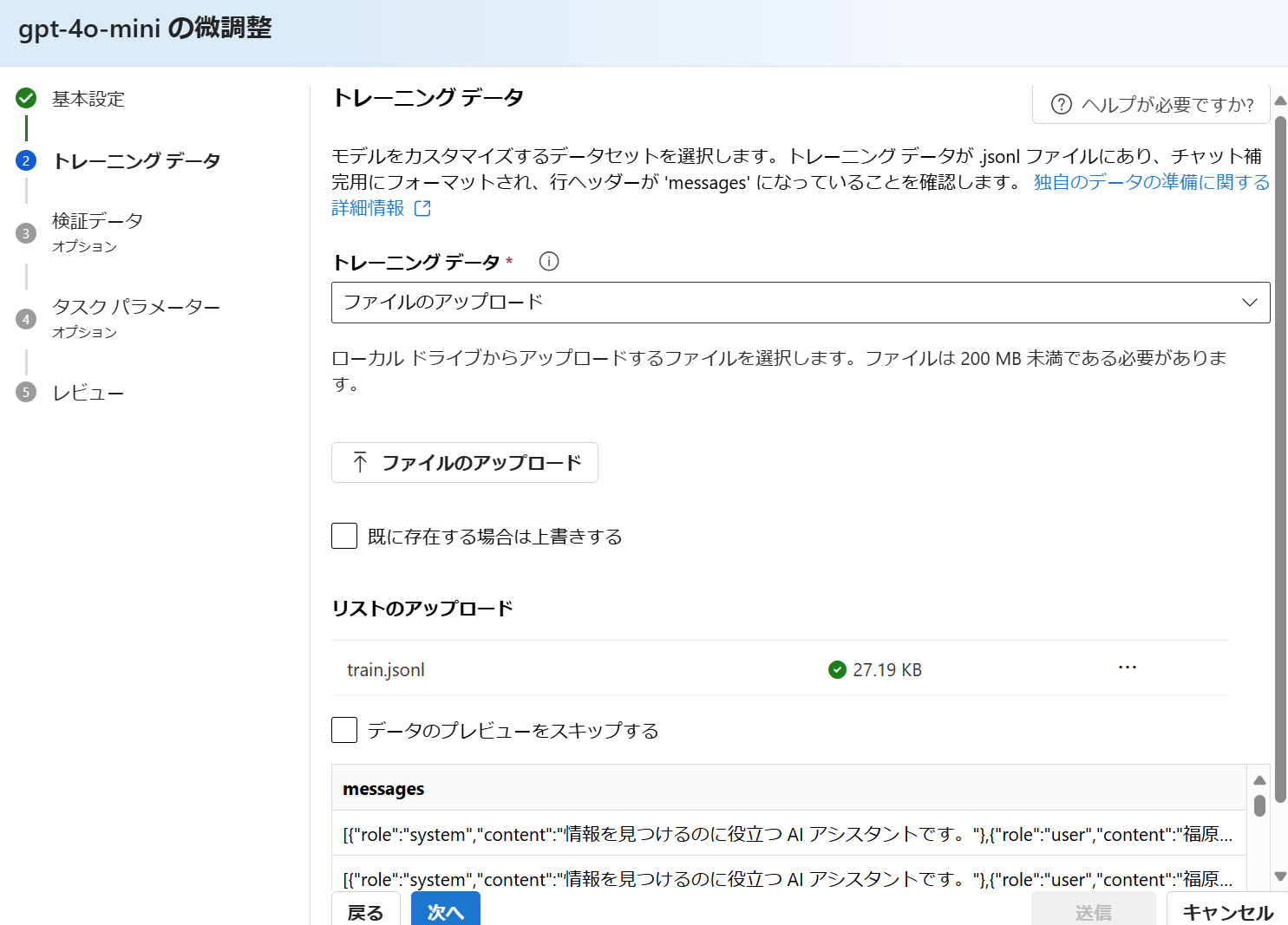
ちなみにアップロードしたデータはメニューの 共有リソース -> データファイル から参照ができ、再利用が可能。
2.2.4. 検証データ
前のステップで作成したファイルを選択して、アップロード。必須ではないので、無視してもOKです。
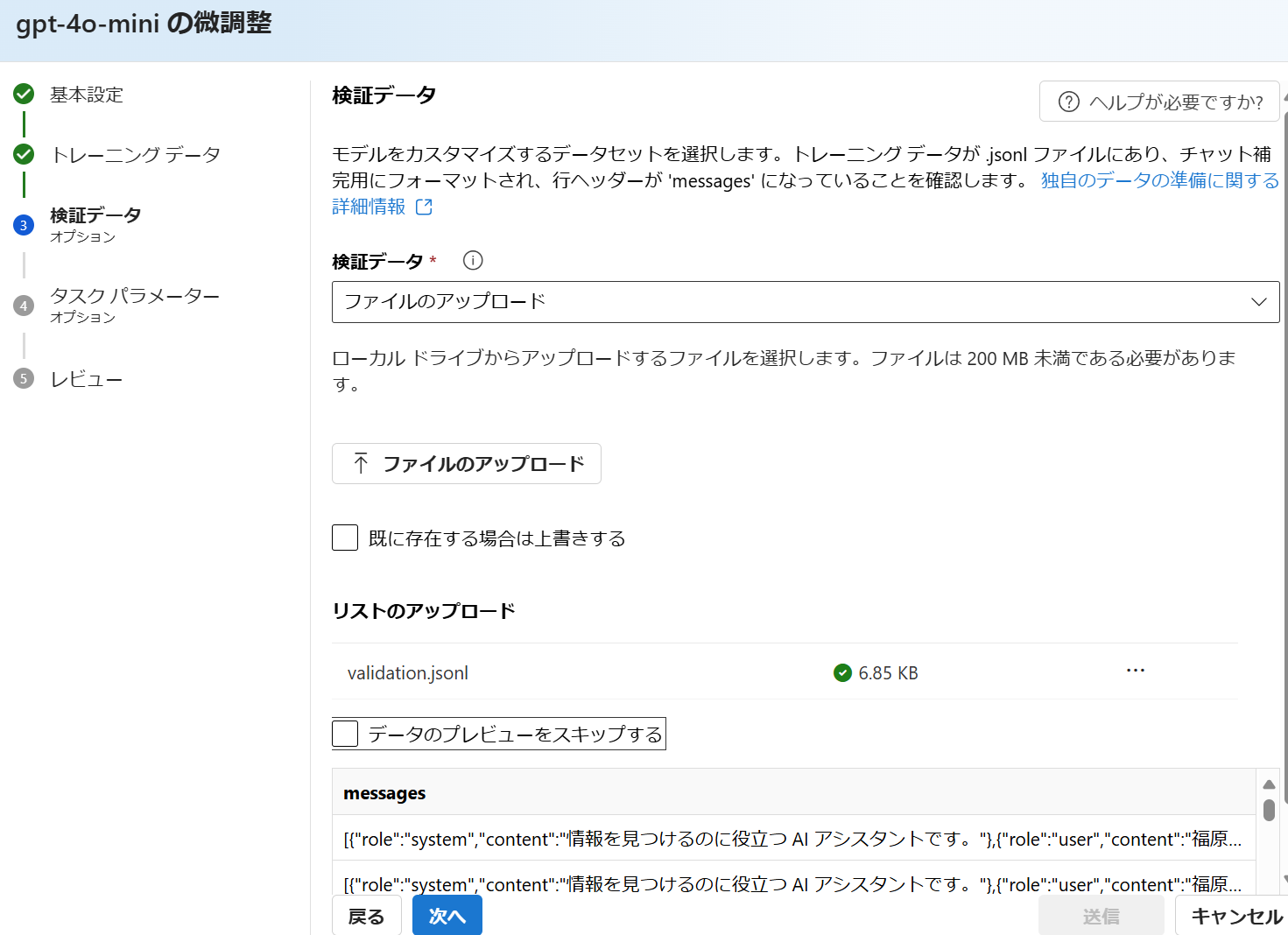
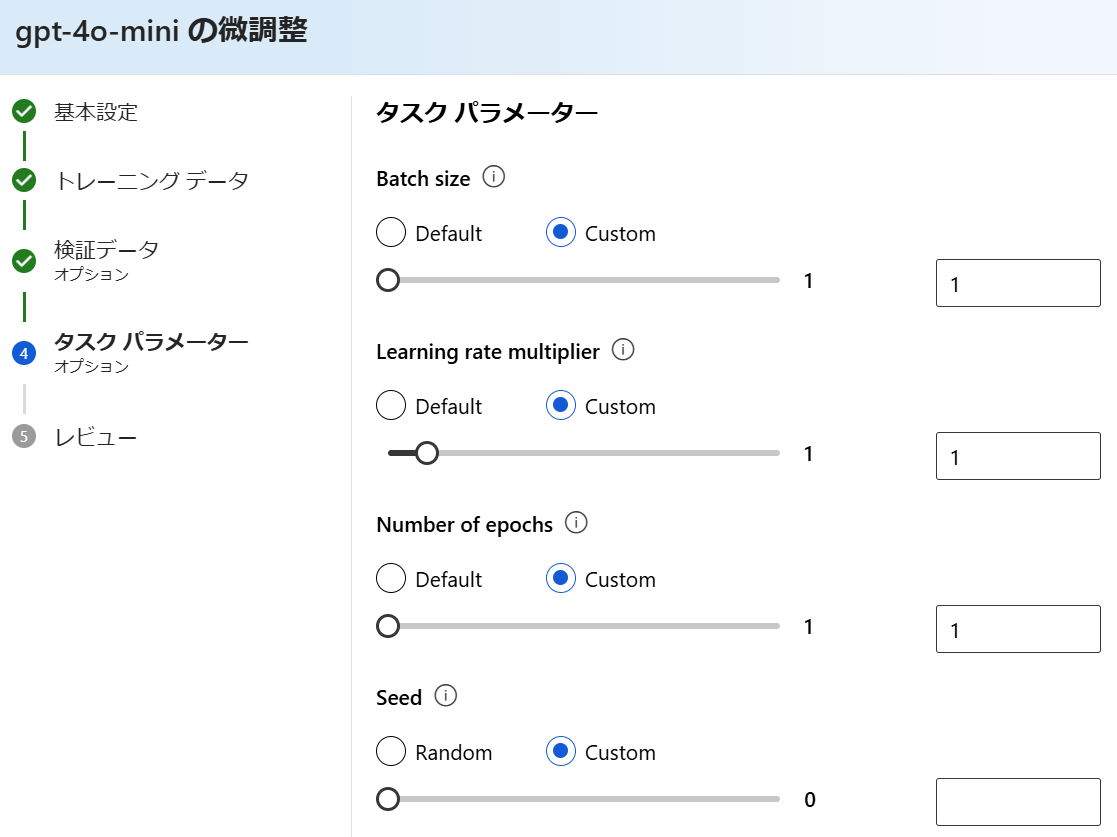
2.2.5. タスクパラメーター
すべて規定値のままにします。値が見たかったので「Custom」を選んでいますが、規定値のままです。
2.2.6. レビュー
「送信」をクリック。ジョブがキューに入ります。
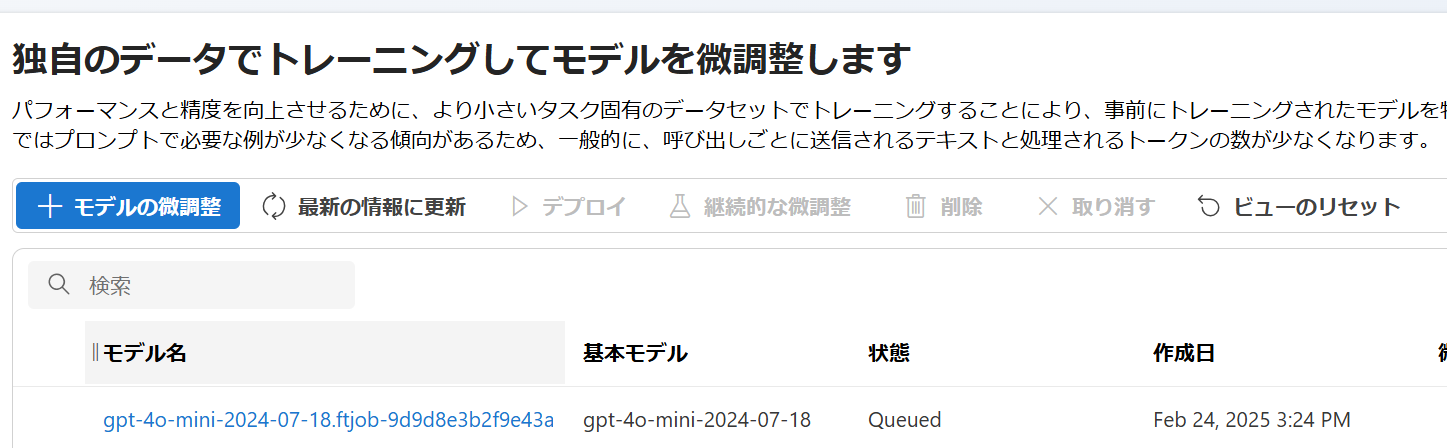
3. 結果確認
3.1. ジョブ
37分で終えました。
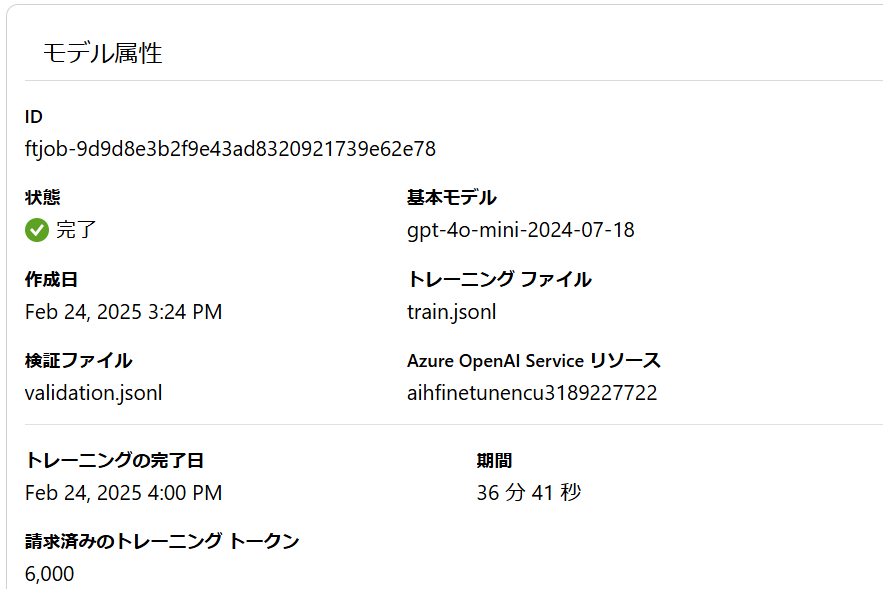
「結果のダウンロード」でcsvファイルを見てみます。

| 列 | 意味 | その他 |
|---|---|---|
| step | ステップ数 | |
| train_loss | 訓練バッチの損失 | |
| train_mean_token_accuracy | 訓練バッチのToken単位での平均正答率 | |
| valid_loss | 検証バッチの損失 | |
| valid_mean_token_accuracy | 検証バッチのToken単位での平均正答率 | |
| full_valid_loss | 各エポックの終了時に計算される検証損失 | 最終行のみ |
| full_valid_mean_token_accuracy | 各エポックの終了時に計算される検証Token単位での平均正答率 | 最終行のみ |
こちらにメトリックの解説あり。
損失に関しては計算式がないですが、クロスエントロピー損失らしいです(未確認)。
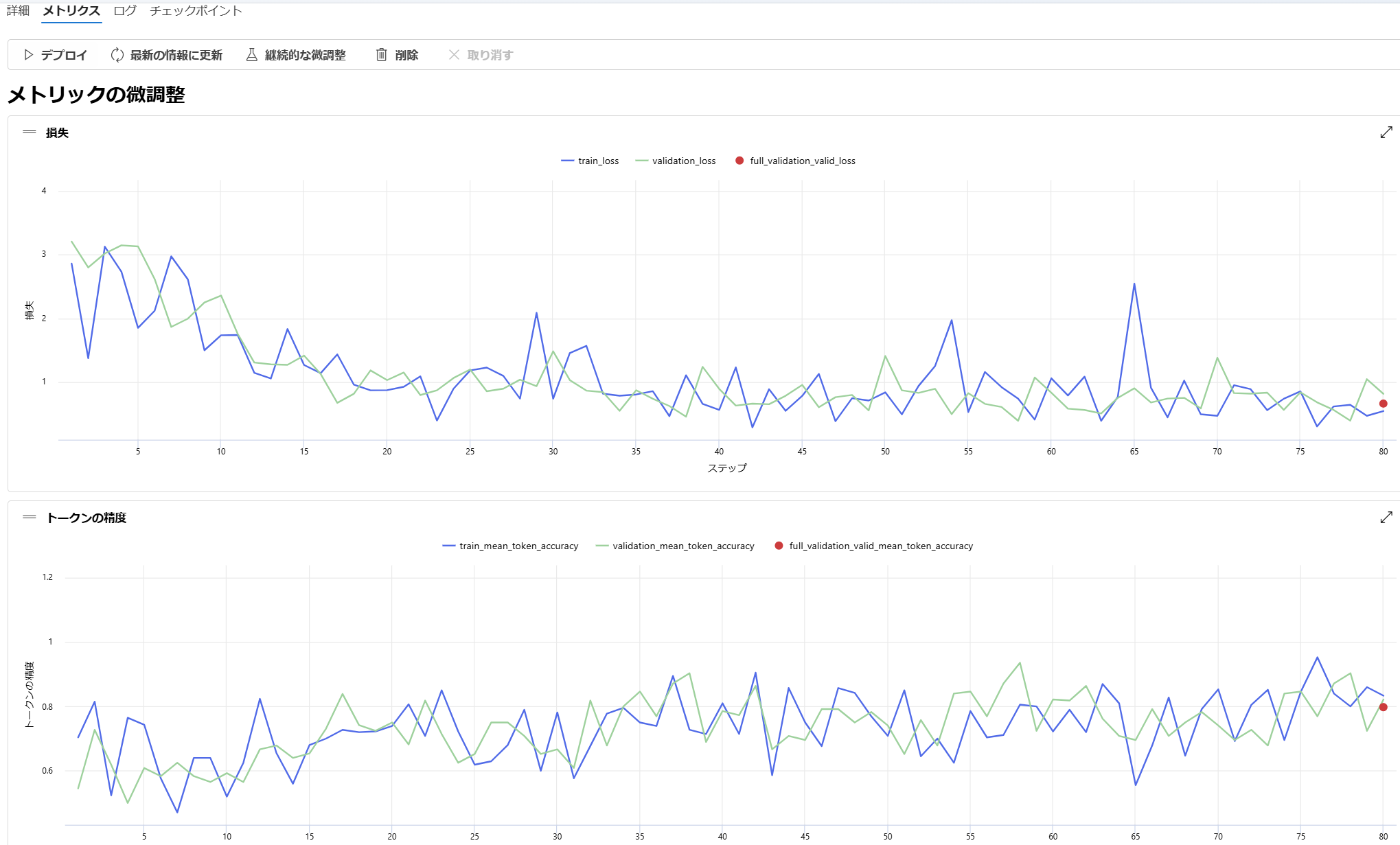
画面上でメトリクスを確認します。
おおざっぱに見て損失は下がっていて、精度は上がっています。
3.2. プレイグラウンド
3.2.1. デプロイ
ファインチューンしたモデルをデプロイします。微調整の詳細画面から「デプロイ」ボタンをクリックするだけです。
「デプロイの種類」はStandardを選んでおきます。デプロイ完了までに30分くらいかかりました。
3.2.2. プレイグラウンド実行
プレイグラウンドで、架空のプロフィールをもとに答えてくれるようになりました!