※本記事は網屋 Tech Blog Advent Calendar 2024 の 12 月 24 日分の記事です。
はじめに
こんにちは。@Fukucchi です。みなさんのレプリカの調子はいかがですか?
分散検索エンジン Elasticsearch の公式ドキュメントの “Reading and Writing documents" (v8.17)では、Elasticsearch において読み書きがどのように行われているかが、レプリケーションの仕組みを中心に述べられています。
本記事ではこのページを要約していこうと思います。
それでは、さっそく本編に入りましょう。
ドキュメントの読み書き(Reading and Writing documents)
導入(Introduction)
Each index in Elasticsearch is divided into shards and each shard can have multiple copies. These copies are known as a replication group and must be kept in sync when documents are added or removed. If we fail to do so, reading from one copy will result in very different results than reading from another. The process of keeping the shard copies in sync and serving reads from them is what we call the data replication model.
-
シャードとレプリケーショングループ
- Elasticsearch ではインデックスを複数のシャードに分割する。
- 各シャードには複数のコピー(レプリカ)を持たせることができ、それらを「レプリケーショングループ」と呼ぶ。
- ドキュメントが更新された際にレプリケーショングループ内で同期しないと、読み取り結果に不整合が生じる。
-
データレプリケーションモデル
- シャードのコピーを常に同期させ、そこからの読み取りを可能にする仕組みを「データレプリケーションモデル」と呼ぶ。
Elasticsearch’s data replication model is based on the primary-backup model and is described very well in the PacificA paper of Microsoft Research. That model is based on having a single copy from the replication group that acts as the primary shard. The other copies are called replica shards. The primary serves as the main entry point for all indexing operations. It is in charge of validating them and making sure they are correct. Once an index operation has been accepted by the primary, the primary is also responsible for replicating the operation to the other copies.
-
Primary-Backup モデル
- Elasticsearch のデータレプリケーションモデルは primary-backup モデルに基づく。
- これは、レプリケーショングループのうち、1 つを「プライマリ」、残りを「レプリカ」として扱う。
-
プライマリの役割
- すべての書き込みリクエストのエントリーポイントはプライマリであり、プライマリで受け入れられたらレプリカへ複製される。
This purpose of this section is to give a high level overview of the Elasticsearch replication model and discuss the implications it has for various interactions between write and read operations.
-
セクションの目的
- Elasticsearch のレプリケーションモデルの全体像を俯瞰し、書き込みと読み取りがどのように相互作用するかを議論する。
基本的な書き込みモデル(Basic write model)
Every indexing operation in Elasticsearch is first resolved to a replication group using routing, typically based on the document ID. Once the replication group has been determined, the operation is forwarded internally to the current primary shard of the group. This stage of indexing is referred to as the coordinating stage.
-
書き込み操作のフローの最初の部分
- Routing: ドキュメント ID などを基に、どのシャード(レプリケーショングループ)へ書き込むかを決める。
- Coordinating stage: 選ばれたグループのプライマリシャードへ転送。
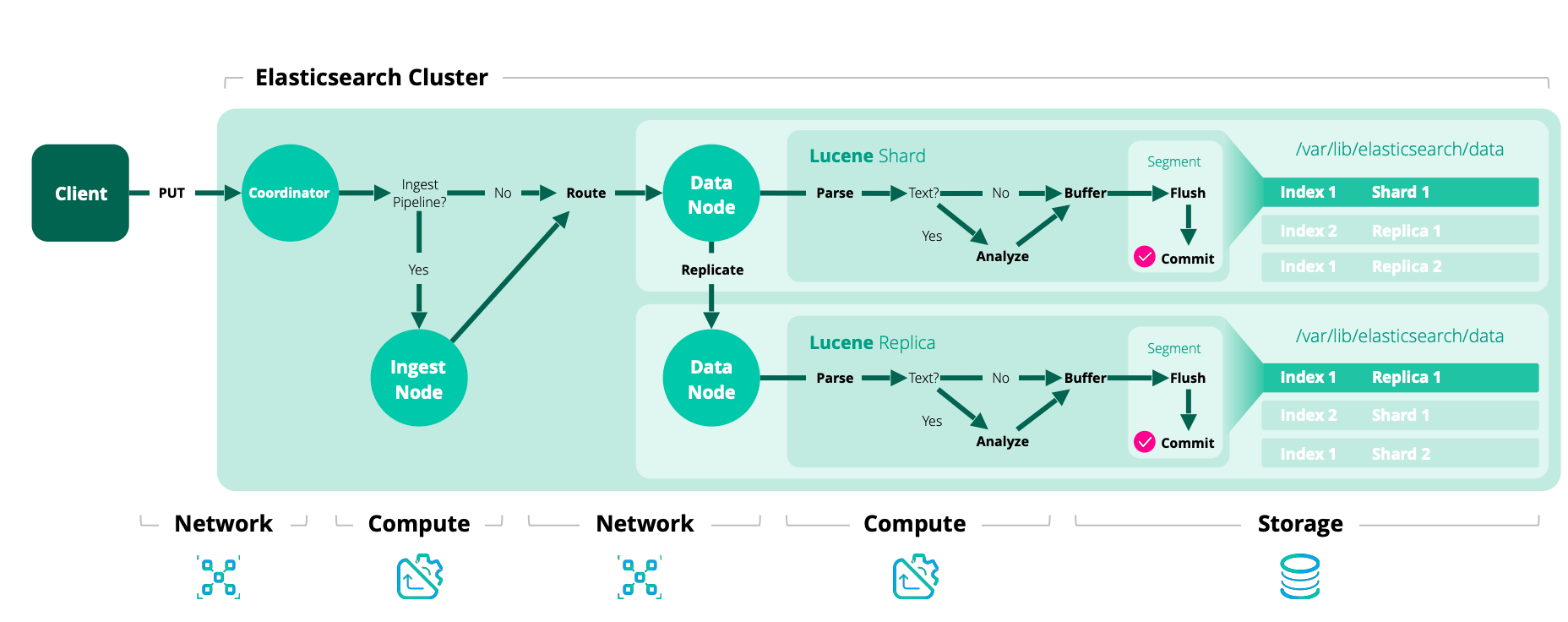
The next stage of indexing is the primary stage, performed on the primary shard. The primary shard is responsible for validating the operation and forwarding it to the other replicas. Since replicas can be offline, the primary is not required to replicate to all replicas. Instead, Elasticsearch maintains a list of shard copies that should receive the operation. This list is called the in-sync copies and is maintained by the master node. As the name implies, these are the set of "good" shard copies that are guaranteed to have processed all of the index and delete operations that have been acknowledged to the user. The primary is responsible for maintaining this invariant and thus has to replicate all operations to each copy in this set.
-
Primary stage
- Coordinating stage の次のステージ。
- プライマリシャードがリクエストを検証して自分自身に適用し、レプリカに転送する。
-
In-sync copies
- マスターが管理する、最新状態を反映できている「良好」なレプリカコピーの集合。
- プライマリはこの集合の全コピーに対して操作を転送し、一貫性を保つ。
The primary shard follows this basic flow:
- Validate incoming operation and reject it if structurally invalid (Example: have an object field where a number is expected)
- Execute the operation locally i.e. indexing or deleting the relevant document. This will also validate the content of fields and reject if needed (Example: a keyword value is too long for indexing in Lucene).
- Forward the operation to each replica in the current in-sync copies set. If there are multiple replicas, this is done in parallel.
- Once all in-sync replicas have successfully performed the operation and responded to the primary, the primary acknowledges the successful completion of the request to the client.
-
Primary stage の詳細
- 構造のバリデーション: JSON フォーマットやフィールドタイプをチェック。
- ローカル適用: プライマリ自身が Lucene インデックスを更新。
- レプリカ転送: in-sync レプリカ全体へ並列で転送。
- ACK: 全レプリカが完了を返したらクライアントへ成功応答を返す。
Each in-sync replica copy performs the indexing operation locally so that it has a copy. This stage of indexing is the replica stage.
-
Replica stage
- レプリカシャードはプライマリから送られた操作をローカルインデックスに適用し、コピーを最新化する。
These indexing stages (coordinating, primary, and replica) are sequential. To enable internal retries, the lifetime of each stage encompasses the lifetime of each subsequent stage. For example, the coordinating stage is not complete until each primary stage, which may be spread out across different primary shards, has completed. Each primary stage will not complete until the in-sync replicas have finished indexing the docs locally and responded to the replica requests.
-
直列性
- Indexing 処理は Coordinating → Primary → Replica の順に直列的に実行される。
-
内部リトライ
- 内部リトライのために、後続ステージが完了するまでは前段ステージも終了しない扱いとなる。
障害処理(Failure handling)
Many things can go wrong during indexing — disks can get corrupted, nodes can be disconnected from each other, or some configuration mistake could cause an operation to fail on a replica despite it being successful on the primary. These are infrequent but the primary has to respond to them.
-
レプリケーションの失敗
- ディスク破損やネットワーク分断、設定ミスなど、レプリケーションにはさまざまな障害要因がある。
-
プライマリの責任
- プライマリはレプリケーション失敗時に整合性を保つよう動作する必要がある。
In the case that the primary itself fails, the node hosting the primary will send a message to the master about it. The indexing operation will wait (up to 1 minute, by default) for the master to promote one of the replicas to be a new primary. The operation will then be forwarded to the new primary for processing. Note that the master also monitors the health of the nodes and may decide to proactively demote a primary. This typically happens when the node holding the primary is isolated from the cluster by a networking issue. See here for more details.
-
プライマリがダウンした場合
- ノードはマスターに通知し、マスターが別レプリカを新たなプライマリに昇格させる。
- Elasticsearch はデフォルトで最大 1 分待ち、昇格後に書き込みリクエストを再度処理する。
-
プロアクティブな降格
- マスター自身がノードのヘルスを監視し、ネットワーク断などでプライマリが分断されたと判断して、プロアクティブにレプリカを昇格させることもある。
Once the operation has been successfully performed on the primary, the primary has to deal with potential failures when executing it on the replica shards. This may be caused by an actual failure on the replica or due to a network issue preventing the operation from reaching the replica (or preventing the replica from responding). All of these share the same end result: a replica which is part of the in-sync replica set misses an operation that is about to be acknowledged. In order to avoid violating the invariant, the primary sends a message to the master requesting that the problematic shard be removed from the in-sync replica set. Only once removal of the shard has been acknowledged by the master does the primary acknowledge the operation. Note that the master will also instruct another node to start building a new shard copy in order to restore the system to a healthy state.
-
レプリケーションでの失敗
- プライマリへのオペレーションには成功したが、レプリカへの伝送に失敗するケース。
- 不整合を避けるため、プライマリは問題のレプリカを in-sync から外すようマスターにメッセージを送る。
-
再構築
- マスターは外されたレプリカを別ノードで再作成し、クラスタの状態を正常化する。
While forwarding an operation to the replicas, the primary will use the replicas to validate that it is still the active primary. If the primary has been isolated due to a network partition (or a long GC) it may continue to process incoming indexing operations before realising that it has been demoted. Operations that come from a stale primary will be rejected by the replicas. When the primary receives a response from the replica rejecting its request because it is no longer the primary then it will reach out to the master and will learn that it has been replaced. The operation is then routed to the new primary.
-
孤立したプライマリ
- ネットワーク断でプライマリが孤立し降格するも、自分がプライマリだと誤認し続ける可能性がある。
-
レプリカによる拒否
- レプリカは最新のクラスタステートを把握しているため、古いプライマリからのリクエストを拒否する。
- これによって孤立したプライマリはマスターの状態を確認し、新たなプライマリに書き込みを委譲する。
What happens if there are no replicas?
This is a valid scenario that can happen due to index configuration or simply because all the replicas have failed. In that case the primary is processing operations without any external validation, which may seem problematic. On the other hand, the primary cannot fail other shards on its own but request the master to do so on its behalf. This means that the master knows that the primary is the only single good copy. We are therefore guaranteed that the master will not promote any other (out-of-date) shard copy to be a new primary and that any operation indexed into the primary will not be lost. Of course, since at that point we are running with only single copy of the data, physical hardware issues can cause data loss. See Active shards for some mitigation options.
-
レプリカがない場合
- 設定でレプリカ数を 0 にしたり、全レプリケーションが失敗したりするとプライマリのみが動作する形になる。
- マスターは「プライマリが唯一の正しいコピー」とみなす。
-
データロストのリスク
- 物理障害でそのプライマリが消失すると復旧が困難になる。
基本的な読み取りモデル(Basic read model)
Reads in Elasticsearch can be very lightweight lookups by ID or a heavy search request with complex aggregations that take non-trivial CPU power. One of the beauties of the primary-backup model is that it keeps all shard copies identical (with the exception of in-flight operations). As such, a single in-sync copy is sufficient to serve read requests.
-
読み取りの種類
- Elasticsearch の読取は ID 指定の簡単なものから、大規模集計を含む複雑なクエリまで幅広い。
-
Primary-Backup のメリット
- プライマリとレプリカが同一データを保持しているため、どのコピーからも同じ検索結果が得られる(レプリケーション実行中の操作を除く)。
- そのため、in-sync コピーが一つだけあれば十分に読み取り可能である。
When a read request is received by a node, that node is responsible for forwarding it to the nodes that hold the relevant shards, collating the responses, and responding to the client. We call that node the coordinating node for that request. The basic flow is as follows:
- Resolve the read requests to the relevant shards. Note that since most searches will be sent to one or more indices, they typically need to read from multiple shards, each representing a different subset of the data.
- Select an active copy of each relevant shard, from the shard replication group. This can be either the primary or a replica. By default, Elasticsearch uses adaptive replica selection to select the shard copies.
- Send shard level read requests to the selected copies.
- Combine the results and respond. Note that in the case of get by ID look up, only one shard is relevant and this step can be skipped.
-
リクエスト受付とコーディネーティングノード
- クライアントからの読み取りリクエストを最初に受け取ったノードが、該当するシャードへの問い合わせ・結果の集約・クライアントへの返却を一手に引き受ける。
- このノードをコーディネーティングノードと呼ぶ。コーディネーティングノードのとるフローは以下の通り:
-
対象シャードの特定
- 受け取った読み取りリクエストが、具体的にどのシャードに対して実行されるべきかを決定する。
- 多くの検索では複数シャードからデータを取得する必要がある。
-
アクティブコピーの選択
- それぞれのシャードに対して、プライマリまたはレプリカのうち現在「アクティブなコピー」を選択する。
- デフォルトでは Adaptive Replica Selection (ARS) が用いられ、負荷や応答速度が考慮されて「最も速く処理できるシャードコピー」が選ばれる。
-
シャード単位の読み取り要求送信
- コーディネーティングノードは、選択したコピーに対して並行的に検索リクエストを送る。
-
結果の集約と応答
- 各シャードからの検索結果を受け取り、集約して返却する。
- なお、ID 指定の単純なリクエストの場合は対象となるシャードが 1 つだけなので、結果の集約ステップを省略できる。
シャード障害(Shard failures)
When a shard fails to respond to a read request, the coordinating node sends the request to another shard copy in the same replication group. Repeated failures can result in no available shard copies.
-
読み取り失敗時のリトライ
- あるシャードが応答しない場合、コーディネーティングノードは同じレプリケーショングループ内の別コピーにリクエストを送る。
- 全コピーへのリクエスト失敗時にはデータ取得不能になる。
To ensure fast responses, the following APIs will respond with partial results if one or more shards fail:
Responses containing partial results still provide a
200 OKHTTP status code. Shard failures are indicated by thetimed_outand_shardsfields of the response header.
-
Partial results
- 大規模検索で一部シャードが失敗しても、残りの結果を返すことで応答速度が確保される。
- レスポンスコードは 200 だが
_shardsなどに失敗情報が含まれる。
いくつかの単純な含意(A few simple implications)
Each of these basic flows determines how Elasticsearch behaves as a system for both reads and writes. Furthermore, since read and write requests can be executed concurrently, these two basic flows interact with each other. This has a few inherent implications:
-
読み取りと書き込みの相互作用
- Elasticsearch は複数の書込み・読み込みが同時に実行されるため、それぞれのフローが干渉し合う。
-
本節の趣旨
- 書き込み / 読み込みが絡み合ったときに生じる挙動をまとめる。
Efficient reads
Under normal operation each read operation is performed once for each relevant replication group. Only under failure conditions do multiple copies of the same shard execute the same search.
-
効率的な読み取り
- 正常時には各レプリケーショングループにつき 1 回ずつ読み取りクエリが走るのみ。
- 障害時のみ、同じシャードを持つ別レプリカが同じ検索を引き継ぐ。
Read unacknowledged
Since the primary first indexes locally and then replicates the request, it is possible for a concurrent read to already see the change before it has been acknowledged.
-
未 ACK の読み取り
- プライマリがローカルに書き込んだ直後にクエリが走ると、まだ ACK が返っていないのに最新のデータが読み取られる可能性がある。
Two copies by default
This model can be fault tolerant while maintaining only two copies of the data. This is in contrast to quorum-based system where the minimum number of copies for fault tolerance is 3.
-
デフォルト 2 コピー
- Primary-Backup モデルではプライマリ +1 レプリカ (合計 2 コピー) でも可用性を確保しやすい。
- これは、クォーラムモデルで可用性確保のためにコピーが最小 3 つ必要なのと対照的である。
障害時の挙動(Failures)
Under failures, the following is possible:
-
障害時のまとめ
- 障害時には以下が起こりうる:
A single shard can slow down indexing
Because the primary waits for all replicas in the in-sync copies set during each operation, a single slow shard can slow down the entire replication group. This is the price we pay for the read efficiency mentioned above. Of course a single slow shard will also slow down unlucky searches that have been routed to it.
-
単一のシャードがインデクシングを遅延させうる
- プライマリが in-sync コピー全体の応答を待つため、1 つのレプリケーションが遅いと全体が遅延する。これは上で述べた「効率的な読み取り」の代償だ。
- 検索時にも遅延シャードが存在すると、検索結果の集約が遅くなる可能性がある。
Dirty reads
An isolated primary can expose writes that will not be acknowledged. This is caused by the fact that an isolated primary will only realize that it is isolated once it sends requests to its replicas or when reaching out to the master. At that point the operation is already indexed into the primary and can be read by a concurrent read. Elasticsearch mitigates this risk by pinging the master every second (by default) and rejecting indexing operations if no master is known.
-
ダーティリード
- ネットワーク分断などでプライマリが孤立するも、自分をプライマリだと誤認し続け自身へのインデクシングを済ませると、プライマリはレプリカに複製されていない未 ACK のデータを読み取りリクエストに返してしまうことがありうる(ダーティリード)。
- Elasticsearch は、プライマリからマスターへの定期通信が途切れた場合、書き込みを拒否する機構でリスクを軽減している。
以上は氷山の一角にすぎない(The Tip of the Iceberg)
This document provides a high level overview of how Elasticsearch deals with data. Of course, there is much more going on under the hood. Things like primary terms, cluster state publishing, and master election all play a role in keeping this system behaving correctly. This document also doesn’t cover known and important bugs (both closed and open). We recognize that GitHub is hard to keep up with. To help people stay on top of those, we maintain a dedicated resiliency page on our website. We strongly advise reading it.
-
さらに深い仕組み
- プライマリタームやマスター選挙、クラスタステートなど、多くの要素がレプリケーションを下支えしている。
-
バグや既知の課題
- GitHub イシューを追うのは大変だが、公式のレジリエンシーページを追うことで、最新情報や修正内容を把握可能である。
おわりに
いかがでしたでしょうか?
「基本的な書き込みモデル」の元記事の図があまりにも分かりやすくて雄弁でした。
ちなみに、文中でも言及されているクォーラムモデルというのは、Elasticsearch のレプリケーションの Primary-Backup モデルとおおよそ次のように仕組みが異なるようです:
- Primary-Backup モデル
- 単一のプライマリがすべての書き込みを一手に受ける。
- プライマリが書き込みをローカルに適用 → レプリカへ複製。
- 全レプリカが応答したら「書き込み成功」となる。
- クォーラムモデル
- 任意のノードが書き込みを受け取る。
- 多数派のノードが「書き込みを受理した」ことを確認できれば書き込み成功 (クォーラム合意)。
比喩的に、Primary-Backup モデルはプライマリのリーダー制、クォーラムモデルはリーダーレスの民主主義と言えるかもしれません。
また、クォーラムとは「多数決」よりも抽象度の高い概念であるとこの記事で述べられていました。
まだまだレプリケーションの仕組みは奥が深そうですが、今回の記事が理解を深める一助になれば幸いです。
最後までお読みいただき、ありがとうございました!