まずは前回の記事ですが、意外にも多くの閲覧といいねを頂きまして、
大変感謝するとともに、震えております
今回から、具体的にどんなコードを書いたかを簡略に記事にしていきます。
競馬データといっても大きく分けてレース全体の情報とそのレースに出走した馬の情報があります。
いきなり目的の部分だけを切り抜かず、おおきなくくりで一度みてみる。.textなどもまだつけない
例えば以下のページの場合
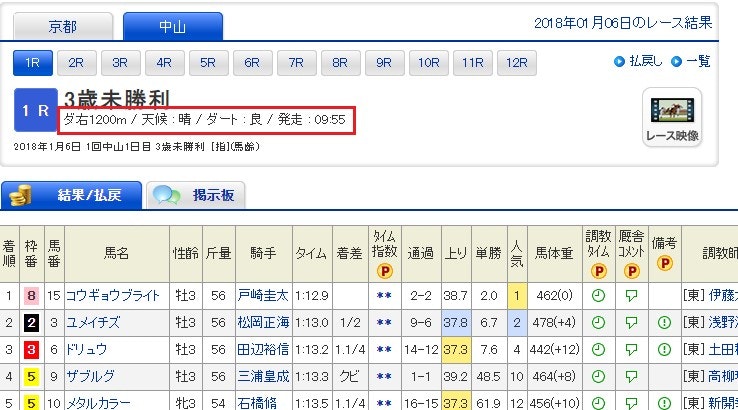
(netkeiba.com様より)
赤枠の部分にコースの種類、走行距離、馬場状態が書いてあるので、取得したいとします。
beautifulsuopを用いてもってくるとすると
from bs4 import BeautifulSoup
id = '201806010101'#データ取得したいレースID
url = ('https://db.netkeiba.com/race/%s/' % (id))
response = request.urlopen(url)
bs = BeautifulSoup(response, 'html.parser')
raceinfo = bs.select("span")[6]
print(raceinfo)
# <span>ダ右1200m / 天候 : 晴 / ダート : 良 / 発走 : 09:55</span>
となるので、ここで初めて.textとか.splitとかをつける
import re
racetype = raceinfo.text.split()[0][:1]
length = re.sub("\\D", "", raceinfo.text.split()[0])
conde = raceinfo.text.split()[8]
print(racetype,length,conde)
# ダ 1200 良
目的の情報である、コースの種類、走行距離、馬場状態を取得できました。
こうするメリットは、ループさせる際に最初の大きなくくりの部分に変数を使えば他は
そのままでもスムーズにデータ取得できること、リストの数字のアタリがつけやすいことでしょうか。
他のレースの情報や、馬毎の情報も同じ要領で取得すれば良いでしょう。
あと、過去10年ものデータを一度にスクレイピングするのはやめたほうが良いです。
何回かにわけて、データが揃ったら.concatとか.appendとかでくっつける。
1年毎にやると良い感じ(寝る時や出勤時にRUNさせると、大体タイムアウトしてますので…)
また取得した時点で何かしら計算を加えたものを保存したくなりますが、後にしましょう。ただでさえ時間がかかる作業なので…
以上のような流れでレースと馬のデータをわけて取得しました。
今回は短めですが、情報を取ってくるだけですし特別なことはしていませんので、これくらいで。
次はデータの整理、レースや馬の評価の仕方について書こうと思ってます。
次の記事からはどうしても競馬用語が多めになりますが、出来るだけ解説していきます。