はじめに
ハッカソンのきっかけで、ローカルLLMを用いた開発に挑戦することになった。デプロイを考えてDockerコンテナ化もしようとした。
目次
- 初めてのローカルLLM
- Dockerコンテナ内にLLMを実行
1. 初めてのローカルLLM
コマンドラインからオープンソースLLMを実行できるollamaという非常に便利なフレームワークがある。ここからダウンロードできる。以下はmac上での実行例。
インストールした後、コマンドラインに ollama serve を書くとlocalhost:11434でサーバーが立ち上がったよのログとAPIの色んなHTTPリクエストに関する情報が表示される。以下はHTTPリクエスト一覧の部分。
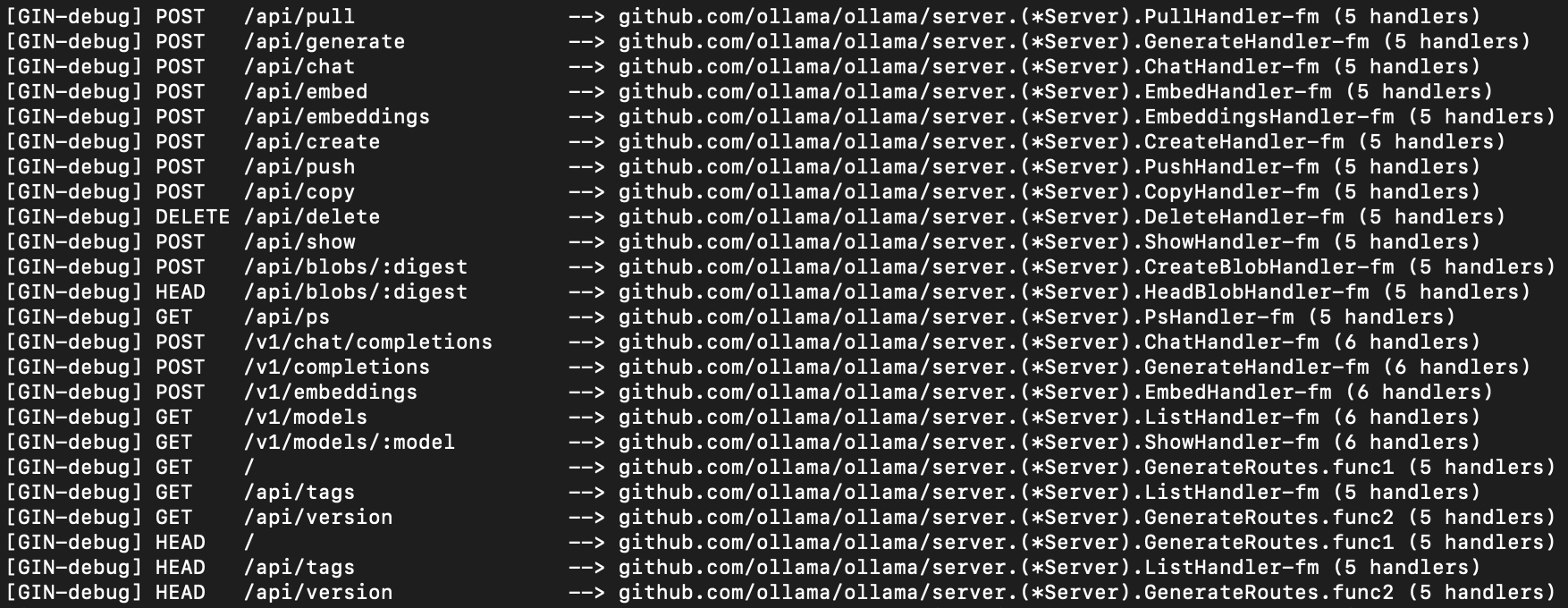
localhost:11434に行くと「Ollama is running」が表示されて、ちゃんと実行できていることを確認できる。
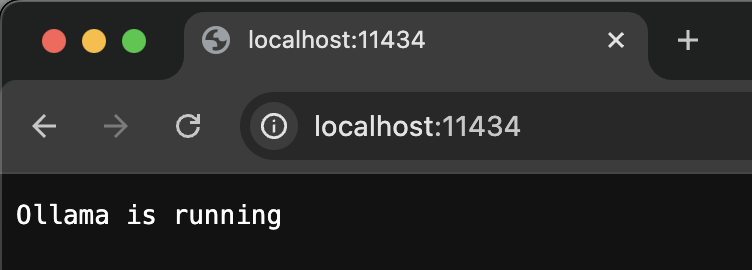
APIの試しとしてlocalhost:11434/api/versionを打つと、GETリクエストが送られて、バージョンが記載してあるリスポンスが帰ってくる。
これはターミナルにollama --versionを書くことに相当する

実行できていることを確認したので、LLMをインストールしてみよう。Ollamaのモデル一覧から好きなモデルを探してモデル名をコピーする。そしてターミナルにollama pull モデル名と書いてダウンロードが開始する。ollama listでダウンロード済みのモデルが確認できる。
ダウンロード終わったあと、ollama run モデル名でモデルを実行できる。なおインストールされていないモデルを実行しようとすると勝手にダウンロードしてくれるので、すぐに実行したいならollama run モデル名だけで良い。
今回はGoogleのGemmaの日本語の文章にファインチューニングされたschroneko/gemma-2-2b-jpn-itを利用することにした。モデルの詳細はこちら。
ターミナルにollama run schroneko/gemma-2-2b-jpn-itを書くと、Pythonの対話モードのように>>>の記号が表示されて、対話が開始される。システムプロンプトがすでに設定されているが/set system "お好きなプロンプト"で再設定できる。他のコマンドはこちら。

これでローカルLLMを実行できた!
これからは対話ができるし、開発しているアプリからHTTPリクエストでモデルを活用できる。PostmanやHTTPieなどで色んなリクエストを試すとよい。だが、リスポンスのjsonの解釈が複雑になってくるのでLangchainの利用をおすすめする。
2. Dockerコンテナ内にLLMを実行してみた
このLLMをアプリに使う目的だったけど、アプリもコンテナ化するつもりで、LLMもコンテナ化しないといけないことになった。ネットに調べたらモデルのファイルが~/.ollama/modelsに保存されていることが分かった(macの場合)。けど、そのディレクトリにblobsとmanifestというディレクトリがあってモデルのデータそこにわかれているしファイル名がハッシュになっていた。コンテナ起動の際に~/.ollamaの中身丸ごとをコンテナのroot/.ollamaにコピーしてもいい気もしたけど他のモデルも入っていたので重すぎた。
ハッカソン中で時間に追われていたので、普通にDocker Desktopでコンテナのターミナルからollamaとモデルをインストールしちゃった。
そうして普通に実行できたけど、動作が非常に遅かった。対話しようとしたら、LLMの回答がリアルタイムに生成されるはずのに、30秒ごとに一トーケンのペースで出力されていたし、回答が全然間違っていた。
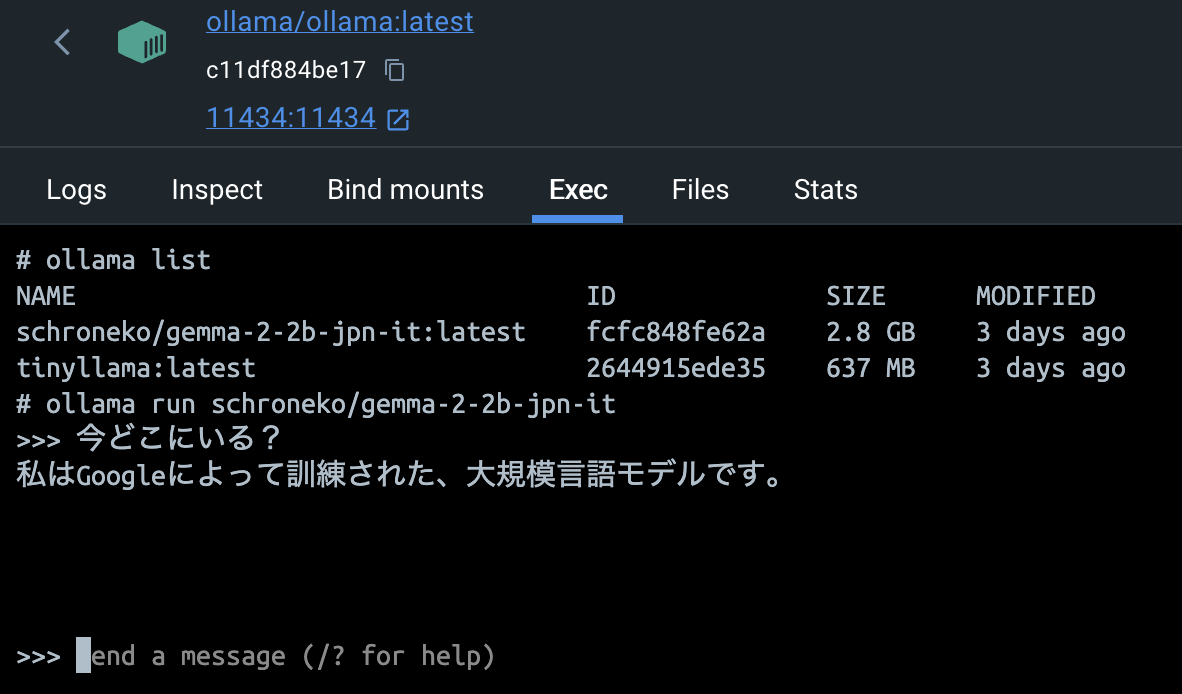
これのせいで実装方法の実用性を考えなおすことになった。ハッカソン中にはさすがにLLMのコンテナ化を諦めたが、今度コンテナのリソースを調整して、再挑戦したいと思っている。
終わりに
Gemmaをファインチューニングしたschronekoさんに感謝