テキスト
WSL Ubuntuの起動ができない
Power Shellの管理者モードで何かを実行する。エラーメッセージを見て検索すれば、わかるはずです。
Ubuntuマシンをバックアップ・リストアしたい
WSLのバックアップを検討する - concerti.tsukubaのブログ
- tarコマンドの最後のスラッシュを忘れないこと。
- Google Drive File Streamには保存できない(Ubuntuから見えない)
以下のようなシェルスクリプトを作っておくと、いつでもバックアップできる:
date=`date "+%Y%m%d"`
sudo tar -cvpjf "/mnt/c/bkup/WSL/$date/backup.tar.bz2" -X /mnt/c/bkup/WSL/exclude_list.txt /
objdumpできない
$ objdump -d -M intel /bin/ls
Command 'objdump' not found, but can be installed with:
sudo apt install binutils
言われたとおり$ sudo apt install binutilsする。
Visual Studio CodeをUbuntuにインストールする
まず、WindowsにX Serverをインストールする
「X410」というアプリがWindows Storeにあります。まったく設定が要らないのがウリ。よくセールしているようです。
次にVSCをインストールする
Visual Studio Code for Linux を WSL 上の Ubuntu 16.04 LTS にインストールする - 451 Unavailable For Legal Reasons
VSCの起動以外に日本語化とかいろいろ書いてある。とりあえず以下のことをするとWindowsから日本語文字列をコピペできるようになる。
$ sudo apt install -y language-pack-ja
$ sudo apt install -y fonts-noto-cjk
日本語入力はめんどくさそうなので私はパス。
export LANG="ja_JP.UTF-8"
以下は.bashrcに追記しておく:
export DISPLAY=":0.0"
ちなみにControl + ` でコマンドプロンプトを表示できる(右下)。
コマンドプロンプトは最初はもたつくが、「レンダリング方法を変えますか?」とか聞かれるのでYesと答えるとスムーズに動くようになる。
-
*.cファイルを保存すると勝手に「C/C++エクステンションをインストールしますか?」と聞いてくるので入れる。普通のエクステンションとインテリセンスがある。 -
*.sファイルを保存するといろいろエクステンションを提案してくるので、x86 and x86-64 Assemblyを入れる。 - 日本語の入力は面倒くさそう。
viならWindowsの入力システムが使えるので、簡単に入力できる。
フォントサイズを変更する
デフォルトのエディタのフォントサイズは小さいので、大きくする:
引数を処理するコードが理解できない
賢い方々に教えていただきました(ありがとうございました)。
Cのポインタとアセンブリの対応関係、およびポインタを使うメリット - Qiita
それでもstrtol関数がよくわからないので考えてみました。
現時点のコンパイラに食わせる引数が12+34だとします。コンパイラが以下のようにメモリに格納したとします。
| -57番地 | -58番地 | -59番地 | -60番地 | -61番地 | -62番地 |
|---|---|---|---|---|---|
| 1 | 2 | + | 3 | 4 | \0 |
char *p = argv[1];
コンパイラが*Pを-12番地に格納したとします:
| -12番地 |
|---|
| -57番地 |
最初の1字は以下のように処理するのでした:
printf(" mov rax, %ld\n", strtol(p, &p, 10));
strtol関数が出てきました。
書式
long strtol(const char *s, char **endp, int base);
パラメータの型と説明
| パラメータ | 説明 |
|---|---|
| const char *s | 変換する文字列 |
| char **endp | 変換終了位置 |
| int base | 基数 |
少し悩んだのですがstrtolは1字だけではなく2字以上の文字列でも処理できるんですね。しかも&p、ここでは**-12番地(*p)**、も更新してくれる。高機能!
atol関数は、単に文字列を10進のlong型変数に変換するのみで、文字列中に変換不可能な文字があった ときには対応できませんが、strtolを使うと、変換可能な部分についてはきちんと変換し、文字列中に変換不可能な文字があった場合には、その文字列のポインタをendptrに格納します。
もう一度、本のコードを見てみましょう:
printf(" mov rax, %ld\n", strtol(p, &p, 10));
| -12番地 |
|---|
| -57番地 |
| -57番地 | -58番地 | -59番地 | -60番地 | -61番地 | -62番地 |
|---|---|---|---|---|---|
| 1 | 2 | + | 3 | 4 | \0 |
-
p(変換する文字列の先頭のアドレス)は**-57番地(p)**の1です - 数字なので
pを1つ進めて**-58番地(p)**にセットして次へ進みます - 次の番地(-58番地)は
2です - 数字なので
pを1つ進めて**-59番地(p)**にセットして次へ進みます - ここまでで文字列
12を読み込みました - 次の番地(-59番地)は
+です - 数字ではないので読み込みを止めます
- このとき
&p(変換終了位置)は-59番地です - 関数はint型の
12を返します
なお、基数は10なので、数字は10進数で解釈します
ここで以下のコードを実行すると、char型だった1と2がint型の12になります。そして、以下のようなアセンブリを出力します:
mov rax, 12
わざわざint型に変換したのには深い理由があるのでしょう。
| -12番地 |
|---|
| -59番地 |
これによってpは-59番地の+になります。
| -57番地 | -58番地 | -59番地 | -60番地 | -61番地 | -62番地 |
|---|---|---|---|---|---|
| 1 | 2 | + | 3 | 4 | \0 |
それから、以下のようなループに入ります:
while(*p) {
if (*p == '+') { // 第1引数の途中で「+」が出てきたら、
p++; // pを1増やして、
// 該当するアセンブリを出力します
printf(" add rax, %ld\n", strtol(p, &p, 10));
continue;
}
... // 繰り返す処理
}
具体的には以下のようなプロセスになります:
p++;
**-12番地(*p)**の「-59番地」を1増やします:
| -12番地 |
|---|
| -60番地 |
これによってpは-60番地の3になります。
| -57番地 | -58番地 | -59番地 | -60番地 | -61番地 | -62番地 |
|---|---|---|---|---|---|
| 1 | 2 | + | 3 | 4 | \0 |
次に…
printf(" add rax, %ld\n", strtol(p, &p, 10));
これによって以下のようなアセンブリが出力されます:
add rax, 34
そして最終的に*pは\0を指し、ループは終了します。
まとめると、以下のようなアセンブリが出力されました:
mov rax, 12
add rax, 34
うーん、難しかった…
gccできない
$ sudo apt install build-essential
git pushできない
まず、リモートリポジトリを削除する。これには以下のようにする(たぶんこれをしないとssh鍵生成などのめんどくさいことをする羽目になる):
$ git remote remove origin
あとは以下のページの通り:
ローカルでgitを使用した後、gitHubに登録する方法 - Qiita
VSCでgit管理
ちなみに一度gitの設定をしておくと、あとはVSC上からadd、commit、pushなどのgit操作ができる(他のコマンドもひと通りできる。branchを切ったりmergeしたりもできる。詳しくは下記リンクを参照)。
Visual Studio Code の git 連携機能と git コマンドについて (2018/05/23) - Qiita
さらにGit Historyというエクステンションを入れておくと、コミットログを見ることができる。
Git History - Visual Studio Marketplace
View -> Command Palette で「git history」と入力すれば良い。
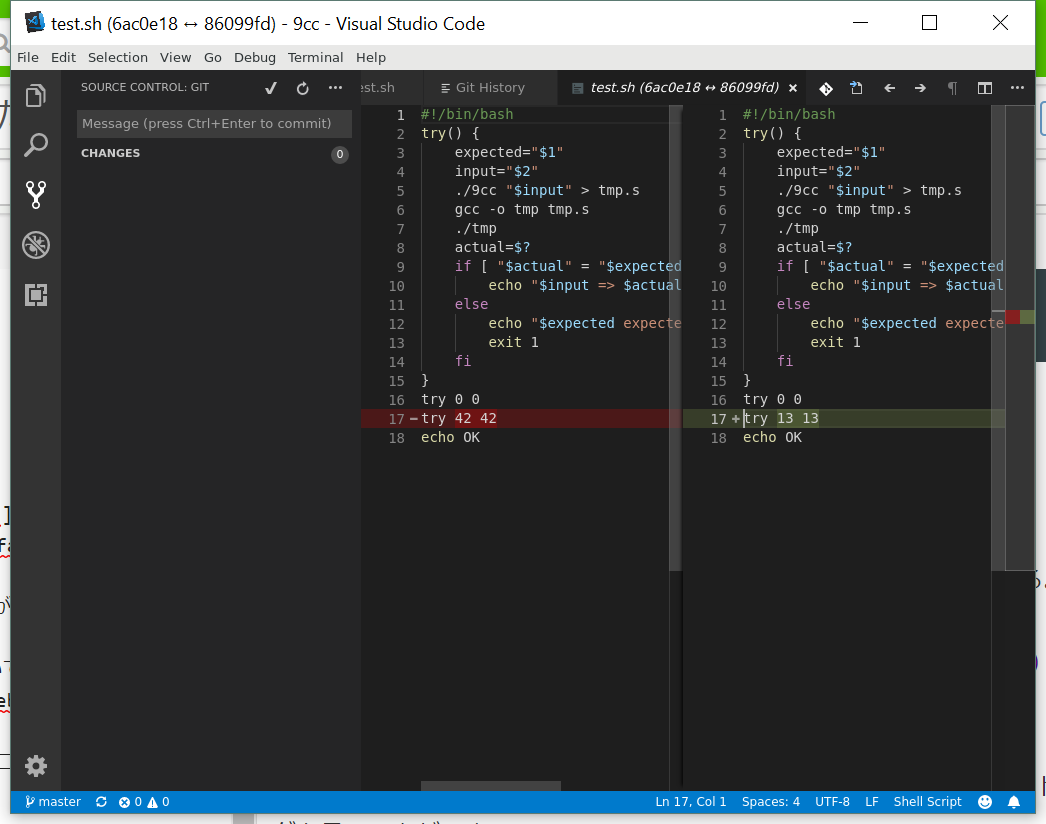
ファイルのdiffも見ることができる。
抽象構文木のコードがわからない
まず、以下の部分は間違っています:
Node *node = malloc(sizeof(Node))
最後に;を付けましょう。
malloc、ヒープメモリ
さて、このmallocという関数、何をしているのでしょう?
ヒープメモリから size バイトのブロックを割り当てます
ヒープメモリ?
例えば、ファイルを読み出す際、ファイルのサイズは毎回同じとは限らないので、ファイルサイズ分だけメモリをヒープに確保すれば、無駄にメモリを消費することはないよね。
これをスタックで実現しようとすれば、ファイルサイズが最も大きくなる場合を想定しておかなければならない。
スタックは少なくすればスタックオーバーフローの危険性があるし、大きくすれば無駄に使われないメモリが存在することになるよね。スタックサイズの調節は、限られたメモリを最大限有効に使うための、プログラマーの腕の見せ所だ。
ヒープとスタック | 学校では教えてくれないこと | [技術コラム集]組込みの門 | ユークエスト株式会社
なるほど、入力するデータ(プログラムコード)は小さいことも極端に大きいこともあるので、極端に大きいデータ(極端に長いコード)だとスタックメモリがあふれてしまうことがある。ということですね。
ちなみに、mallocの戻り値は以下のようになっています
成功時 : 確保したメモリブロックを指すポインタ
失敗時 : NULL (メモリ不足により指定サイズ分のメモリが確保できないとき)
それでもmalloc、ヒープがわからない
賢い方にとても良く理解できる方法を教えてもらいました。
mallocでメモリを確保して操作する様子を、ヒープを直に見ることで、観察する(Visual Studio 2017を使って) - Qiita
(次はフィボナッチ数列の予定)