本記事について
2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)でGatysらによって発表された画像スタイル変換の論文「Image Style Transfer Using Convolutional Neural Networks」について内容の要約と実装(tensorflow2.1)を行った。
ソースコードはhttps://github.com/FaunieMuskie/ImageStyleTransfer にも。
論文概要
本論文はニューラルネットワークによる画像スタイル変換の草分け的存在である。
本論文以前にも画像スタイルの変換、すなわち画像のテクスチャのみを転送する問題については考えられていたが、既存の手法はターゲット画像から低次元の画像特徴量を抽出するものであり、ターゲット画像の持つ意味的なコンテンツ(オブジェクトや風景)を抽出することができないという限界があった(例えばターゲット画像の粗いスケールを維持しながら高周波のテクスチャ情報を変換するアプローチ等が存在した)。
本論文は、高レベルの画像の意味抽出を行えるCNNを用いて、画像のコンテンツとスタイルを分けてモデル化した画像スタイル変換を初めて行ったものである。

手法と実装
この論文の主旨を簡単にまとめると、学習済みのVGG19を画像の特徴量抽出に用いて、入力画像のコンテンツ特徴量・スタイル特徴量が、それぞれ変換元コンテンツ画像のコンテンツ特徴量と、変換先スタイル画像のスタイル特徴量の両方に近づくように入力画像を学習することで、元のコンテンツ画像のコンテンツを保ったまま変換先スタイル画像のスタイルを持った画像を生成する、ということである。
アーキテクチャ
モデルのアーキテクチャは以下のようになる。
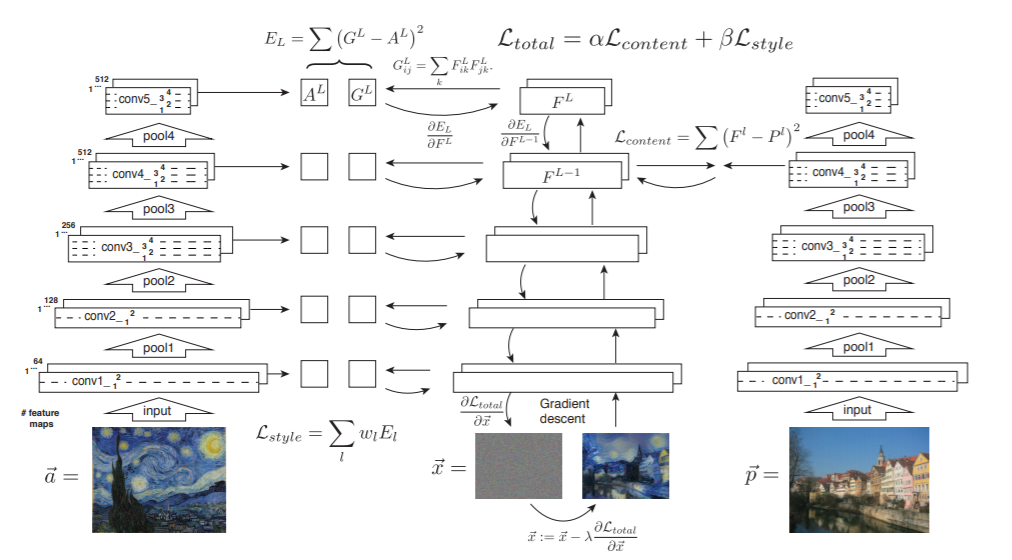
左の列はスタイル画像がVGG19に入力され各層($l=1..L$)でスタイル特徴量$A^l$が抽出される様子を表している。また、右の列はコンテンツ画像がVGG19に入力されある1層でコンテンツ特徴量$P^l$が抽出される様子を表している。そして、中央の列は入力画像がVGG19に入力されある層でコンテンツ特徴量$F^l$と各層でスタイル特徴量$G^l$が抽出され、コンテンツ画像のコンテンツ特徴量との2乗誤差と、スタイル画像のスタイル特徴量との2乗誤差を損失関数として、誤差逆伝搬法により入力画像が更新される様子を表している。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.applications.vgg19 import VGG19
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.vgg19 import preprocess_input
from tensorflow.keras.models import Model
from tensorflow.keras import losses
import numpy as np
import matplotlib.pyplot as plt
model = VGG19(weights='imagenet', include_top=False)
特徴量抽出
$l$層のコンテンツ特徴量$F^l$は、単純に入力に対する$l$層の出力から得られる。ただ、$l$層の出力は(特徴マップの高さ$H$)×(特徴マップの幅$W$)×(フィルタの数$N^l$)で出力されるので、(フィルタの数$N^l$)×(特徴マップのサイズ$M^l(=H・W)$)の2次元にしたものが$F^l$である。
一方、スタイル特徴量$G^l$は$F^L$のグラム行列で得られる。
$$ G^l_{ij} = \sum_{k} F^l_{ik} F^l_{jk}$$
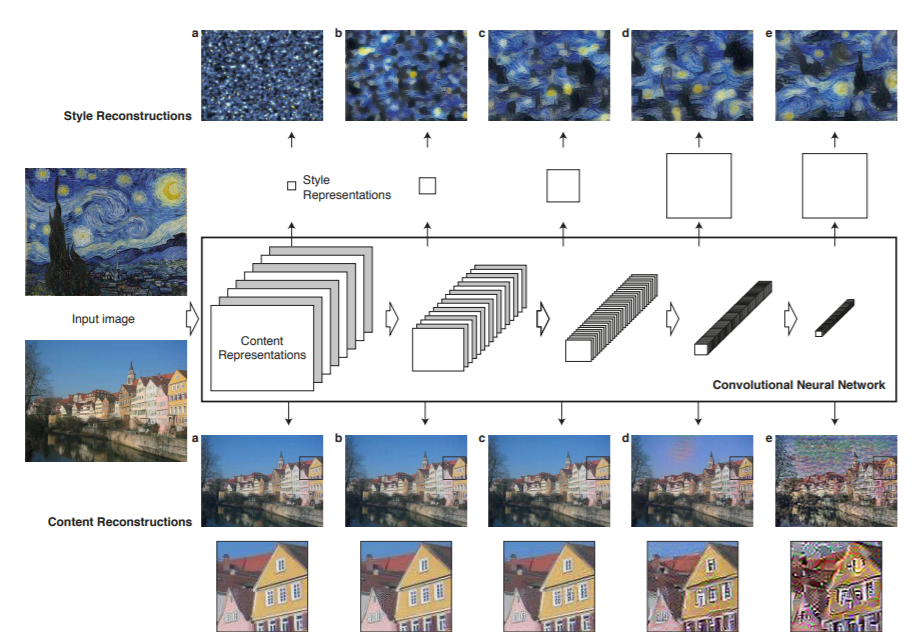
実際にこれらの特徴量の表現がどのようなものかを表したものが以下の図であり、コンテンツの特徴が高いレイヤーでも表現されていることや、層の深さによってスタイルの異なる特徴が表現されていることが分かる。
outputs_dict = dict([(layer.name, layer.output) for layer in model.layers])
feature_extractor = Model(inputs=model.inputs, outputs=outputs_dict)
def reshape_f(x):
x=tf.reshape(x,[tf.shape(x)[0]*tf.shape(x)[1],tf.shape(x)[2]])
x=tf.transpose(x)
return x
def make_con_feature(tef,layer):
con_feature=feature_extractor(tef)[layer][0,:,:,:]
con_feature=reshape_f(con_feature)
return con_feature
def make_st_feature(tef,layer):
matrix=make_con_feature(tef,layer)
st_feature = tf.matmul(matrix, matrix, transpose_b=True)
return st_feature
損失関数
コンテンツの損失関数$L_{content}$は
$$ L_{content} = \frac{1}{2} \sum_{i,j} (F^l_{ij}-P^l_{ij})$$
スタイルの損失関数$L_{style}$は、あるレイヤーでの損失
$$ E_l = \frac{1}{4N^2_lM^2_l} \sum_{i,j} (G^l_{ij}-A^l_{ij})$$
を重み$w_l$で足し合わせて
$$ L_{style} = \sum^L_{l=0} w_l E_l $$
とする。
トータルでの損失関数はそれぞれに係数$\alpha,\beta$をかけて足した、
$$ L_{total} = \alpha L_{content} + \beta L_{style}$$
とする。
def con_loss(con_feature,gen_con_feature):
nu = tf.reduce_sum(tf.square(con_feature - gen_con_feature))
de = tf.constant(2.0)
return tf.divide(nu,de)
def single_style_loss(st_feature,gen_st_feature,M):
nu=tf.reduce_sum(tf.square(st_feature - gen_st_feature))
de= tf.constant(4.0) * tf.cast(tf.square(tf.shape(st_feature)[0]),tf.float32) * tf.cast(M,tf.float32) # tf.cast(tf.square(M),tf.float32)にするとMが大きいとき動かないのでMを2回に分けて割った
return tf.divide(tf.divide(nu,de),tf.cast(M,tf.float32))
def style_loss(st_tf,gen_tf):
st_loss=tf.zeros(shape=())
for layer in st_layers:
st_feature=make_st_feature(st_tf,layer)
gen_st_feature=make_st_feature(gen_tf,layer)
M=tf.shape(make_con_feature(st_tf,layer))[1]
st_loss=st_loss+single_style_loss(st_feature,gen_st_feature,M)/len(st_layers)
return st_loss
def total_loss(gen_tf,a,b):
con_feature=make_con_feature(con_tf,con_layer)
gen_con_feature=make_con_feature(gen_tf,con_layer)
cl=con_loss(con_feature,gen_con_feature)
sl=style_loss(st_tf,gen_tf)
return a*cl+b*sl
勾配計算
通常の機械学習と異なり、重みではなく入力に対する損失関数の勾配を求める。
@tf.function
def grad_and_loss(gen_tf):
with tf.GradientTape() as tape:
loss=total_loss(gen_tf,con_weight,st_weight)
grad = tape.gradient(loss, gen_tf)
return grad,loss
実装結果
アーキテクチャの図では初期入力画像がホワイトノイズ画像にしているが、収束を早くするためにコンテンツ画像を初期入力に用いた。また、元論文ではmax_poolingではなくaverage_poolingを推奨し、最適化の手法はSGDではなくL-BFGSを推奨していた。
元画像


変換後

若干絵ぽくはなったが、イテレーションが足りなかったり、重みの係数の値が微妙なのかもしれない。
con_input_path = 'elephant.jpg'
st_input_path='gogh.jpg'
con_input = image.load_img(con_input_path, target_size=(224, 224))
keras.preprocessing.image.save_img('content.png', con_input)
con_input = image.img_to_array(con_input)
con_input = np.expand_dims(con_input, axis=0)
con_input = preprocess_input(con_input)
st_input = image.load_img(st_input_path, target_size=(224, 224))
plt.imshow(st_input)
keras.preprocessing.image.save_img('style.png', st_input)
st_input = image.img_to_array(st_input)
st_input = np.expand_dims(st_input, axis=0)
st_input = preprocess_input(st_input)
gen_tf=tf.Variable(gen_input)
con_tf=tf.Variable(con_input)
st_tf=tf.Variable(st_input)
con_layer='block4_conv2'
st_layers=['block1_conv1','block2_conv1','block3_conv1','block4_conv1','block5_conv1']
con_weight=1e-9
st_weight=1e-6
iterations = 1000
optimizer = keras.optimizers.SGD(
keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=100.0, decay_steps=100, decay_rate=0.96
)
)
for i in range(1, iterations + 1):
grad,loss = grad_and_loss(gen_tf)
optimizer.apply_gradients([(grad, gen_tf)])
if i% 100 == 0:
print("Iteration %d: loss=%.2f" % (i, loss))
result = gen_tf[0,:,:,:].numpy()
keras.preprocessing.image.save_img('result.png', result)
まとめ
・Image Style Transferについて論文を読み実装した。
・「Image Style Transfer Using Convolutional Neural Networks」は画像スタイル変換について初めてニューラルネットワークによるアプローチを用い、良い結果をだした。
・本論文を実装する際は、損失関数を自作し入力に対する勾配を求める必要がある。
・結果は微妙だったので、ハイパーパラメータの調節が必要かもしれない。また時間があればVGGのデフォルト入力より大きい画像に対応させたい。
期限内に記事を書いて出すため、以上。