本稿は、『Measurement』誌に掲載された論文『Thermodynamic Simulation-assisted Random Forest: Towards explainable fault diagnosis of combustion chamber components of marine diesel engines』の詳細な解説です。
1. はじめに
ディーゼルエンジンは船舶推進システムの中核を担う重要機器であり、内部構造は複雑で構成部品も多い。とりわけ燃焼室はエンジン機能にとって極めて重要であり、シリンダヘッド、シリンダライナ、ピストンなどで構成される。運転環境が苛酷であることから、燃焼室はディーゼルエンジンにおける最も脆弱な部位の一つである。燃焼室の故障はエンジン性能と安全性を損なう可能性があり、故障検出はエンジン管理において不可欠である。熱力学パラメータを監視することで、診断モデルは欠陥の識別と位置特定を行い、保全計画、修理スケジュール最適化、コスト管理に重要な情報を提供できる。しかし、故障データの不足や事前知識の非定量性などの要因により、実船運用での故障診断は依然として難しい。
現在、船舶用ディーゼルエンジンの故障診断手法は、表1に示すとおり主に3種類に分類される。すなわち、モデルベース手法、データ駆動手法、ハイブリッド手法である。モデルベース手法では、物理法則、工学知識、運転原理を統合してディーゼルエンジンの数理モデルを構築し、その後シミュレーションソフトウェアにより正常状態および故障状態での性能を評価する。しかし現状では、船舶用ディーゼルエンジンに対して高精度な物理・数理モデルを構築することは極めて困難である。この種のモデルは一般に複雑で高度な専門知識を要し、多数の変数と環境要因間の非線形性や相互作用を扱う際に課題が生じる。
データ駆動手法は、ディーゼルエンジンの詳細な物理モデリングを必要としない。代わりに、前処理済みデータを機械学習モデルに入力し、故障特性の自律学習と潜在故障の自動識別を行う。しかし、データ駆動モデルは明示的な物理法則ではなくデータから特徴を学習するため、その意思決定原理の解釈は難しい。特に深層学習のような複雑モデルでは、非線形関係や高次元特徴の相互作用により「ブラックボックス化」し、判定理由の説明が困難になりやすい。
ハイブリッド手法は通常、物理・数理故障モデルの構築から始まり、実験データで校正を行う。診断はその後、シミュレーション出力、または実験データとシミュレーションデータの組合せに基づいて実施される。しかし、これらの手法では物理モデルとの統合時に、モデルの意思決定過程に対する詳細分析が不足している。実際には、物理モデルは主として故障シミュレーションツールおよび補助データ供給源として利用されるにとどまる。
表 1 既往研究の要約
| 手法タイプ | 長所 | 限界 |
|---|---|---|
| モデルベース手法 | 1. 物理的解釈が明確。2. 機構が十分理解されたシステムに適用可能。 | 1. 柔軟性と適応性に欠ける。2. 複雑な非線形システムへの対応が難しい。 |
| データ駆動手法 | 1. 適応性が高い。2. 大規模データ場面に適する。 | 1. データの質と量への依存が大きい。2. 説明可能性が低い。 |
| ハイブリッド手法 | 1. 比較的高精度。2. より良い解釈可能性。 | 1. モデル複雑度が高い。2. 計算コストが高い。 |
以上の課題に対し、本研究では熱力学シミュレーション支援ランダムフォレスト(TSRF)と呼ぶ燃焼室部品故障診断手法を開発した。まず、船舶用ディーゼルエンジンの一次元熱力学モデルを構築する。次に、試験データによりモデルパラメータを校正し、燃焼室部品に関する5種類の故障をシミュレーションする。計算複雑度を抑えるため、各熱力学パラメータのSHAP値を算出し、SHAP値の高いパラメータを重要パラメータとして選定する。最後に、選定パラメータを用いてランダムフォレスト(RF)で分類を行い、他の機械学習手法および特徴選択手法と比較する。評価枠組みは、SHAP値に基づく局所解釈と大域解釈の両視点を統合している。局所解釈では、詳細なウォーターフォール図分析により単一故障サンプルに寄与する重要パラメータを特定し、大域的重要度評価ではビースウォーム図により故障状態全体でのパラメータ寄与を評価する。さらに、SHAP相互作用値に基づいて、パラメータ相互作用図および依存図を提示する。本研究の主な新規性は以下のとおりである。
(1) 本研究は、シリンダヘッド亀裂(F1)、ピストン焼損(F2)、シリンダライナ摩耗(F3)、ピストンリング摩耗(F4)、ピストンリング固着(F5)を含む、船舶用ディーゼルエンジン燃焼室故障をモデル化する新たなパラメータ微調整手法を開発した。従来法は故障時の微視的材料特性を重視する傾向があり、長時間シミュレーション、複雑な手順、限られた熱力学パラメータ分析範囲と結びつくことが多い。これに対し提案法は、パラメータ微調整によって故障特性を再現し、燃焼室故障に対する迅速なシステム応答を得る。
(2) 本研究は、燃焼室故障診断のパラメータ選択に対するSHAP手法の適用性を評価し、カイ二乗検定、再帰的特徴除去(RFE)、ジニ指数を含む他の特徴選択手法と性能比較を行った。SHAP値の算出によりパラメータ重要度を定量評価し、高寄与パラメータを精密に選定した。さらに、高度な可視化技術を組み合わせることで、モデル意思決定過程を明確化し、重要パラメータが故障分類結果へ影響する具体的機構について透明性の高い知見を与えた。
(3) 本研究は、熱力学モデルの支援下でデータ駆動手法を用い、燃焼室故障診断におけるRFの意思決定過程を二重視点で解釈する新たな方法を提案した。熱力学モデルが与える機構的基盤と物理的解釈可能性を活用することで、船舶用ディーゼルエンジン燃焼室故障の説明可能診断に新たな示唆を提供する。
2. 方法論
2.1. 概要
提案する船舶用ディーゼルエンジン向けTSRF手法を図1に示す。まず、一次元熱力学モデルを構築し、データ収集モジュール(DCM)で取得したデータを用いてモデルを校正する。次に、重要なシステムパラメータを微調整して5種類の代表的な燃焼室故障シナリオを模擬し、診断に関連する可能性のある熱力学指標を抽出する。続いて、RFで予備的な故障識別を行い、さらにSHAP値を算出して診断分析に用いる最適パラメータ部分集合の選択を促進する。最終段階では、SHAP値分析と熱力学モデルからの知見を統合した多視点モデル解釈を行い、包括的な診断理解を提供する。

図 1. TSRF 構造
2.2. 船舶用ディーゼルエンジン一次元熱力学モデル
2.2.1. モデル記述
ディーゼルエンジン一次元熱力学モデルの構成を図2に示す。モデルは、システム境界(SB1, SB2)、吸排気マニホールド(PL1, PL2)、ターボチャージャ(TC1)、インタークーラ(CO1)、および6気筒(C1〜C6)から成る。加えて、重要パラメータ監視のため6つの監視点(MP1〜MP6)を設置した。配管については、配管1はコンプレッサ吸気管、配管2はインタークーラ吸気管、配管3はインタークーラ排気管を表す。配管4〜9は各気筒の吸気管、配管10〜15は各気筒の排気管に対応する。配管16はターボチャージャ入口管に接続され、配管17はターボチャージャ排気管である。ディーゼルエンジンの主要仕様を表2に示す。

図 2. ディーゼルエンジン一次元熱力学モデル
表 2. エンジン仕様
| エンジン特性 | 仕様 | エンジン特性 | 仕様 |
|---|---|---|---|
| シリンダ径 | 620 mm | 気筒数 | 6 |
| ピストン行程 | 2658 mm | 気筒配列 | 直列 |
| 回転数範囲 | 77 〜 103 rpm | 点火順序 | 1-5-3-6-2-4 |
| 平均ピストン速度 | 9.13 m/s | サイクル形式 | 二ストローク |
| 出力 | 2900 kW | 行程/シリンダ径比 | 4.29 |
2.3. 熱力学故障モデリング
本研究では、燃焼室部品の健全状態をF0〜F5の6条件に分類する。すなわち、正常状態(F0)、シリンダヘッド亀裂(F1)、ピストン焼損(F2)、シリンダライナ摩耗(F3)、ピストンリング摩耗(F4)、ピストンリング固着(F5)である。本節では、5つの故障状態(F1〜F5)に対するパラメータ微調整手法を体系的に示し、その後、各故障の劣化機構と基礎物理原理を総合的に分析する。
2.3.1. シリンダヘッド亀裂 (F1)
シリンダヘッド表面温度を微調整することで、シリンダヘッド亀裂を数値的に検討する。運転条件下では、シリンダヘッドは主として燃焼室近傍で顕著な熱機械負荷を受ける。これら重要領域における亀裂の発生・進展は構造健全性を大きく低下させ、局所的応力集中を悪化させる。さらに、亀裂形成は放熱に悪影響を及ぼし、放熱効率低下を介して局所的熱暴走を誘発する。
2.3.2. ピストン焼損 (F2)
ピストン焼損は、表面温度分布とブローバイ質量流量という2つの主要パラメータを微調整して数値的に模擬する。ピストン表面材料の漸進的劣化は顕著な熱的不均一をもたらし、局所温度上昇を引き起こす。加えて、熱焼損に伴う材料喪失はピストン・シリンダ界面の健全性を損ない、ガス漏れ経路の増加によってブローバイ現象を悪化させる。
2.3.3. シリンダライナ摩耗 (F3)
シリンダライナ摩耗のシミュレーションは、シリンダ径と対応するブローバイ質量流量特性を微調整して実現する。主たる摩耗機構は、一般に空気ろ過系の故障またはシール界面劣化に起因する粒子状汚染物の侵入である。これら摩粒子はライナ表面の漸進的な材料除去を引き起こし、測定可能な真円度偏差と局所的シリンダ径拡大として現れる。この幾何形状変化はピストン・ライナ界面のシール効率を著しく低下させ、増大したガス漏れ経路を通じてブローバイを拡大する。
2.3.4. ピストンリング摩耗 (F4)
ピストンリング摩耗のシミュレーションは、ブローバイ質量流量パラメータの制御調整によって実施する。主な摩耗機構は、シリンダアセンブリ内部に存在する摩粒子汚染物に起因し、リング表面の漸進的材料劣化を誘発する。この摩耗過程は、特にリング端面の真円度変形など、測定可能な幾何偏差を生じさせる。こうした幾何欠陥はリング・シリンダ間のシール健全性を著しく損ない、ブローバイ増大を介してブローバイ現象をさらに悪化させる正のフィードバックループを形成する。
2.3.5. ピストンリング固着 (F5)
ピストンリング固着は、シリンダ径、ライナ表面温度、ブローバイ質量流量の3つの重要パラメータを微調整して模擬する。この故障様式は主に、過剰な炭素堆積物、潤滑膜形成不足、スラッジ蓄積という3つの要因に起因し、これらがリングの正常運動を阻害してシール性能を低下させる。正常運転時、ピストンリングは重要な熱伝導体として、ピストントップからシリンダ壁への効率的な熱伝達を担う。しかしリング固着はリング・ライナ界面に顕著な熱抵抗を生じさせ、ピストン表面温度の大幅上昇を招く。さらに、この状態はリングとライナ表面間に異常摩擦相互作用を生み、摩耗加速機構および潜在的なライナ表面の引っかき損傷を引き起こす。
2.4. Tree SHAP分析に基づく熱力学パラメータ選択
本研究は、図3に示すSHAP値を用いた熱力学パラメータ選択プロセスを提案する。まず、故障シミュレーション出力から診断関連の可能性を有する熱力学パラメータを抽出し、初期データセットを構成する。次に、当該データセットをRFへ入力して予備識別を実施する。これに基づき、Tree SHAP手法によりSHAP値を算出し、各パラメータの寄与重みを定量評価する。最後に、パラメータ重要度ランキングに基づいて最適特徴部分集合を選択し、精選データセットを生成した上でRFモデルにより再解析し、診断精度を向上させる。
表 3 特徴選択手法の比較
| 手法タイプ | 計算コスト | モデル依存性 | 相互作用効果 | 非線形関係 | 解釈可能性 | 公平性 |
|---|---|---|---|---|---|---|
| カイ二乗検定 | 低 | なし | × | × | 統計的有意性 | 低 |
| RFE | 高 | ロジスティック回帰 | √ | × | モデル重み | 中 |
| ジニ指数 | 中 | ランダムフォレスト | √ | √ | 分割利得 | 中 |
| SHAP | 高 | モデル非依存 | √ | √ | 大域 + 局所寄与 | 高 |
カイ二乗検定、RFE、ジニ指数を含む従来の特徴選択法と比較して、SHAPは熱力学パラメータ重要度に対し包括的な評価枠組みを提供する。この先進手法は、重要度の定量化にとどまらず、影響方向(正/負)を明示し、パラメータ相互作用ダイナミクスを明らかにし、サンプル分布パターンを特徴付ける。こうした多面的分析は、熱力学モデリングを通じた基礎物理機構の検討と潜在的パラメータ相関の解明に強力な実証的支援を与える。SHAPベース特徴選択と従来手法の比較分析を図3に示す。
本節では、SHAP値計算を詳細に示し、ツリー構造向け改良法であるTree SHAPの中核概念と計算過程を重点的に記述する。

図 3. SHAP に基づくパラメータ選択プロセス
2.4.1. SHAP値
SHAPは、特徴選択やモデル解釈可能性向上を含む機械学習分野で広く利用されている。SHAP値計算では、寄与値の概念が、単一熱力学パラメータがモデル予測へ与える影響を表す定量指標として機能する。特定のパラメータ組合せを導入した場合(図4a)、熱力学パラメータ $i$ の限界寄与 $\Delta_{val}(i, S)$ は次式で表される。
$$ \Delta_{val}(i, S) = f(S \cup {i}) - f(S) $$ (1)
ここで、$S$ はパラメータ $i$ を除くパラメータ集合、$f(S)$ は集合 $S$ による寄与、$f(S \cup {i})$ はパラメータ $i$ 追加時の寄与である。
すべての可能なパラメータ組合せを評価した後、パラメータ $i$ の平均増分寄与(すなわちSHAP値 $\phi_i$)は以下で計算される。
$$ \phi_i = \sum_{S \subseteq N \setminus {i}} \frac{|S|!(|N|-|S|-1)!}{|N|!} \cdot \Delta_{val}(i, S) $$ (2)
ここで、$N$ は全パラメータ集合、$S$ はモデルで使用されるパラメータ部分集合、$N \setminus {i}$ は対象パラメータ $i$ を除く全ての実行可能組合せ、$p$ は部分集合 $S$ のパラメータ数を表す。
特定パラメータ組合せ $S$ の評価時、総合評価は単一パラメータSHAP値の線形加算で得られる(図4(b))。したがって、組合せ $S$ の複合SHAP値は次式で定まる。
$$ f(S) = \phi_0 + \sum_{i=1}^{M} \phi_i $$ (3)
ここで、$\phi_0$ はベースライン値(パラメータなし時のモデル平均出力)、$\sum_{i=1}^{M} \phi_i$ は各パラメータ予測SHAP値の総和である。
2.4.2. Tree SHAP
Tree SHAPは、ランダムフォレストを含むツリーベースモデル向けに開発された最適化計算手法である。この手法はツリーモデル固有の階層構造を利用し、従来SHAP値計算に比べて顕著な計算効率向上を実現する。図4(c)に示すように、従来のSHAP値計算は全ての可能なパラメータ組合せを総当たりで走査する必要があり、計算負荷が大きく、パラメータ次元増加に伴って指数的に複雑化する。
Tree SHAPアルゴリズムの本質的相違は、特定入力条件を満たす決定経路に沿ってのみ限界寄与を計算する点にある(図4dの $i_1 > 5$ 条件)。この戦略的最適化により、完全な組合せ列挙が不要となり、計算効率が大幅に向上する。決定木構造における所与のパラメータ $i$ に対するTree SHAP値は次式で計算される。
$$ \phi_i = \sum_{j=1}^{T} \sum_{S \subseteq P_j \setminus {i}} \frac{|S|!(|P_j|-|S|-1)!}{|P_j|!} \cdot \Delta_{val}(i, S) $$ (4)
ここで、$T$ はアンサンブル内決定木総数、$P_j$ は $j$ 番目の木構造内の完全決定経路集合、$P_j \setminus {i}$ は対象パラメータ $i$ を除く実行可能組合せ、$S$ はモデルで選択された特徴部分集合、$p$ はパラメータ部分集合 $S$ の基数を表す。
2.5. 分類モデル
本研究は、パラメータ選択および故障分類タスクの基盤モデルとしてRFを採用する。このアンサンブル学習手法は、サンプル数が限られた多クラス分類問題に対して高い性能を示しつつ、前処理要件を低く保てる。これらの特性により、RFは本研究の複雑な多パラメータ故障診断シナリオに特に適している。熱力学パラメータは連続値であるため、決定木入力仕様に適合する形式へ変換する離散化処理を実施した。
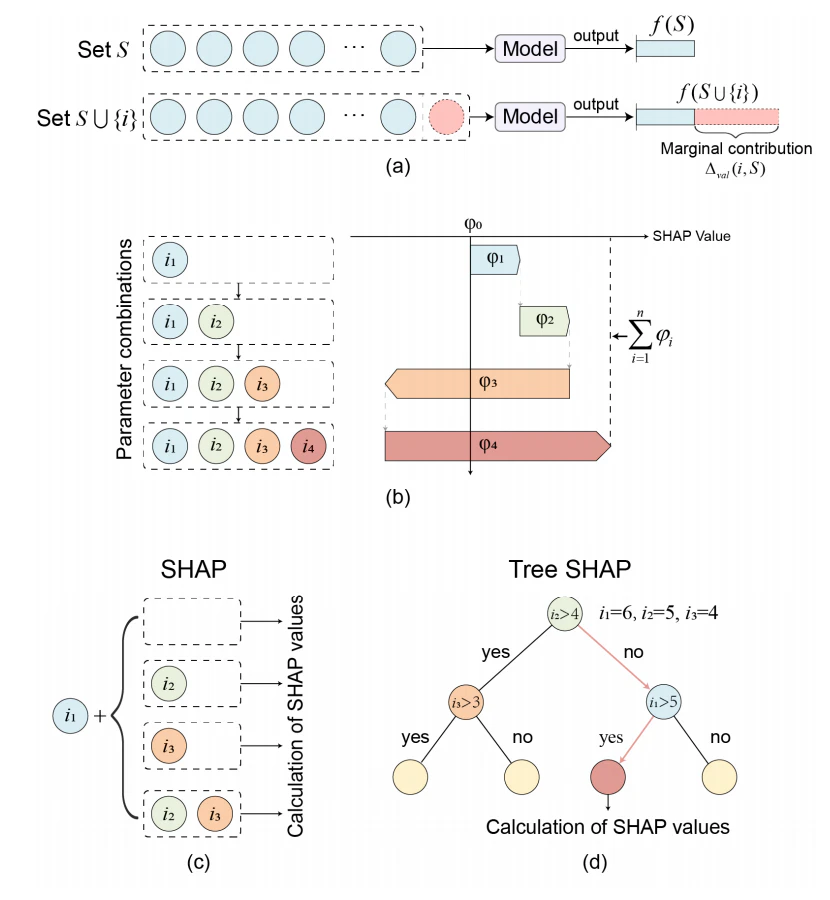
図 4. SHAP アルゴリズム詳細:(a) 限界寄与; (b) SHAP 値の加法性; (c) SHAP の計算; (d) Tree SHAP の計算
2.5.1. パラメータ離散化
RFの基本構成要素である決定木は、特徴空間の再帰的分割によって予測結果を生成する。与えられたサンプル集合 $D$ に対し、$p_k$ を第 $k$ 類($k=1,2,...,N$)に属するサンプル比率とすると、$D$ の情報エントロピーは次式で定義される。
$$ Ent(D) = -\sum_{k=1}^{N} p_k \log_2 p_k $$ (5)
離散属性 $a={a_1, a_2,...,a_N}$ でサンプル集合 $D$ を分割すると、$V$ 個の分岐ノードが生成される。条件 $a=a_v$ を満たす第 $v$ 分岐ノードのサンプル部分集合を $D_v$ とし、$D_v$ の情報エントロピーは式 (5) で計算できる。分岐ノード間のサンプル数差を考慮するため、重み係数 $|D_v|/|D|$ を適用し、属性分割により達成される情報利得を次式で求める。
$$ Gain(D, a) = Ent(D) - \sum_{v=1}^{V} \frac{|D_v|}{|D|} Ent(D_v) $$ (6)
情報利得の大きさは、属性がデータカテゴリ識別と不確実性低減に寄与する度合いを示す定量指標である。高情報利得属性は、決定木構造における分岐ノードとして優先選択される。
温度、圧力、回転数などの熱力学パラメータは連続値であるため、離散化が不可欠である。故障集合 $D$ と連続パラメータ $P$ に対し、$P$ が降順で $N$ 個の異なる順序値 ${P_1, P_2, ..., P_N}$ を取るとき、最適分割点 $t$ を設定する。この分割点により、サンプルは $D_t^-$(パラメータ値 $\le t$)と $D_t^+$(パラメータ値 $> t$)に分かれる。区間 $[P_i, P_{i+1}]$ 内の任意の分割点 $t$ は隣接値 $P_i$ と $P_{i+1}$ に対して同一分割結果を与える。したがって、パラメータ $P$ の候補分割点は各区間 $[P_i, P_{i+1}]$ の中点 $(P_i + P_{i+1})/2$ により体系的に定められ、候補集合 $T_P$ は次式となる。
T_P = \left\{ \frac{P_i + P_{i+1}}{2} \mid 1 \le i \le N-1 \right\}
(7)
ゆえに、パラメータ $P$ により故障データ集合 $D$ を分割した情報利得は次式で表される。
$$ Gain(D, P) = \max_{t \in T_P} Gain(D, P, t) = \max_{t \in T_P} \left( Ent(D) - \sum_{\lambda \in {-, +}} \frac{|D_t^\lambda|}{|D|} Ent(D_t^\lambda) \right) $$ (8)
算出された $Gain(D, P)$ が十分大きい場合、パラメータ $P$ は高い判別能力を示すため、決定木アーキテクチャの分岐ノードとして優先選択される。
2.5.2. ランダムフォレスト
RFは故障診断分野で高い有効性を示してきたアンサンブル学習手法である。本アルゴリズムは、複数の独立決定木を戦略的に集約することで予測性能を向上させ、単一木のバイアスと分散を効果的に低減する。熱力学パラメータ値 $x_1, x_2... x_N$ で表されるサンプルに対し、$n$ 個の独立学習決定木からなるアンサンブルの集団予測 $T_N(x)$ は次式で表される。
$$ T_N(x) = \frac{1}{N} \sum_{b=1}^{N} T_b(x) $$ (9)
ランダムフォレスト分類では、特徴選択指標として主にジニ指数とエントロピーに基づく情報利得の2種類が用いられる。本研究では主要指標としてジニ指数を採用した。ジニ指数は $[0, 1]$ 区間で定量化される特徴重要度の逆指標であり、0は最大情報利得(最重要パラメータ)、1は最小情報利得(最非重要パラメータ)を意味する。
ジニ指数の数式表現は以下のとおりである。
$$ Gini(D) = 1 - \sum_{i=1}^{C} p_i^2 $$ (10)
ここで $p_i$ はデータ集合中のカテゴリ $i$ の比率、$C$ はカテゴリ数である。
3. 熱力学モデルのシミュレーション
3.1. データ収集
3.1.1. テストデータセット
本研究で用いたテストデータセットは、中国の著名な造船設備メーカーの主機センサシステムから取得した。生データ収集は、図5に示すように、独自開発したデータ収集モジュール(DCM)を船舶推進システムへ統合することで実現した。DCMシステムは階層型収集アーキテクチャを採用し、高速信号ユニット、排ガス処理ユニット、監視システムを含む複数サブシステムからの同期データ取得を可能にする。
システムは10秒間隔で生データを記録し、船上データベースへ保存する。ノイズ干渉低減のため、60秒ごとに移動平均を算出する。データ暗号化後、システムは12時間ごとに、720サンプル点の平均データを含む圧縮CSVファイルを海事衛星経由で陸上サーバへ送信し、最終的に6か月分の船舶用ディーゼルエンジン運用時系列データセットを形成する。生データには厳密な前処理を施し、空白・重複記録除去、欠損値補間、さらにスライディングウィンドウアルゴリズムによる異常検出・補正を行った。
データ前処理後、船舶運用マニュアルを参照して一次選別を行い、船舶用ディーゼルエンジンとの関連が低い熱力学パラメータを除外した。続いて、シミュレーションモデルが有効に監視可能なデータ型と整合させることでデータセットをさらに精緻化した。この二段階選別により、後続のモデル検証と性能評価に堅牢な基盤を与えた。
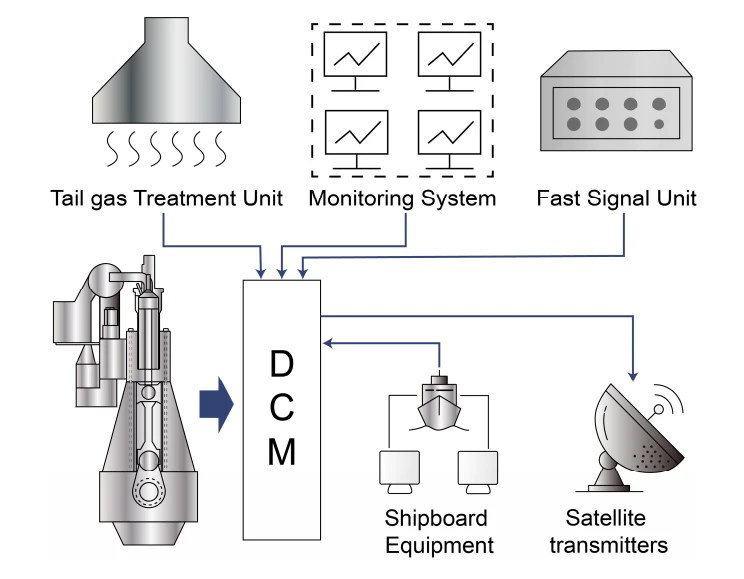
図 5. データ収集モジュール構造
3.1.2. 実験データセット
実験サンプルは、ディーゼルエンジンモデルの完全運転サイクルを含むシミュレーション結果から抽出し、各健全状態につき120サンプルとした。異なる熱パラメータ間には数値範囲および計測スケールの大きな差が存在するため、生データを直接使用すると、特に重み配分において学習過程へバイアスが導入される。そこで最小最大正規化を適用してパラメータ値範囲を標準化し、モデル学習時に全特徴が均衡して寄与するようにした。正規化後、サンプルを訓練データセット(70%)とテストデータセット(30%)へランダムに分割した。
3.2. モデル検証
テストデータセットからエンジン安定回転期間の代表データウィンドウを選び、主要熱パラメータ値の平均をとってモデル検証を行った。表4に示すように、公称運転条件下でシミュレーション結果の熱力学パラメータと実測値の偏差は5%未満であった。この一致度はモデルの信頼性を裏付け、故障シミュレーションシナリオおよび包括的ディーゼルエンジン性能分析へ有効に適用可能であることを示す。
表 4. モデル妥当性検証
| 項目 | 実験値 | シミュレーション値 | 誤差 |
|---|---|---|---|
| 出力 (kW) | 2900 | 2895 | -0.17% |
| エンジン回転数 (rpm) | 86.011 | 90 | +4.64% |
| ターボチャージャ前排気温度 (℃) | 378.953 | 370.557 | -2.22% |
| ターボチャージャ後排気温度 (℃) | 240.464 | 230.254 | -4.25% |
| 空冷器冷却水入口温度 (℃) | 36.101 | 37.521 | +3.93% |
| 空冷器冷却水出口温度 (℃) | 45.661 | 44.385 | -2.79% |
| シリンダライナ温度 (℃) | 122.299 | 125.512 | +2.63% |
| 排気温度 (℃) | 306.897 | 301.525 | -1.75% |
3.3. 故障モデリング
本研究では、シリンダヘッド亀裂(F1)、ピストン焼損(F2)、シリンダライナ摩耗(F3)、ピストンリング摩耗(F4)、ピストンリング固着(F5)を含む特定燃焼室故障状態を模擬するため、体系的なパラメータ微調整手法を開発した。ただし、設定したパラメータ範囲は、シミュレーション結果と実運転条件の潜在的差異に対処するため、さらなる最適化が必要である。今後は、個々の故障モード内で異なる重症度レベルを詳細に検討し、モデルの診断精度と実用適用性を向上させる。各故障タイプにおけるパラメータ校正の詳細を表5に示す。
表 5. 故障パラメータ詳細
| ラベル | 故障タイプ | ブローバイ質量流量 (Kg/s) | シリンダ径 (mm) | ピストン表面温度 (℃) | シリンダヘッド表面温度 (℃) |
|---|---|---|---|---|---|
| F0 | 正常 | 0 | 620 | 276.85 | 246.85 |
| F1 | シリンダヘッド亀裂 | 0 | 620 | 276.85 | 346.85 |
| F2 | ピストン焼損 | 0.01 | 620 | 376.85 | 246.85 |
| F3 | シリンダライナ摩耗 | 0.03 | 620.1 | 276.85 | 246.85 |
| F4 | ピストンリング摩耗 | 0.02 | 620 | 276.85 | 246.85 |
| F5 | ピストンリング固着 | 0.02 | 620.1 | 326.85 | 246.85 |
3.4. 故障シミュレーション結果
本研究では、燃焼室状態評価に対して顕著な診断ポテンシャルを有する14個の熱力学パラメータを同定した。これらの詳細を表6に示す。各故障条件下におけるこれらパラメータの変動を図6(a)-(n)に示し、横軸はクランク角、縦軸はパラメータ振幅を表す。
表 6. シミュレーション出力の熱力学パラメータ
| ラベル | パラメータ | 単位 |
|---|---|---|
| P01 | シリンダ圧力 | Pa |
| P02 | シリンダ温度 | K |
| P03 | ピストン壁熱流 | J/deg |
| P04 | シリンダヘッド壁熱流 | J/deg |
| P05 | シリンダライナ壁熱流 | J/deg |
| P06 | ブローバイ熱流 | J/deg |
| P07 | ブローバイ質量流量 | Kg/s |
| P08 | タービン出力 | J/s |
| P09 | 排気圧力 | Pa |
| P10 | 排気温度 | K |
| P11 | ターボチャージャ前排気圧力 | Pa |
| P12 | ターボチャージャ前排気温度 | K |
| P13 | ターボチャージャ後排気圧力 | Pa |
| P14 | ターボチャージャ後排気温度 | K |

図 6. 故障シミュレーション結果:(a) シリンダ圧力; (b) シリンダ温度; ... (n) 排気温度
4. 結果と考察
4.1. パラメータ選択
ディーゼルエンジンには多数の熱力学パラメータが存在するため、診断目的で全パラメータを包括監視することは現実的でない。そこで、最も診断関連性の高いパラメータを同定するため、パラメータ選択プロセスを実施した。この手法は、監視パラメータ数の最小化と堅牢な故障識別能力維持との間で最適な均衡を達成する。
6つの健全状態における14パラメータのSHAP値を図7(a)に示し、図7(b)で要約した。横軸は平均SHAP値、縦軸は重要度の高い順に並べた14熱力学パラメータである。図7(c)は各パラメータ重要度スコアの百分率分布をさらに示す。結果として、累積寄与率が最も高い8つの中核パラメータを故障識別に採用した。具体的には、P14(ターボチャージャ後排気温度)、P05(シリンダライナ壁熱流)、P06(ブローバイ熱流)、P07(ブローバイ質量流量)、P11(ターボチャージャ前排気圧力)、P12(ターボチャージャ前排気温度)、P03(ピストン壁熱流)、P04(シリンダヘッド壁熱流)である。

図 7. SHAP 値に基づく熱力学パラメータ重要度:(a) SHAP 値ヒートマップ; (b) 棒積み図; (c) 百分率図
4.2. モデル評価
サンプル数が限られることを考慮し、本研究では比較対象の全機械学習モデルに対し、グリッドサーチ法と5分割交差検証を組み合わせた最適化ハイパーパラメータ調整戦略を適用した。K近傍法(KNN)、サポートベクターマシン(SVM)、RFの最適設定を表7に示す。元データセットおよび最適化パラメータ部分集合における6健全状態の評価指標(適合率、再現率、F1スコア、正解率)を表8に示す。これらデータセットに対する各モデルの混同行列と適合率-再現率曲線を、それぞれ図8および図9に示す。
混同行列は、モデル間の特徴的性能差を示す。KNNは元データセットでF3-F5故障条件の識別正解率が相対的に低い(図8(a))。しかし最適パラメータ部分集合を用いると、これら故障条件の診断能力は顕著に改善した(図8(d))。SVMは元データセットでF1およびF4故障識別性能が不十分であった(図8(b))。最適化パラメータ部分集合ではこれら故障の識別精度は向上したが、F3検出性能は低下した(図8(e))。対照的にRFは、元データセットで当初F5故障識別が不十分であった(図8(c))ものの、最適特徴部分集合導入後は6健全状態すべてで優れた総合性能を示した(図8(f))。F4とF5の識別能力はわずかに低下したが、両故障タイプはいずれもピストンリング関連であり、システム影響パターンが類似する点に留意すべきである。評価結果は、実験構築故障データセットにおいてRFがSVMとKNNを上回ることを示した。
表 7 モデルハイパーパラメータ選択
| モデル | 学習の主要ハイパーパラメータ |
|---|---|
| KNN | n_neighbors: 3, metric: manhattan, weights: distance |
| SVM | C: 1.0, kernel: linear, gamma: scale |
| RF | n_estimators: 20, max_depth: None, max_features: sqrt |
表 8. 各モデル性能比較
(注:表データは省略。詳細は原文表8を参照。RFは最適化部分集合で99.07%の正解率を達成)
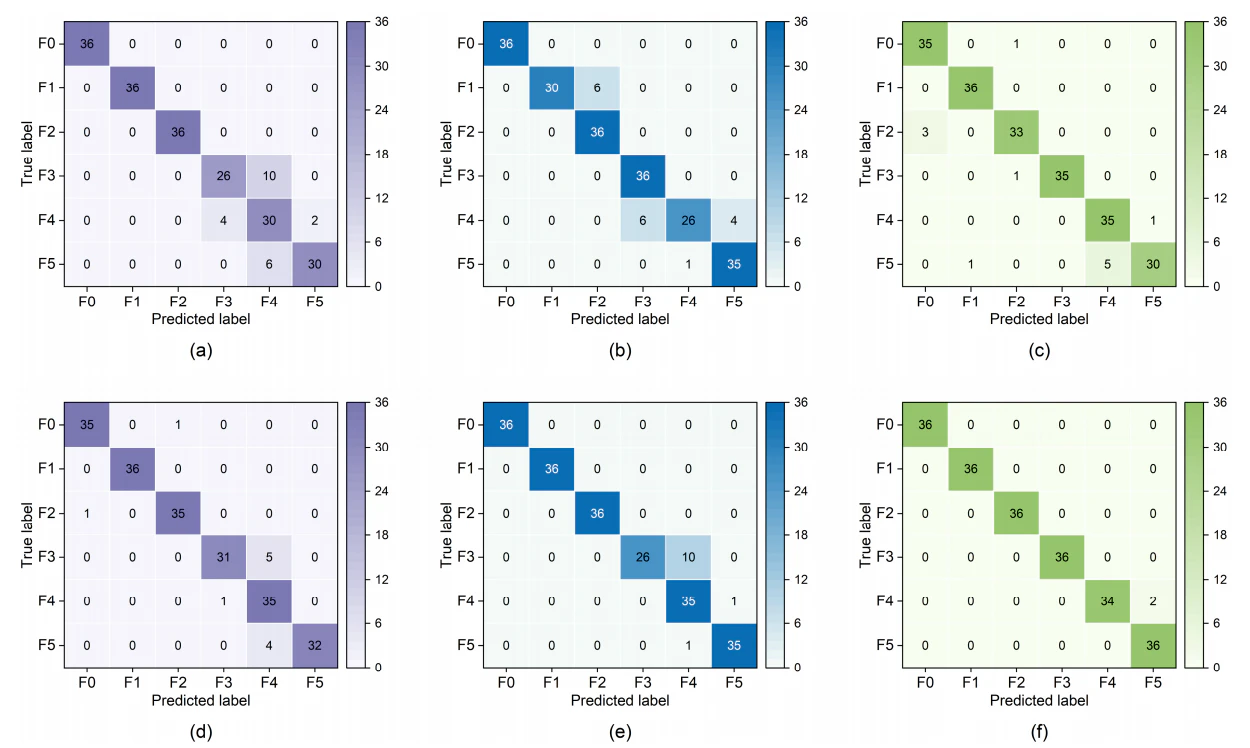
図 8 混同行列 および

図 9 適合率 - 再現率曲線
包括的比較分析を構築するため、複数の特徴選択手法を実施し、各手法で得られた最適パラメータ部分集合を図10に示した。分類モデルとしてRFを用いて各最適化部分集合の診断性能を評価し、平均正解率を表9にまとめた。結果として、SHAPで得たパラメータ部分集合は、他の特徴選択手法で得た部分集合より優れた診断能力を示した。

図 10 異なる特徴選択手法の最適部分集合
表 9 異なる特徴選択手法を用いた RF 正解率
| 手法 | 平均正解率 (%) |
|---|---|
| カイ二乗検定 | 78.51 ± 0.53 |
| RFE | 81.62 ± 0.22 |
| ジニ指数 | 88.95 ± 0.45 |
| SHAP | 99.07 ± 0.21 |
4.3. 熱力学モデル支援解釈
熱力学モデリング支援による説明可能性向上を示すため、本研究ではピストンリング故障(F4)を代表ケースとして採用した。解析は二重スケールで実施し、まず単一サンプル視点でモデル意思決定機構を検討し、続いて故障特性の大域視点を検討した。
4.3.1. 単一サンプル分析
ウォーターフォール図は単一サンプル重要度評価を分析する有効な可視化ツールとして用いた(図9(a))(注:原文のこの参照は誤記の可能性があり、図11aであるべき)。ウォーターフォール図の情報解釈は次のとおりである。(1) 図は下部のモデル出力期待値 $E[f(x)]$ から始まる。(2) 各水平バーはパラメータ寄与の大きさと方向を定量表示し、赤は正寄与、青は負影響を示す。(3) 終端値 $f(x)$ は全パラメータ寄与の代数和で計算され、当該サンプルに対する最終予測を表す。
図11(a)より、特定パラメータ値がモデル予測方向に直接影響することが分かる。ただし、これら値と標準参照値の関係は直ちには明瞭でない。図6の熱力学モデル出力と統合すると、P06=1.641、P07=-0.024、P12=728.568といった特定時点で、P14とP04が著しく低く、モデル予測へ負の影響を与えていることが明確になる。ピストンリング摩耗がブローバイを悪化させる点を踏まえ、この現象を事前知識として故障モデルへ組み込んだ。ブローバイの存在はP14とP04を増加させるはずであり、サンプル点で観測された低値とは直接矛盾するため、最終的にモデル予測精度を低下させる。
4.3.2. 大域解釈
本研究では、F4故障状態の全サンプル評価結果を要約し、熱力学パラメータ変化によるサンプル分布をビースウォーム図で示した(図11b)。さらに、各パラメータ平均SHAP値とビースウォーム図を組み合わせ、パラメータ重要度分布をより直感的に表現した。ビースウォーム図の情報解釈は次のとおりである。(1) Y軸は重要度順に並んだパラメータを示し、各バーは当該パラメータの平均Shapley値を表す。(2) 各サンプルは点で示され、点のX軸位置はSHAP値に対応し、各行内での点の重なりが密度を示す。(3) 色はパラメータの元の値を表す。(4) 点の水平分布は影響量を反映し、分布が広いほど影響が大きい。
図11(b)は、P11、P12、P07、P06の低下値が、故障タイプF4を識別するモデル予測傾向へ顕著な影響を与えることを示す。熱力学パラメータ間相互依存性を精査するため、本研究ではさらにSHAP相互作用値を計算した。最も影響力の高い6つのパラメータ相互作用を図11(c)に示し、P11-P12およびP06-P07の具体的相互作用を図11(d)に可視化した。依存図の情報解釈は次のとおりである。(1) 各点は単一サンプル予測に対応する。(2) X軸はパラメータ実値を示す。(3) Y軸はパラメータSHAP値を示す。(4) 色変化は相互作用パラメータ値を反映する。
結果より、P11-P12およびP06-P07の間に有意な正相関が存在し、基礎熱力学原理と一致した。熱力学モデリング結果(図6k)と合わせると、P11の値は全健全状態の中で最も低い。P11とP12の正相関により、P12も対応して低下する。さらに、ピストンリング摩耗は主にブローバイで特徴付けられ、P06とP07はブローバイ重症度と負相関を示す。したがって、P06およびP07の低下値は、ピストンリング摩耗状態を識別する有効指標となる。

図 11 SHAP 値に基づくピストンリング摩耗 (F4) 故障分析:(a) ウォーターフォール図; (b) ビースウォーム図; (c) 相互作用図; (d) 依存図
5. 結論
データ駆動手法とモデルベース手法の統合は、シミュレーション信頼性とモデル説明可能性の向上に向けた重要課題である。本研究は、熱力学シミュレーション支援ランダムフォレスト(TSRF)法と呼ぶ、船舶用ディーゼルエンジン燃焼室向けの革新的な説明可能故障診断フレームワークを提示した。シミュレーション部では、事前故障知識を組み込み、主要燃焼室部品に対する5つの熱力学故障モデルを構築した。診断フレームワークでは、SHAP値と熱力学モデリングを協調統合することで診断能力向上を図った。提案手法は故障診断の信頼性ある支援を目的とし、燃焼室診断結果の説明可能性向上に資する。
DCMで収集したテストデータにより、構築した一次元熱力学モデルの有効性を確認した。さらに、従来機械学習手法との実験比較により、開発TSRFの診断精度向上効果を検証した。開発TSRFは本研究構築の故障データセット上でKNNおよびSVMを上回り、平均正解率99.07%を達成した。
加えて、特定故障ケース(F4)における熱力学パラメータの寄与と相互作用を調査・解釈し、モデル意思決定結果の説明分析を提示した。TSRFモデル推定とSHAP分析の結果に基づけば、ターボチャージャ排気温度、ブローバイ熱流、シリンダライナ熱流が故障診断結果に影響する主要熱力学パラメータである。
今後は、提案手法のさらなる評価と高度化のため、異なる海洋条件を調査する。加えて、故障パラメータ設定を最適化し、故障重症度の違いを統合して、より精密な分類と高い診断精度を実現する。さらに、深層学習などの先進モデルと、多領域モデルや詳細化学反応を含む各種熱力学モデリング手法との協調統合に注力する予定である。この戦略は、データ駆動学習と物理ベースモデリングの補完的利点を活かし、船舶用ディーゼルエンジン故障診断における予測精度向上と頑健な物理的解釈可能性の両立を目指す。
論文情報
タイトル:Thermodynamic Simulation-assisted Random Forest: Towards explainable fault diagnosis of combustion chamber components of marine diesel engines
DOI:[10.1016/j.measurement.2025.117252]
リンク:https://doi.org/10.1016/j.measurement.2025.117252