1. 概要
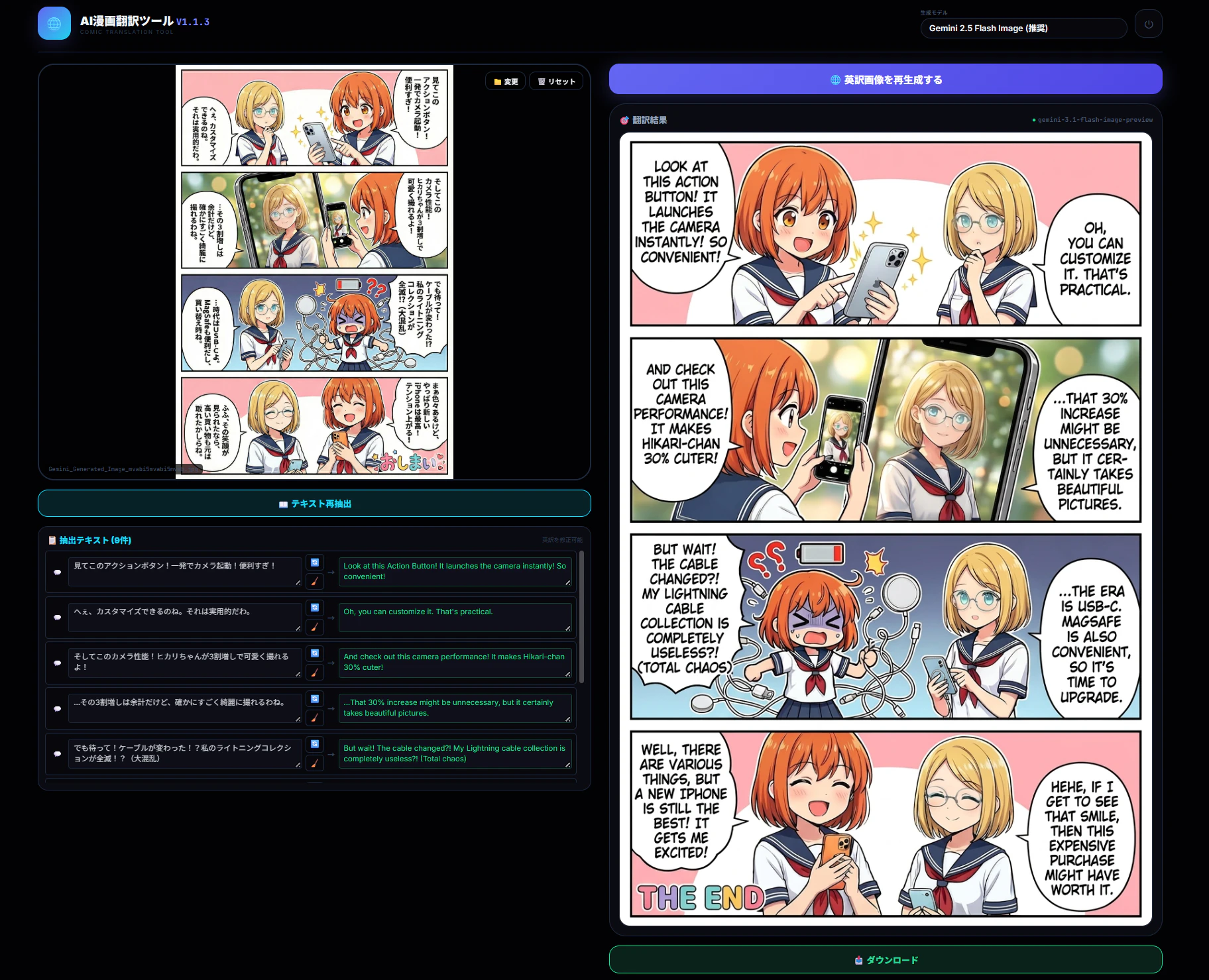
日本語の漫画を海外向けに翻訳するには、翻訳・写植(タイポグラフィ)・背景修正、そして「右読みから左読みへの反転(Horizontal Flip)」という膨大な工数が必要です。
今回、これらのワークフローをGoogle Gemini APIのマルチモーダル機能とReactを組み合わせて完全自動化した「AI Comic Translation Tool」を開発しました。
- デモ: https://furuyan1234.github.io/comic-translation/
- リポジトリ: https://github.com/FURUYAN1234/comic-translation
この記事では、単なるOCR翻訳にとどまらない「2段階AIパイプライン」のアーキテクチャと、画像操作とAIを融合させるフロントエンド実装の裏側を徹底解説します。
2. システム構成:フロントエンド完結型SPA
本アプリはバックエンドを持たない、React + Vite構成のSPA(Single Page Application)です。
- セキュリティ: ユーザー自身のAPIキーを使用する「BYOK」モデル。キーはセッションメモリ内でのみ保持され、永続化しないため安全です。
- 技術スタック: React 19, Vanilla CSS, Canvas API, Gemini API REST連携。
3. 第1フェーズ:マルチモーダルによる文脈解析と抽出
従来のOCRでは、漫画特有の「縦書き」「吹き出しの順序」「背景の描き文字」を正しく判別できません。本システムでは、Gemini 1.5 Pro/Flashに対し、画像をBase64で送信し、**Structured Outputs(JSON Schema)**を用いて以下の情報を取得します。
// 期待するJSON構造
{
"dialogues": [
{ "original": "こんにちは", "translation": "Hello", "coords": [x, y, w, h] },
...
],
"sfx": ["ドーン", "ゴゴゴ"]
}
この際、プロンプトで「キャラクターの表情やシーンの緊張感を読み取り、意訳せよ」と指示することで、単なる直訳ではない、作品の空気に馴染む英訳を実現しています。
4. 中間処理:Canvas APIによる画像の「構造的反転」
漫画を海外向けにする際、単に文字を英語にするだけでは不十分です。コマ割りの順序を解決するため、ブラウザのCanvas APIを使用して画像を左右反転(ミラーリング)させます。
反転後の座標計算はフロントエンド側でロジックを組み、第1フェーズで取得したテキストの座標を反転後の位置に再マッピングします。これにより、反転後の画像に対しても正確な「写植」が可能になります。
5. 第2フェーズ:Inpaintingと画像再生成(写植)
反転後の画像には、「鏡文字になった元の吹き出し」が残っています。これを解決するのが第2フェーズです。
反転済み画像と翻訳データを再度Gemini/Imagenのパイプラインに投げ、以下のタスクをAIに実行させます。
- マスク処理(インペイント): 元の吹き出し内を白塗り、または背景補完して文字を消去。
- 自動タイポグラフィ: 抽出した座標に基づき、適切なフォントサイズとウェイトで英語テキストを画像に直接焼き付ける。
これにより、画像1枚をアップロードするだけで、レイアウト調整と翻訳済みの画像がワンストップで出力されるパイプラインが完成しました。
6. まとめ
「AI Comic Translation Tool」は、Gemini APIを単なるチャットとしてではなく、「高度な視覚推論エンジン」および「画像編集エンジン」として活用した事例です。
ソースコードはGitHubでPublic公開しています。AIパイプラインの構築やマルチモーダル活用に興味のある方は、ぜひリポジトリを覗いてみてください。