はじめに
生成 AI を活用して業務の効率化を図ることは、もはや世界的な取り組みとなってきています。
OpenAI ChatGPT (Microsoft Copilot)、Google Gemini、Meta Llama など、各社優れたサービスを展開しており、私も日常業務で生成 AI を活用しています。
生成 AI の機能限界
しかし、生成 AI の機能には限界があります。生成 AI はクローラーによって大量のデータをかき集めて、それらを機械学習しています。そのため、クローラーがアクセスできない場所にある社内の蓄積情報が反映されていなかったり、最新の情報が反映されていなかったりします。
社内情報
例えば、Gemini に Yellowfin Japan株式会社の社内規約を質問してみると、下記のような返答を返します。

生成 AI のクローラーは非公開情報にはアクセスできないため、当然の結果と言えます。
生成 AI の機能を補足
このような生成 AI 機能の限界を補足する代表てきな技術として、ファインチューニングや RAG (Retrieval Augmented Generation : 検索拡張生成) などが存在します。
ファインチューニング
既に生成 AI が学習済みのモデルに対して、企業独自の非公開データなどを追加で学習させ、最適化を図ることをファインチューニングと呼んでいます。
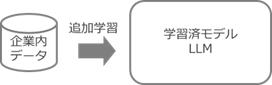
ファインチューニングを行うことで、モデルの最適化が図られ、各企業にとってより精度の高い回答を得られるようになることが期待できます。
一方で、学習する追加データの質や量によっては、必ずしも期待する結果が得られないことも多いようです。
RAG
2 つ目の選択肢は RAG です。生成 AI が未学習の情報を含む独自情報を検索した結果を伴って、生成 AI に質問を投げかけることによって、より精度の高い回答を得ようとするものです。
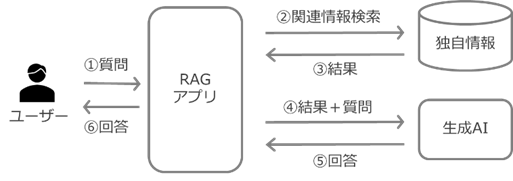
ファインチューニングに適したデータを準備しきれない場合などに、非常に有効な選択肢と言えます。
RAG の実装
処理の全容
実際に RAG の仕組みを実装してみようと思います。
実行環境は、私が普段業務で使用する Windwows 11 PC です。
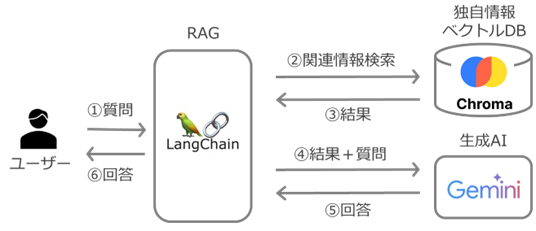
Windows に以下の組み合わせで RAG の仕組みを実装します。
| 役割 | サービス、アプリ | 説明 |
|---|---|---|
| RAG アプリ | LangChain | Python 向け LLM アプリ開発用ライブラリ |
| 独自情報 | Chroma | ベクトル・データベース |
| 生成 AI | Gemini | Gemini API 経由 |
| 言語 | Python 3.13.3 | LangChain を参照して処理を記述 |
API Key の準備
Gemini の API にアクセスするためには、API Key が必要です。
API Key の取得方法に関しては、下記が解り易いと思います。
LangChain インストール
まずはライブラリをインストールします。
pip install langchain
ドキュメントのロード
ここから先は Python で処理を記述します。
インストールしたライブラリ群に含まれる langchain_community ライブラリから、PyPDFLoader を使用して PFD ファイルをロードします。今回は、『Yellowfin 紹介資料.pdf』 を仕組みの中にロードします。我々が普段製品紹介に使用している資料です。本来であれば社外秘ドキュメントを使って実行結果を見たみたいところなのですが、さすがに本当の社外情報を使うわけにはいかないため、同ドキュメントをロードします。
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("Yellowfin紹介資料.pdf")
data = loader.load()
ドキュメントを Chunk に分割
RecursiveCharacterTextSplitter クラスを使用して、ドキュメントのデータを Chunk と呼ぶ単位に分割していきます。
後の手順で、Chunk 単位でデータをベクトル DB の Chroma に格納します。
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=1000)
docs = text_splitter.split_documents(data)
print("Chunk数:", len(docs))
for chunk in docs:
print(chunk.page_content)
print 行が以下の情報を出力し、処理結果を確認することができます。
Chunk数: 21
Yellowfin 紹介資料
Yellowfin Japan株式会社
2025年5月
組み込みBIの先駆者
…
ベクトル化
Google Gemini を使って、Chunk をベクトル化 (Embedding) します。model にテキストエンベディングのモデルを選択し、google_api_key に自身の API Key を入力します。なお、下記ではコードに直接 API Key を記述していますが、実運用時は、該当箇所を os.getenv("GOOGLE_API_KEY") に書き換え、Windows OS の環境変数に登録した値を利用してセキュリティを担保することが一般的です。
embeddings = GoogleGenerativeAIEmbeddings(model="models/embedding-001", google_api_key="<your_api_key_here>")
vector = embeddings.embed_query("世界の皆さんこんにちは")
print("次元数:", len(vector))
print(vector)
print 行の出力内容を確認すると、“世界の皆さんこんにちは“ が、768 次元のベクトルに変換されたことが確認できます。
次元数:768
[0.042790789157152176, … , 0.03161672502756119]
ベクトル・データベース
インストールしたライブラリ群に含まれる langchain_chroma ライブラリから、Chroma ベクトル・データベースを import して利用します。
下記のコードでは、ベクトル化したドキュメントを類似検索するためのパラメーターが設定されています。各パラメータ値の詳細に関しては、こちらでご確認ください。
from langchain_chroma import Chroma
vectorstoredb = Chroma.from_documents(documents=docs, embedding=embeddings)
retriever = vectorstoredb.as_retriever(search_type="similarity", search_kwargs={"k": 5})
Chroma 以外にも、PostgreSQL に pgvector をエクステンションとして適用することで、PostgreSQL をベクトル・データベースとして活用することが可能です。また、poinecone など、無料で利用できるサービスもたくさん存在します。
自然言語ベクトル化とベクトル DB に関しては、以下の記事で詳しく説明しています。併せてご確認ください。
LLM の定義
次に、ChatGoogleGenerativeAI を使用して、Gemini の LLM を定義します。
model には無料で使用できる gemini-2.0-flash を指定しています。モデル一覧はこちらで確認できます。
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(model="gemini-2.0-flash", temperature=0.3)
RAG Chain の構築
カスタム・プロンプトを定義して、ドキュメントから取得するデータを、Gemini に対する質問と回答のやり取りと統合します。
こちらに説明されている通り、prompt の system の項目には、モデルにどのように行動して欲しいかを定義します。human の項目には、ユーザーが知りたい質問を記述します。下記のコードでは human の部分に {input} を指定しているため、コンソールから入力するデータを input データとして扱います。
最後に、定義た内容 (llm / prompt / retriever / chain) を使ってRAG Chain を構築します。
system_prompt = (
"確かな情報だけを用いて、企業に関する情報を提供してください。"
"\n\n"
"{context}"
)
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", "{input}")
]
)
chain = create_stuff_documents_chain(llm, prompt)
rag_chain = create_retrieval_chain(retriever, chain)
質問してみよう
最後に、実際に質問をしてみます。
ベクトル DB に格納したドキュメントのデータを反映する場合と反映しない場合で、どのように Gemini の回答が変わってくるかを確認するために、まずはブラウザから Gemini にアクセスして質問してみます。
質問:Yellowfinについて2行で説明してください
回答:Yellowfinは、キハダマグロやコガネガレイといった魚の種類を指すこともありますが、IT分野ではAIによる自動分析機能を備えたビジネスインテリジェンス(BI)プラットフォームの名称としても使われます。このBIプラットフォームは、企業がデータを活用して意思決定を加速するための多様な分析ツールを提供しています。

今度はプログラムを実行して、質問をしてみます。
response=rag_chain.invoke({"input":"Yellowfinについて2行で説明してください"})
print(response)
結果、以下のような回答が返ってきました。
Yellowfinは、データ分析や可視化を行うためのBI(ビジネスインテリジェンス)アプリケーションです。
そのまま利用するほか、他のアプリケーションに組み込んで必要な機能だけを利用することも可能です。
製品紹介資料ドキュメントの内容を反映した回答となっていることが確認できます。
プログラム全容
プログラム全容は以下の通りです。なお、動作確認用の print 行は含みません。
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain_chroma import Chroma
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
#ドキュメントのロード
loader = PyPDFLoader("Yellowfin紹介資料.pdf")
data = loader.load()
#ドキュメントを Chunk に分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=1000)
docs = text_splitter.split_documents(data)
#ベクトル化
embeddings = GoogleGenerativeAIEmbeddings(model="models/embedding-001", google_api_key="<your_api_key_here>")
#ベクトルデータベース
vectorstoredb = Chroma.from_documents(documents=docs, embedding=embeddings)
retriever = vectorstoredb.as_retriever(search_type="similarity", search_kwargs={"k": 5})
#LLMの定義
llm = ChatGoogleGenerativeAI(model="gemini-2.0-flash", temperature=0.3)
#RAG Chain の構築
system_prompt = (
"確かな情報だけを用いて、企業に関する情報を提供してください。"
"\n\n"
"{context}"
)
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", "{input}")
]
)
chain = create_stuff_documents_chain(llm, prompt)
rag_chain = create_retrieval_chain(retriever, chain)
#質問と回答
response=rag_chain.invoke({"input":"Yellowfinについて2行で説明してください"})
print(response)
データの流れ
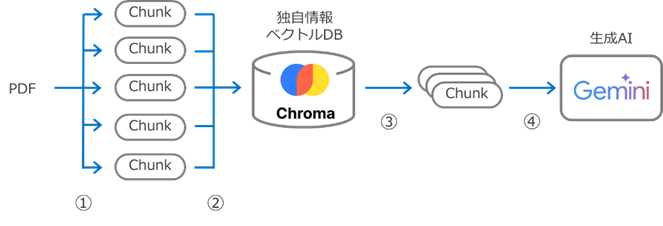
処理概要を、データの流れに着目しておさらいしたいと思います。
① PDF ファイルを複数の Chunk (raw テキスト) に分割
② 各 Chunk をベクトル化してChroma (ベクトル DB) に格納
③ ユーザーのクエリーに従って、ベクトルの類似度の高い Chunk ベクトル DB から取得
④ 取得した Chunk を伴って LLM に問い合わせ
最後に
RAG 検証する中で感じたこととして、ベクトル DB (今回でいうと Chroma DB が該当) に投入するデータの精度がかなり重要な印象を受けました。
今後、ファインチューニングや RAG が世の中に広がる中で、どのようなことが課題になるかも、注視していこうと思います。
では皆様、良いデータ分析を‼
参考情報