はじめに
NoSQL データベースの一種で、KVS (Key-Value Store) 構造を持つ分散型データベースの代表格 Cassandra に、Yellowfin からアクセスして、データを可視化してみようと思います。と、知ったかぶりして書いてみましたが、生まれて初めて Cassandra を取り扱ってみました。
ちなみに、NoSQL データベースの仲間である MongoDB へのアクセスはこちらで紹介しています。
環境準備
Cassandra のインストール
Linux
Linux へのインストール手順は、こちらの記事が参考になります。
Cassandra をインストールするためには、Java 実行環境と Python 環境が前提条件となります。Linux OS に標準で Python がインストールされていない場合は、Python のインストールが必要です。その場合、Pythonはバージョン 2.xx のインストールが望まれます。3.xx だと Python プログラムを修正する必要があるからです。
その後、こちらから Cassandra を入手し、インストールします。
Windows
Windows へのインストール手順は、こちらの動画がとても参考になります。英語の動画ですが、すごく丁寧に手順が説明されています。なお、バージョン 4.xx 以降は、Windows 用の実行ファイルが準備されていないため、Windows 環境にインストールする場合は、アーカイブサイトから 3.11 のバージョンまで遡ってインストールする必要があります。
Docker
一番楽なのは Docker イメージを入手することです。
docker pull cassandra:latest
入手後は、下記を参考に、イメージからコンテナを立ち上げます。
docker network create cassandra
docker run --rm -d --name cassandra --hostname Cassandra -p 9042:9042 --network cassandra cassandra
コンテナを立ち上げたら、コンテナにログインします。
Docker exec -it cassandra /bin/bash
データ準備
コンテナにログインした後、cqlshコマンドを実行します。cqlsh とは、PostgreSql や SQL Server でいうところの、SQL 文を発行するもので、同コマンドを実行すると、cqlsh> プロンプトに切り替わります。
keyspace
Cassandra では database に該当するものが keyspace です。
既存 keyspace を確認した後、test という名前の keyspace を作成します。
cqlsh> describe kyespaces;
cqlsh> create keyspace test with replication = { 'class' : 'SimpleStrategy', 'replication_factor' : 1 };
replication 内のオプションは必須で指定する必要があります。1 つのデータセンター内で運用する場合は、Class = SimpleStrategy で大丈夫です。SimpleStrategy を指定した場合、replication_factor = 1 のように、レプリカのノード数を指定する必要があります。大規模展開に必要なオプションなどはこちらご確認ください。
table
keyspace に入ったのち、テーブルを作成します。create table のシンタックスは、通常のデータベースとほぼ同様です。
cqlsh> use test;
cqlsh:test> create table test.fruits (
... id text primary key,
... name text,
... price int);
テーブルにデータを投入します。insert 文も通常のデータベースとほぼ同じシンタックスです。
cqlsh:test> insert into fruits (id, name, price) values ('001', 'banana', 100);
cqlsh:test> insert into fruits (id, name, price) values ('002', 'apple', 150);
cqlsh:test> insert into fruits (id, name, price) values ('003', 'durian', 980);
テーブルを参照します。
select * from fruits;
id | name | price
-----+--------+-------
002 | apple | 150
001 | banana | 100
003 | durian | 980
JDBC コネクタ
JDBC コネクタの入手
今回は CData の Cassandra JDBC コネクタ評価版を利用します。下記は Windows 環境を前提としたコネクタのインストール手順です。
まずは下記 URL にアクセスし、対応データソースから Cassandra を選択します。
その後、[ダウンロード] > [ダウンロード評価版] > [ダウンロード Windows Setup (.exe)] の順に進み、CassandraJDBCDriver.exe をダウンロードします。
CassandraJDBCDriver.exe を実行すると、デフォルトで以下にファイルが解凍されます。
C:\Program Files\CData\CData JDBC Driver for Cassandra 2024
lib フォルダに以下のようなファイルが存在します。
コネクタのインストール
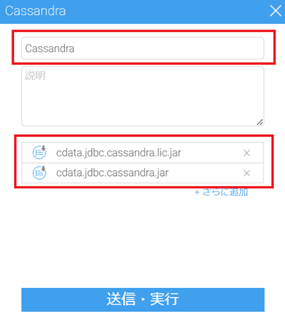
ライセンスファイル cdata.jdbc.cassandra.lic を zip ファイルに圧縮した後、cdata.jdbc.cassandra.lic.zip を cdata.jdbc.cassandra.lic.jar に名称変更します。Yellowfin プラグイン管理画面で .jar か .yfp ファイルしか登録できないことへの対応です。

Yellowfin 画面から [管理] > [プラグイン管理] > [追加] と進み、cdata.jdbc.cassandra.jar をドロップして追加した後、「さらに追加」を選択して、cdata.jdbc.cassandra.lic.jar を追加します。結果、以下のように、実行ファイルとライセンスファイルの両者を合わせて登録します。
データソース
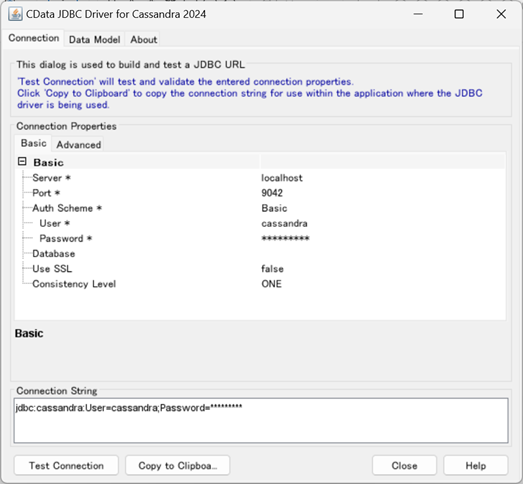
Yellowfin からは一般 JDBC データソースを利用して Cassandra に接続します。一般 JDBC データソースを利用するための接続文字列は、CData の機能を使って生成すると便利です。cdata.jdbc.cassandra.jar をダブルクリックすると、下記の画面が表示されます。こちらで接続テストをした後、接続文字列をコピーして利用すると良いかと思います。

Yellowfin 画面から [管理] > [プラグイン管理] > [追加] と進み、[新規データ接続] で [データソースを選択] から [データベース] を選択します。
新規接続の設定画面から、以下を参照に新規接続を作成します。
| 項目 | 設定値 |
|---|---|
| 名前 | Cassandra |
| データベースタイプ | 一般 JDBC データソース |
| JDBC ドライバー | cdata.jdbc.Cassandra.CassandraDriver(Cassandra) |
| 接続文字 | jdbc:cassandra:User=cassandra;Password=cassandra;Database=test; |
[テスト接続] ボタンを押下し、テスト接続が成功すればひとまず大丈夫です。

ビュー作成
こちらを参考に、ビューを作成します。

レポートの作成
こちらを参考に、レポートを作成します。

最後に
一般的な KVS の利点として、分散型データベースとしてのスケーラビリティや可用性に加え、パフォーマンスなんかも述べられています。
ただ、KVS が具体的にどのような用途に適しているのかや、KVS 内のデータを BI ツールで可視化する用途があるのかなど、まだまだ分かっていないことがたくさんあります。
このあたりに知見のある人がいれば、是非ご教授ください。
では皆様、良いデータ分析を! See you then!