こんにちは!estie(エスティ)のCEOをやっている平井です。
本日はアドベントカレンダー2019の最終日ということで、オフィス探しをシンプルにする「estie」らしく、Pythonを使って東京23区の全法人の本店登記住所を分析してみたいと思います!
⭐️この記事の内容
- 東京の企業本店立地のばらつきをfoliumを活用して町村レベルで可視化
- 渋谷区の企業本店立地を細かくfoliumで可視化(登記数が最も多かった建物を公開します!!)
⭐️ソースコード
環境
% sw_vers
ProductName: Mac OS X
ProductVersion: 10.15.2
BuildVersion: 19C57
(venv) % python -V
Python 3.6.8
データ
取得元
会社を登記すると税金を納付しなければなりませんので、必ず国税庁に設立申請を行います。すると国税庁から「法人番号」という数字が割り当てられ、晴れて法人として営業を開始できます。例えば、株式会社estieの法人番号は9010001197108で、こちらのURLから法人の情報が閲覧できます。
こちらの国税庁データですが、有難いことにAPIを提供してくれているので、今回は東京の全法人の本店データを取得して、その住所情報を元に色々な分析をしてみたいと思います!(取得作業はAPIの仕様を見ながら各自でやってみてください)
https://www.houjin-bangou.nta.go.jp/webapi/
東京の事業所データを眺めてみる
まずはdfのカラム構成を見てみましょう。
import pandas as pd
df = pd.read_csv('./tokyo_full.csv')
df.columns
>>> Index(['sequenceNumber', 'corporateNumber', 'process', 'correct', 'updateDate','changeDate', 'name', 'nameImageId', 'kind', 'prefectureName', 'cityName', 'streetNumber', 'addressImageId', 'prefectureCode', 'cityCode', 'postCode', 'addressOutside', 'addressOutsideImageId', 'closeDate', 'closeCause', 'successorCorporateNumber', 'changeCause', 'assignmentDate', 'latest', 'enName', 'enPrefectureName', 'enCityName', 'enAddressOutside', 'furigana', 'hihyoji', 'address', 'city_id', 'city'], dtype='object')
※address, city_id, cityはestieのデータベースを使って追加したものです。
登記されている事業所数
下記のコードで各カラムのレコード数を数えてみます。全部で1,070,457もの法人が東京都に本店登記をしているんですね!
df.count()
>>>
sequenceNumber 1070457
corporateNumber 1070457
process 1070457
correct 1070457
updateDate 1070457
changeDate 1070457
name 1070457
nameImageId 9952
kind 1070457
prefectureName 1070457
cityName 1070457
streetNumber 1070457
addressImageId 9340
prefectureCode 1070457
cityCode 1070457
postCode 1070104
addressOutside 0
addressOutsideImageId 0
closeDate 60540
closeCause 60540
successorCorporateNumber 6284
changeCause 10174
assignmentDate 1070457
latest 1070457
enName 920
enPrefectureName 903
enCityName 903
enAddressOutside 0
furigana 320791
hihyoji 1070457
address 1070457
city_id 1070457
city 917185
dtype: int64
エリアのばらつき
次に東京23区に注目して、エリアごとの登記数のばらつきを見ていきましょう。
# 下でcityごとに企業数を数えるため、'count'と言うカラムを用意します
df['count'] = 1
# estieのデータセットの都合で、町村名が入っているのが23区だけなので、それ以外をdfから落とします
df = df.dropna(subset=['city'])
# 'city_id'でまとめて先ほど'1'を入れておいた'count'カラムを足し上げることによって各city_idにおける企業数を計算します
df_tokyo23 = df.groupby(['city_id'], as_index=False).agg({'count': lambda x: sum(x)})
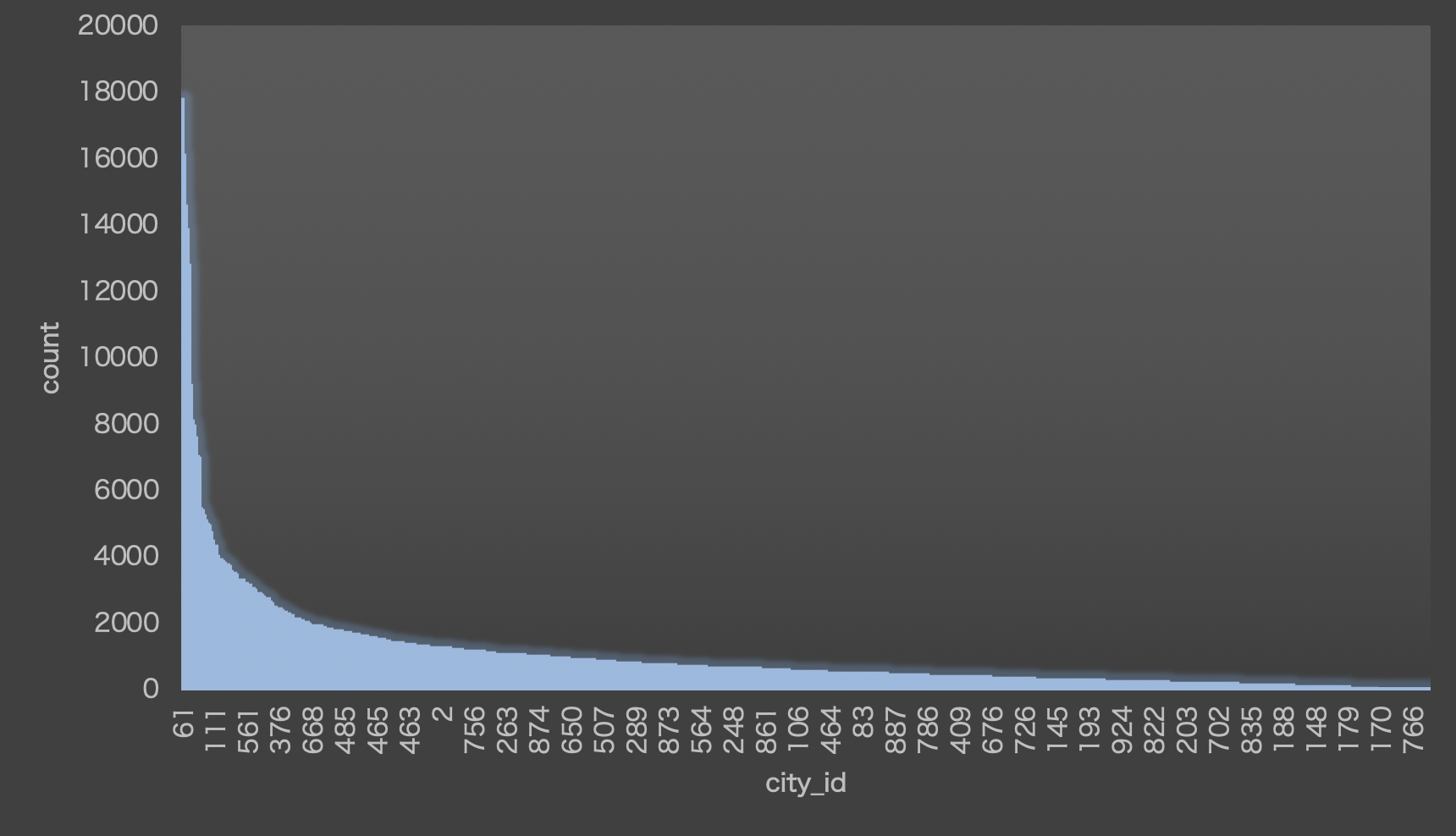
df_tokyo23.sort_values('count', ascending=False)
>>>
| city_id | count |
| 59 | 61.0 | 17792 |
| 114 | 117.0 | 16150 |
| 214 | 220.0 | 14593 |
| 115 | 118.0 | 13876 |
| 137 | 143.0 | 12810 |
... ... ...
| 48 | 50.0 | 1 |
| 868 | 884.0 | 1 |
物凄い偏りがありますね・・・
それでは、foliumを使って地図に可視化してみましょう!
(Geojsonは各自用意してみてください)
import pandas as pd
import folium
import json
import traceback
import matplotlib.colors as cl
from RW_S3 import *
s3r = S3Reader()
# データセットの準備
df = pd.read_csv('./tokyo_full.csv')
df['count'] = 1
# 23区以外を落とす
df = df.dropna(subset=['city'])
df_tokyo23 = df.groupby(['city_id'], as_index=False).agg({'count': lambda x: sum(x)})
def calc_RGB_value(norm_count: float):
'''0-1スケールに圧縮された数値をRGBの16進数表記として返す. 一番安い物件が水色, 高い物件がオレンジとなるようにする
Args:
norm_count (float): 0-1スケールに圧縮された数値
Returns:
str
ex: #54b0c5
'''
R_val = 41 + (255 - 41) * norm_count
G_val = 182 + (150 - 182) * norm_count
B_val = 246 + (0 - 246) * norm_count
return cl.to_hex((R_val / 255, G_val / 255, B_val / 255, 1))
def add_color_col(df):
'''colorカラムを追加
Args:
df (pd.DataFrame)
Returns:
pd.DataFrame
'color'カラムを追加して返す
'''
norm = cl.Normalize(vmin=df['count'].min(), vmax=df['count'].max())
norm_count_ = [norm(v) for v in df['count']] # 企業数を0,1スケールにする
color_ = [calc_RGB_value(norm_count) for norm_count in norm_count_]
df['norm_count'] = norm_count_
df['color'] = color_
return df
df_tokyo23 = add_color_col(df_tokyo23)
folium_map_tokyo = folium.Map(
location=[35.731005,139.452995],
zoom_start=9,
tiles='cartodbpositron') # マップ作成
def add_to_m(i):
m = folium.GeoJson(
s3r.read_json_file('prd-data-store', 'location/geojson/city/_' + str(int(df_tokyo23.city_id[i])) + '.json'),
name='region_name',
style_function = lambda x: {
'fillOpacity': df_tokyo23.norm_count[i] * 2,
'fillColor': df_tokyo23.color[i],
'color': 'white',
})
return m
for i in range(len(df_tokyo23)):
try:
m = add_to_m(i)
m.add_to(folium_map_tokyo)
if i % 100 == 0:
print('=== ' + str(i) + ': success ===')
except:
traceback.print_exc()
print('Completed')
folium_map_tokyo23.save('./tokyo23.html')
df_tokyo23.to_csv('./df_tokyo23.csv')
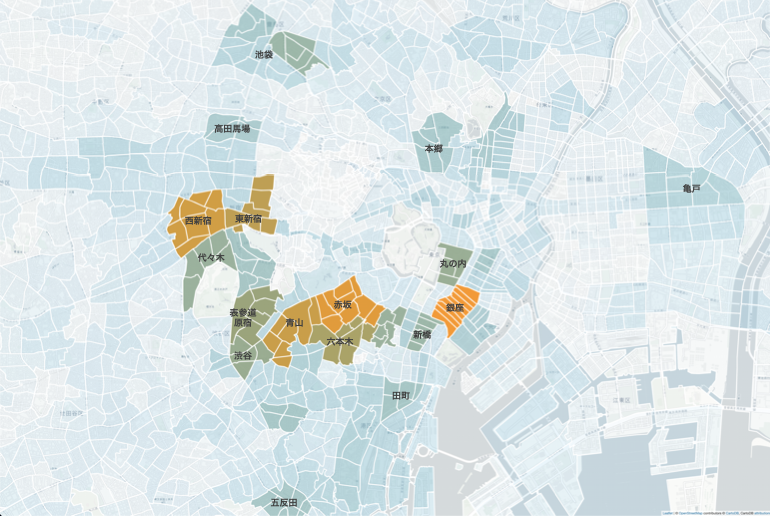
アウトプットはこちら。わかりやすいようにエリア名を記載しています。
読み取れることをまとめると、
- 最も本店登記数が多いのは銀座、赤坂〜六本木〜青山、新宿
- 丸の内、新橋、渋谷、代々木、東池袋は次に多い
- 意外とあるのが本郷、五反田、亀戸
本郷三丁目や五反田は最近スタートアップの集積が著しいですし、亀戸は古くから町工場の多いエリアですね。見える化してみるだけでかなり面白い発見がありそうですね。
渋谷区の法人に注目して分析する
次に、estieでオフィス移転をされる企業のニーズで一番多い、渋谷区に注目してみましょう。
東京都全体1,070,457件のうち、約7.2%に当たる76,678法人が渋谷区に本店を登記していることがわかります。
shibuya = df[df['cityName']=='渋谷区']
shibuya.count()
>>>
sequenceNumber 76678
corporateNumber 76678
process 76678
correct 76678
updateDate 76678
changeDate 76678
name 76678
nameImageId 225
kind 76678
prefectureName 76678
cityName 76678
streetNumber 76678
addressImageId 1110
prefectureCode 76678
cityCode 76678
postCode 76678
addressOutside 0
addressOutsideImageId 0
closeDate 3839
closeCause 3839
successorCorporateNumber 613
changeCause 964
assignmentDate 76678
latest 76678
enName 61
enPrefectureName 57
enCityName 57
enAddressOutside 0
furigana 25984
hihyoji 76678
address 76678
city_id 76678
city 76678
count 76678
dtype: int64
※ こちらには表示されていませんが、このあとのプロットのためにestieのDBを使って緯度経度を追加しておきました。気になる方はYahooやGoogleのAPIを活用して緯度経度を計算してみてください。
細かく地図にプロットしてみる
さあいよいよ渋谷のオフィスを全てプロットしてみます!
全て地図に載せると僕の環境(MacBookPro2019/2.8GHzクアッドコアIntelCorei7/16GBメモリ)ではとても重くなってしまったので、緯度経度でユニーク化しましょう笑
こうすることで7万件以上あったレコード数は、13125件に絞られていますね。
# 緯度経度を小数点第6位まで取得して、組み合わせを'latlon'カラムに入れる
# こんな感じの文字列が入ります'35.641654 139.718522'
shibuya['latlon'] = ['{:.6f} {:.6f}'.format(lat, lon) for lat, lon in zip(shibuya.latitude, shibuya.longitude)]
# 'latlon'でユニーク化して'df_shibuya'を作り、それぞれの数を'count'カラムに入れる
shibuya['count'] = 1
df_shibuya = shibuya.groupby(['latlon'], as_index=False).agg({'count': lambda x: sum(x)})
# 'latlon'から緯度経度を取得して新しいカラムにいれる
df_shibuya['latitude'] = df_shibuya['latlon'].apply(lambda x: x.split(' ')[0])
df_shibuya['longitude'] = df_shibuya['latlon'].apply(lambda x: x.split(' ')[1])
df_shibuya.count()
>>>
latlon 13125
count 13125
latitude 13125
longitude 13125
dtype: int64
foliumを使ってプロットしてみます。
import pandas as pd
import folium
import json
import os
import math
import traceback
import matplotlib.colors as cl
from RW_S3 import *
s3r = S3Reader()
df = pd.read_csv('./tokyo_full.csv')
shibuya = df[df['cityName']=='渋谷区']
shibuya['latlon'] = ['{:.6f} {:.6f}'.format(lat, lon) for lat, lon in zip(shibuya.latitude, shibuya.longitude)]
shibuya['count'] = 1
df_shibuya = shibuya.groupby(['latlon'], as_index=False).agg({'count': lambda x: sum(x)})
df_shibuya['latitude'] = df_shibuya['latlon'].apply(lambda x: x.split(' ')[0])
df_shibuya['longitude'] = df_shibuya['latlon'].apply(lambda x: x.split(' ')[1])
df_shibuya['count_log'] = df_shibuya['count'].apply(lambda x: math.log(x))
def calc_RGB_value(norm_count: float):
'''0-1スケールに圧縮された数値をRGBの16進数表記として返す. 一番安い物件が水色, 高い物件がオレンジとなるようにする
Args:
norm_count (float): 0-1スケールに圧縮された数値
Returns:
str
ex: #54b0c5
'''
R_val = 230 + (255 - 230) * norm_count
G_val = 242 + (150 - 242) * norm_count
B_val = 255 + (0 - 255) * norm_count
return cl.to_hex((R_val / 255, G_val / 255, B_val / 255, 1))
def add_color_col_log(df):
'''colorカラムを追加
Args:
df (pd.DataFrame): e_rentカラムを含むデータフレーム
Returns:
pd.DataFrame
'color'カラムを追加して返す
'''
norm = cl.Normalize(vmin=df['count_log'].min(), vmax=df['count_log'].max())
norm_count_ = [norm(v) for v in df['count_log']] # 企業数を0,1スケールにする
color_ = [calc_RGB_value(norm_count) for norm_count in norm_count_]
df['color'] = color_
return df
df_shibuya = add_color_col_log(df_shibuya)
folium_map_shibuya = folium.Map(
location=[35.731005,139.452995],
zoom_start=9,
tiles='cartodbdark_matter') # マップ作成
def plot_to_m(i):
m = folium.CircleMarker(location=(df_shibuya.latitude[i], df_shibuya.longitude[i]),
radius=0.1,
color=df_shibuya.color[i],
fill=True
)
return m
for i in range(len(df_shibuya)):
try:
m = plot_to_m(i)
m.add_to(folium_map_shibuya)
if i % 100 == 0:
print('=== ' + str(i) + ': success ===')
except:
traceback.print_exc()
print('Completed')
folium_map_shibuya.save('./shibuya.html')
df_shibuya.to_csv('./data/df_shibuya.csv')
アウトプットはこちら。せっかくアドベントカレンダー最終日なのでクリスマスっぽくイルミネーション風にしてみました笑
やはり渋谷駅や恵比寿駅の周辺が濃いオレンジになっており、登記している企業数が多いことが分かります。

渋谷企業の本店登記数が多い建物を特定してみましょう。
df_shibuya.sort_values('count', ascending=False)
>>>
| latlon | count | latitude | longitude |
| 12691 | 35.685713 139.698144 | 982 | 35.685713 | 139.698144 |
| 44 | 35.642363 139.713453 | 584 | 35.642363 | 139.713453 |
| 3216 | 35.655678 139.699734 | 475 | 35.655678 | 139.699734 |
| 3877 | 35.658041 139.698262 | 428 | 35.658041 | 139.698262 |
| 3438 | 35.656455 139.699418 | 410 | 35.656455 | 139.699418 |
| ... | ... ... | ... | ... | ... |
| 6562 | 35.667948 139.705533 | 1 | 35.667948 | 139.705533 |
第1位 🥇ニューステイトメナー(東京都渋谷区代々木2−23−1)
登記 982社
北緯 35.685713度
東経 139.698144度
第2位 🥈恵比寿ガーデンプレイスタワー(東京都渋谷区恵比寿4−61−1)
登記 584社
北緯 35.642363度
東経 139.713453度
第3位 🥉シティコート桜丘(東京都渋谷区桜丘町23-17)
登記 475社
北緯 35.655678度
東経 139.699734度
第4位 🎖渋谷マークシティ(東京都渋谷区道玄坂1-12-1)
登記 428社
北緯 35.658041度
東経 139.698262度
第5位 🎖セルリアンタワー(東京都渋谷区桜丘町26-1)
登記 410社
北緯 35.656455度
東経 139.699418度
もっと大雑把に見てみる
こんな感じで地理情報を整理するとそれだけでなかなか面白い結果が出てきたりするんですね。
今回は少数第6位までを分析することで個別の建物にフォーカスしましたが、例えば以下のようにすることでもう少し大雑把に傾向を捉えることができます(少数第2位までのコード)。
shibuya['latlon'] = ['{:.2f} {:.2f}'.format(lat, lon) for lat, lon in zip(shibuya.latitude, shibuya.longitude)]

おわりに
いかがでしたか?不動産のデータを分析していくときには、緯度経度が何より重要です。また、出てきた結果を現実世界に落とし込んで解釈することで、面白い結果を導けることが分かっていただけたかと思います。
色んなオフィス探してみたいな〜と思われた方はぜひestieをご利用ください!