はじめに
こんにちは.だいみょーじんです.
この記事は,Buddy memory allocator(っぽいもの)作ってみた!の続編であり,第48回自作OSもくもく発表作業会で発表した内容をまとめ,自作OSアドベントカレンダー2025の23日目の記事として公開したものです.
私が開発しているRust製の自作OS,HeliOSにおけるメモリ管理アルゴリズムについて解説します.
ソースコードはこちらをご覧ください.
前回の復習
前回実装したメモリ管理アルゴリズムは,Linuxのページ単位のメモリ管理に採用されている「Buddy memory allocator」に着想を得たものです.
全体的な挙動
アルゴリズムの詳細を説明するより全体的な挙動を見ていただいたほうが分かりやすいと思うので,32KiBのメモリがある状態でメモリの要求と返却が繰り返される様子を見てみましょう.
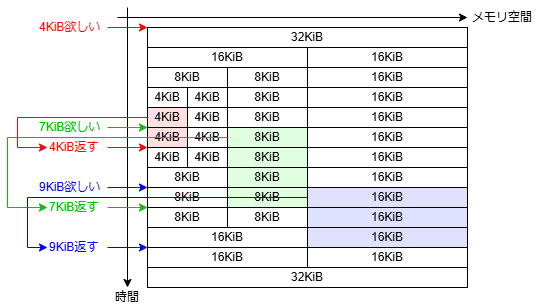
横軸がメモリ空間,縦軸が時間で,上から下に時間が流れています.
- 上図の1段目,32KiBのメモリがある状態で,4KiBのメモリを要求されます.
- 2段目,32KiBは要求に対して大きすぎるので,2つの16KiBに分割します.
- 3段目,16KiBも大きすぎるので,2つの8KiBに分割します.
- 4段目,8KiBも大きすぎるので,2つの4KiBに分割します.
- 5段目,要求と同サイズの4KiBのメモリができたので,左端の4KiBを要求者に与えます.ここでさらに7KiBのメモリが要求されます.
- 6段目,7KiBの要求に対して,中央の8KiBのメモリを要求者に与えます.
- 7段目,5段目で与えた4KiBが返されます.
- 8段目,左端に4KiBの空きメモリが2つ並んでいるので,統合して8KiBの空きメモリとします.ここで9KiBのメモリが要求されます.
- 9段目,9KiBの要求に対して,右端の16KiBのメモリを要求者に与えます.ここで7KiBの要求し対して6段目で与えた8KiBのメモリが返されます.
- 10段目,左に8KiBの空きメモリが2つ並んでいるので,統合して16KiBの空きメモリとします.
- 11段目,9KiBの要求に対して10段目で与えた16KiBのメモリが返されます.
- 12段目,16KiBの空きメモリが2つ並んでいるので,統合して32KiBの空きメモリとします.
このようにBuddy system allocatorでは,2の冪乗の大きさのメモリに対して,それを半分サイズの2つ組(バディ)に分割したり逆に分割されたバディを統合することにより,要求に対して適した大きさのメモリを出し入れします.
二分木による管理
この挙動を実現するための手段として,二分木のデータ構造を使います.
前述した挙動が行われている時,内部で二分木がどのようにメモリを管理していたのかを見てみましょう.
二分木の初期状態は,根ノードのみの状態で,根ノードが32KiBのメモリ全体を指し示しています.

ここで4KiB要求されますが,32KiBのままでは大きすぎるので,根ノードから2つの子ノードを生やすことにより,32KiBを2つの16KiBに分割します.

16KiBでもまだ大きすぎるので,左の子ノードから2つの孫ノードを生やすことにより,16KiBを2つの8KiBに分割します.

8KiBでもまだ大きすぎるので,左端の孫ノードから2つの曾孫ノードをはやすことにより,8KiBを2つの4KiBに分割します.

これで要求と同じサイズの領域ができたので,左端の4KiBを供給します.

次に7KiB要求されます.

7KiBの要求に対して,中央の8KiBの領域を供給します.

次に4KiBが返却されます.

返却された4KiBを解放します.

すると,左端に2つの4KiBの空き領域をそれぞれ指し示している兄弟関係にあるノードができます.
このように二分木で兄弟関係にあるノードのことをバディと呼びます.
バディがどちらも空き領域となった場合,そのバディをそれらの親ノードに吸収させることで,領域を再統合します.

次に9KiB要求されます.

9KiBの要求に対して,右端の16KiBを供給します.

次に7KiBが返却されます.

返却された7KiBを含む中央の8KiBを解放します.

すると,左端の2つの8KiBのバディがどちらも空き領域になります.
このバディを親ノードに吸収させることにより,2つの8KiBの空き領域を1つの16KiBの空き領域に再統合します.

最後に9KiBが返却されます.

返却された9KiBを含む右の16KiBを解放します.

すると,2つの16KiBのバディがどちらも空き領域になります.
このバディを根ノードに吸収させることにより,2つの16KiBの空き領域を1つの32KiBの空き領域に再統合します.

これで,このメモリ管理アルゴリズムの大雑把なイメージは掴めたと思います.
利点
このメモリ管理アルゴリズムにおいて,確保するメモリの場所の決定が二分木上の二分探索となるため,その時間計算量はメモリの大きさ$M$に対して$O\left(\log M\right)$となります.
つまり高速ということです.
実装上の課題
このメモリ管理アルゴリズムには実装上の課題がいくつかあります.
これらの課題をどう解決したかを説明します.
二分木を構成するノードの情報の置き場所
利用可能なメモリ領域の最後の1ページをノードリストとしました.
例えば30MiBのメモリがあったとしましょう.
このメモリ管理アルゴリズムはメモリの大きさが2の冪乗であることを仮定しているため,32MiBのヒープ領域を仮定した上で,最後の2MiBを利用不可領域とすることで,実際のメモリに合わせます.
さらに,その手前の4KiBをノードリストとし,残りの29KiB+1020KiBを利用可能領域とします.

ノードリスト内におけるノードの配置
ノードリストの場所は決まりました.
次はノードリスト内でノードをどのような順番で配置するかという課題があります.
このメモリ管理アルゴリズムでは幅優先順で配置することにしました.
つまり,$n$番目のノードの子ノードは$2n+1$番目および$2n+2$番目に配置します.
例えば下の図のようになります.

上の図においてノード2は分割されていませんが,分割された場合に生成されるであろうノード5,6の場所も最初からノードリスト内に存在します.
こうすることで,親ノードから2つの子ノードを生やす際に,ノードリスト内における子ノードの位置を$O\left(1\right)$で求めることができます.
ノードリストが枯渇したら?
ノードリストが枯渇し,それ以上メモリ分割できなくなったらどうしましょうか?
その場合,下の図のように分割後の2つの子ノードそれぞれが管理担当するメモリ領域の最後の1ページを新しいノートリストにします.

上の図では,まずノード$n$がノード$n$の利用可能領域を指し示している状態にあります.
この利用可能領域を2つに分割するためには,ノード$n$から子ノード$2n+1$および子ノード$2n+2$を生やす必要があります.
しかし,ノードリストの長さが足りず,子ノード$2n+1$および子ノード$2n+2$を作ることができません.
この場合,ノード$n$の利用可能領域を2つに分割し,それぞれの領域の末尾4KiBを新たなノートリストとし,それらのノードリストの先頭に,ノード$2n+1$とノード$2n+2$をそれぞれ配置します.
ノードのデータ構造
ノードは,以下のような情報を持ちます.
struct Node {
state: State, # 状態
range: Range<usize>, # 担当する領域のアドレスの範囲
available_range: Range<usize>, # 担当する領域のうち利用可能な領域のアドレスの範囲
max_length: usize, # 供給できるメモリの最大の大きさ
}
available_rangeは,rangeから利用不可領域やノードリストの領域を取り除いた範囲を表します.
max_lengthは,このメモリ管理アルゴリズムが高速であることの肝となるものです.
詳細はこちらをご覧ください.
ノードの状態は,以下の4通りです.
#[derive(Debug, Eq, PartialEq)]
enum State {
Allocated, # 確保されている
Divided, # 分割されている
Free, # 解放されている
Invalid, # 担当領域全体が利用不可
}
前回のアルゴリズムの問題点
前回のアルゴリズムは,メモリを4KiBより細かく分割できない場合があります.
4KiBのメモリ領域をさらに分割することを考えてみましょう.

ノードリストが枯渇していなければ4KiBのメモリ領域を更に細かく分割することができます.
ノードリストが枯渇している場合,前回のアルゴリズムに従えば末尾の4KiBを新たなノードリストとすることになっています.
しかし,4KiBしかない領域の末尾4KiBを新たなノードリストにしてしまえば,利用可能領域がなくなってしまいます.
この場合,4KiBのメモリ領域をさらに細かく分割することができません.
メモリを十分に細かく分割できない問題は,小さなメモリ要求に対して過剰に大きなメモリが供給される内部断片化の原因になります.
解決策
この問題に対する解決策を考えてみましょう.
Slab allocator
Linuxの場合,2段構えのメモリ管理でこの問題を解決しています.

まずBuddy memory allocatorがメモリをページ単位まで分割します.
Buddy memory allocatorから供給されたページをSlab allocatorが受け取り,ページよりも細かい単位でのメモリ管理を行います.
HeliOSでもSlab allocatorを実装しようかと思いましたが,もうSlab allocatorを実装するのが面倒なのと,せっかく高速なメモリ管理アルゴリズムを作ったのにSlab allocatorを導入したら遅くなってしまうのではという心配があり,もっと良い解決策はないだろうかと考えていました.
可変長ノードリスト
ある時,すごく単純な解決策を思いつきました.
それは,ノードリストの長さを可変にするということです.
ノードリストを最小でノード1個分,最大サイズで4KiBとします.
ノードリストの長さは基本的にはこれまで通り4KiBとしますが,ノードリスト枯渇状態で4KiB以下の領域をさらに分割したい場合は,その領域の後ろ半分を新しいノードリストにします.
そして,そのノードリストの先頭のノードが,前半分の利用可能領域を指し示している状態にします.

こうすれば,ノードのサイズの倍程度の細かさまではメモリを分割できることを保証できます.
ノードを小さくする
今まではノードリストの大きさが,分割を保証できる最小の粒度のボトルネックとなっていました.
しかし,可変長ノードリストを採用した結果,ボトルネックはノードリストの大きさではなくノードの大きさとなります.
ここでもう一度ノードの構造を見てみましょう.
struct Node {
state: State, # 状態
range: Range<usize>, # 担当する領域のアドレスの範囲
available_range: Range<usize>, # 担当する領域のうち利用可能な領域のアドレスの範囲
max_length: usize, # 供給できるメモリの最大の大きさ
}
size_of関数でNode構造体の大きさを確認したところ,48バイトでした.
つまり,48バイト以上の最小の2の冪乗である64バイトの倍の128バイトまでは分割を保証できます.
さらに細かく分割できるようにするためには,このNode構造体の大きさを小さくする必要があります.
まず,修正前のNode構造体において,range.startとavailable_range.startは必ず一致しています.
無駄な情報を省略するため,Rangeを使用しないようにしました.
さらに,ノードが管理するメモリ領域の大きさは必ず2の冪乗なので,大きさをusizeで持つのではなく,大きさの2を底とする対数をlog_size: u8として持たせるようにしました.
struct Node {
index: u8,
state: State,
start: usize,
log_size: u8,
unavailable_tail_size: usize,
max_size: usize,
}
この修正により,Node構造体の大きさを48バイトから32バイトまで圧縮できました.
修正前でも128バイトまでの分割を保証していましたが,さらに64バイトまでの分割を保証できるようになりました.
分割過程の確認
今回の改良版メモリ管理アルゴリズムが,どのようにメモリを分割していくのかを軽く見てみましょう.
4KiBのノードリストは128個のノードを持つことができます.
そして,128個のノードはメモリ領域をだいたい64分割できます.
メモリ領域を64分割するのに必要なノードの個数は127個なので,実際の4KiBのノードリストはメモリを64分割するのに加えて128分割の領域をたったひとつだけ持つのですが,今回は大雑把に計算するために64分割ということにしておきます.
例として,1GiBのメモリを考えましょう.

このように,ちゃんと64バイトまで分割できています.
まとめ
- 前回実装したBuddy memory allocatorに着想を得たメモリ管理アルゴリズム
- メモリ全体の大きさ$M$に対して$O\left(\log M\right)$でメモリを確保解放できる
- 4KiBより細かく分割できる保証がないため,内部断片化が大きい
- 課題解決のためSlab allocatorの導入を検討したが…
- 現状のアルゴリズムの強みである速度が失われる可能性
- 単純にSlab allocatorを実装するのが面倒
- ノードリストの大きさを可変にすることで4KiB以下の領域も分割可能に
- ノードの大きさを小さくすることで64バイトまで分割できることを保証
- Slab allocatorを導入せず,Buddy memory allocatorベースのアルゴリズムだけで,速く,かつきめ細かいメモリ管理が可能に