お盆休みも佳境ですね。
突然ですが、女優の広瀬アリスさんと千葉ロッテマリーンズのマーティン選手の顔が激似らしく、広瀬アリスさん本人が公認コメントを出すなど、最近、巷では話題になっているみたいです。(当該ニュース)
そこで、今回は本当に広瀬アリスさんとマーティン選手が似ているのか画像認識で検証してみました。
学習環境
Window 10
python 3.7.6
jupyter lab
参考にさせていただいたページ
今回の実施内容は下記のページを参考(というより、ほぼコピペ)したものとなっています。
ありがとうございました。
参考ページ: Kerasを使って爆笑問題の顔認証をしてみた。
なお、今回はCドライブ直下で作業をしており、ディレクトリのパスは絶対パスで定義するようにしています。
実施内容
画像収集部分
まずは学習用の画像を集めます。
ここはicrawlerを使ってサクッと集めます。
今回はコマンドライン引数は使用せず、パス名と検索ワードをpythonのコード内に埋め込んでいます。
収集枚数は300枚と設定していますが、そこまで集められていません。
# -*- coding:utf-8 -*-
from icrawler.builtin import BingImageCrawler
import sys
import os
# マーティン選手の画像収集
filepath = "C:\\MartinVSAris\\data\\Martin"
search = "マーティン ロッテ"
# 広瀬アリスさんの画像収集
# filepath = "C:\\MartinVSAris\\data\\Aris"
# search = "広瀬アリス"
if not os.path.isdir(filepath):
os.makedirs(filepath)
crawler = BingImageCrawler(storage = {"root_dir" : filepath})
crawler.crawl(keyword = search, max_num = 300)
集めた結果はこんな感じです。
ここから、それぞれ別人の画像であったり、人物ではない画像があったりしたので、それらは削除しています。ただ、目視でやっているので、広瀬アリスさんの方には妹の広瀬すずさんが混じっている可能性があります。(そっちを問題にした方が良かったかも笑)
画像から顔部分の切り抜き
先ほど集めた広瀬アリスさんとマーティン選手の画像から顔部分を切り抜いて保存します。
参考ページと違って、今回は顔検出にdlibを使用しています。
import glob
import os
import dlib
import cv2
def face_detect(img_list,save_dir):
# 顔検出の識別器
detector = dlib.get_frontal_face_detector()
# 候補画像を識別器にかける
for (i,img_path) in enumerate(img_list):
#
print(img_path) #画像のパス名表示
index = i + 1 #保存する画像のファイル名用
# 画像読み込み
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
# 顔領域の座標情報取得
cv_img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
faces = detector(cv_img, 1)
# 顔画像生成
img_count = 1
for face in faces:
# 候補画像サイズ取得
height, width = img.shape[:2]
# 顔領域の座標点取得
top = face.top()
bottom = face.bottom()
left = face.left()
right = face.right()
# 顔を認識しない場合は無視する
if not top < 0 and left < 0 and bottom > height and right > width:
print("No facial recognition.")
img_count += 1
break
else:
# 顔領域トリミング
dst_img = img[top:bottom, left:right]
# 顔画像サイズ正規化して保存
face_img = cv2.resize(dst_img, (64,64))
new_img_name = save_dir + '//' + str(index) + '.jpg'
cv2.imwrite(new_img_name, face_img)
img_count += 1
del top,bottom,left,right
names = ['Martin','Aris']
out_dir = "C:\\MartinVSAris\\faces\\"
os.makedirs(out_dir, exist_ok = True)
for i in range(len(names)):
in_dir = "C:\\MartinVSAris\\data\\" + names[i] + "\\*.jpg"
save_dir = out_dir + names[i]
in_jpg = glob.glob(in_dir)
os.makedirs(out_dir + names[i], exist_ok = True)
# print(in_jpg)
print(len(in_jpg)) #格納されている画像枚数を表示
face_detect(in_jpg,save_dir) #顔検出の関数実行部分
上記のコードを回した結果、こんな感じになりました。
広瀬アリスさん

マーテイン選手

似てるのか似てないのかはなんとも言えません...
画像を訓練データとテストデータにわける
今回は参考ページでの訓練データとテストデータを分ける部分と訓練データの水増しをする部分を一つのコードにして実施しました。
なお、集められた画像データが少なかったので、参考ページよりも画像の回転角度を増やしています。
import shutil
import random
import glob
import os
import cv2
import glob
from scipy import ndimage
names = ['Martin','Aris']
# フォルダ作成
os.makedirs("C:\\MartinVSAris\\test", exist_ok=True)
os.makedirs("C:\\MartinVSAris\\train", exist_ok=True)
for name in names:
in_dir = "C:\\MartinVSAris\\faces\\" + name + "\\*"
in_jpg=glob.glob(in_dir)
img_file_name_list=os.listdir("C:\\MartinVSAris\\\faces\\" + name + "\\")
#img_file_name_listをシャッフル、そのうち2割をtest_imageディテクトリに入れる
random.shuffle(in_jpg)
os.makedirs("C:\\MartinVSAris\\test\\" + name, exist_ok=True)
for t in range(len(in_jpg)//5):
shutil.move(str(in_jpg[t]), "C:\\MartinVSAris\\test\\" + name)
in_jpg=glob.glob(in_dir)
img_file_name_list=os.listdir("C:\\MartinVSAris\\faces\\" + name + "\\")
os.makedirs("C:\\MartinVSAris\\train\\" + name, exist_ok=True)
out_dir = "C:\\MartinVSAris\\train\\" + name
for i in range(len(in_jpg)):
img = cv2.imread(str(in_jpg[i]))
for ang in [-30,-20,-10,0,10,20,30]:
img_rot = ndimage.rotate(img,ang)
img_rot = cv2.resize(img_rot,(64,64))
fileName=os.path.join(out_dir,str(i)+"_"+str(ang)+".jpg")
cv2.imwrite(str(fileName),img_rot)
#閾値の変化
img_thr = cv2.threshold(img_rot, 100, 255, cv2.THRESH_TOZERO)[1]
fileName=os.path.join(out_dir,str(i)+"_"+str(ang)+"thr.jpg")
cv2.imwrite(str(fileName),img_thr)
#ぼかし
img_filter = cv2.GaussianBlur(img_rot, (5, 5), 0)
fileName=os.path.join(out_dir,str(i)+"_"+str(ang)+"filter.jpg")
cv2.imwrite(str(fileName),img_filter)
学習
あとは学習するのみです。
import keras
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.layers.core import Dense, Dropout, Activation, Flatten
import numpy as np
from sklearn.model_selection import train_test_split
from PIL import Image
import glob
names = ['Martin','Aris']
image_size = 50
X_train = []
y_train = []
for index, name in enumerate(folder):
dir = "C:\\MartinVSAris\\train\\" + name
files = glob.glob(dir + "\\*.jpg")
for i, file in enumerate(files):
image = Image.open(file)
image = image.convert("RGB")
image = image.resize((image_size, image_size))
data = np.asarray(image)
X_train.append(data)
y_train.append(index)
X_train = np.array(X_train)
y_train = np.array(y_train)
folder = ['Martin','Aris']
image_size = 50
X_test = []
y_test = []
for index, name in enumerate(folder):
dir = "C:\\MartinVSAris\\test\\" + name
files = glob.glob(dir + "\\*.jpg")
for i, file in enumerate(files):
image = Image.open(file)
image = image.convert("RGB")
image = image.resize((image_size, image_size))
data = np.asarray(image)
X_test.append(data)
y_test.append(index)
X_test = np.array(X_test)
y_test = np.array(y_test)
X_train = X_train.astype('float32')
X_train = X_train / 255.0
X_test = X_test.astype('float32')
X_test = X_test / 255.0
# 正解ラベルの形式を変換
y_train = np_utils.to_categorical(y_train, 2)
# 正解ラベルの形式を変換
y_test = np_utils.to_categorical(y_test, 2)
# CNNを構築
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',input_shape=X_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(2))
model.add(Activation('softmax'))
# コンパイル
model.compile(loss='categorical_crossentropy',optimizer='SGD',metrics=['accuracy'])
epochs = 100
history = model.fit(X_train, y_train, epochs=epochs)
print(model.evaluate(X_test, y_test))
model.save("C:\\MartinVSAris\\learn_model.h5")
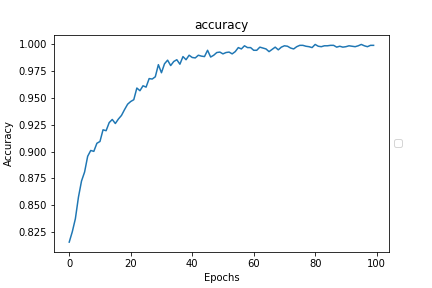
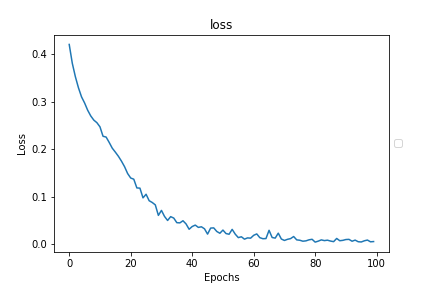
一応、正解率と損失関数をグラフ化して確認しておきましょう。
import matplotlib.pyplot as plt
%matplotlib inline
x = range(epochs)
fig1 = plt.figure()
plt.plot(x, history.history['accuracy'])
plt.title("accuracy")
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.show()
fig1.savefig("accuracy.png")
fig2 = plt.figure()
plt.plot(x, history.history['loss'])
plt.title("loss")
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.show()
fig2.savefig("loss.png")
下記の2つの図が今回の学習結果の正解率と損失関数ですが、正解率は十分に1に近づいており、損失関数も0に近づいているので、問題なく学習ができているといえます。
判別結果
では、判別をしてみましょう。コードはこちらです。
from keras.models import load_model
import numpy as np
from keras.preprocessing.image import img_to_array, load_img
jpg_name = 'C:\\hanbetsu.jpg'
my_model='C:\\MartinVSAris\\learn_model.h5'
model=load_model(my_model)
img_path = (jpg_name)
img = img_to_array(load_img(img_path, target_size=(50,50)))
img_nad = img_to_array(img)/255
img_nad = img_nad[None, ...]
label = ['Martin','Aris']
pred = model.predict(img_nad, batch_size=1, verbose=0)
score = np.max(pred)
pred_label = label[np.argmax(pred[0])]
print('name:',pred_label)
print('score:',score)
上記のコードを使って学習に使用していないデータの判別をしてみます。(画像サイズがバラバラですみません)
まずは広瀬アリスさん

name: Aris
score: 0.9999968
次にマーティン選手

name: Martin
score: 1.0
そりゃそうですよね笑。しっかりと判別できています。
また、広瀬アリスさんが公認コメントを出した時のマーティン選手の顔を判別させてみましたが、

name: Martin
score: 0.9427792
マーティン選手と判別していますが、スコアは先ほどよりも減少しているので広瀬アリスさんの要素もあったと言えると思います。
ちなみに画像認識的にどうなのかって話はあると思いますが、二人の顔を比較した画像をそのままそのまま判別させてみると、

name: Martin
score: 1.0
マーティン選手の方が優勢でした笑
最後にですが、妹の広瀬すずさんの画像を認識させてみました。

name: Martin
score: 0.99986243
...(笑)
まとめ
今回はKerasを使った画像認識で広瀬アリスさんとマーティン選手の顔認識を実施しました。
集めた画像の枚数が少ないなど問題はいろいろありますが、ある程度の両者を識別できる程度のモデルを作成することはできました。
このように楽しみながら勉強できるのはいいですね。