クラスタリングは、教師なし学習の代表的なタスクの一つで、「正解ラベルのないデータを、似たもの同士でグループ分けする」手法です。
本記事では、初学者にもわかりやすいように、クラスタリングの基本的な考え方から、k-means法・階層クラスタリング・DBSCANといった代表的な手法を、図解とPython実装付きで丁寧に解説します。
「教師あり学習は知っているけど、教師なし学習はよく分からない」という方も、「とりあえずクラスタリングって何?から始めたい」という方も、この記事を読めば、クラスタリングの基本をしっかりと理解できるはずです。
本記事では以下の流れで説明する。
1 k-means法
教師なし学習の手法の1つ目として、最もよく知られているクラスタリングアルゴリズムであるk-means法(k-means algorithm)を紹介します。k-means法は実装が簡単かつ、計算効率が良い点から人気のアルゴリズムです。クラスタリングを使うと類似したオブジェクトをグループにまとめることができるため、実務ではレコメンデーションのベースとして、異なるテーマの文書、音楽、映画を同じグループにまとめることや、共通の購入履歴に基づいて同じような関心を持つ顧客を見つけることが挙げられます。
クラスタリングアルゴリズムは以下のようなカテゴリに分けられます。
- プロトタイプベース(prototype-based)
- 階層的(hierarchical)
- 密度ベース(density-based)
k-meansはプロトタイプベースの手法に該当します。プロトタイプベースクラスタリングは、各クラスタがプロトタイプで表されることを意味します。プロトタイプは通常、セントロイド(特徴量が連続値の場合、類似する点の中心)かメドイド(特徴量がカテゴリ値の場合、最も代表的な点)のどちらかになります。
k-means法の具体的な手順は以下のようになります。
1. クラスタの中心の初期値として、データ点からk個のセントロイドをランダムに選び出す
2. 各データ点を最も近いセントロイド$\mu^{(j)}$に割り当てる
\mu^{(j)}, j \in \lbrace 1, ..., k \rbrace
ここで、データ点($x^{(i)}$)とセントロイド($\mu^{(j)}$)の距離は以下のユークリッド距離の2乗で計算されます。
d(\mathbf{x}, \mathbf{\mu})^2 = \sum^n_{i=1} \sum^k_{j=1}(x^{(i)} - \mu^{(j)})^2 = ||\mathbf{x} - \mathbf{\mu}||^2_2
3. セントロイドに割り当てられたデータ点の中心にセントロイドを移動する
4. データ点へのクラスタの割り当てが変化しなくなるか、ユーザー定義の許容値またはイテレーションの最大回数に達するまで手順2~3を繰り返す
k-means法で解く最適化問題はクラスタ内誤差平方和(SSE: Sum of Squared Errors)を最小化することです。クラスタ内誤差平方和は以下の式で表されます。
SSE = \sum^n_{i=1} \sum^k_{j=1} w^{(i, j)}||x^{(i)} - \mu^{(j)}||^2
ここで、$\mu^{(j)}$はクラスタjの中心点(セントロイド)であり、データ点$x^{(i)}$がクラスタ内に存在する場合は$w^{(i, j)}$=1、そうではない場合は、$w^{(i, j)}$=0となります。
k-meansの問題点
- クラスタが球状(円状)として識別できる(高次元になると視認することができないので、確認できない)
- クラスタの個数kを指定する必要がある
- 空になるクラスタが存在する可能性がある
- クラスタがオーバーラップしない
- 各クラスタに少なくとも1つのデータが入る必要がある
この2つ目の問題点である、kを決める方法として、エルボー法(elbow method)とシルエット図(silhouette plot)があります。また、後で紹介する階層的クラスタリングアルゴリズムと、密度ベースのアルゴリズムでは事前にクラスタの個数を指定する必要がなく、データセットが球状である必要がないです。
1.1 k-means法の実装
k-meansを行うための簡単なデータを作成します。本来の教師なし学習ではクラスタの数やクラスラベルは不明ですが、ここでは演習のため3つのグループを持つデータをあらかじめ作成しておきます。
データを作成するコード
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
# サンプルデータの生成
X, y = make_blobs(
n_samples=300, # サンプル数
n_features=2, # 特徴量の数(2次元データ)
centers=3, # クラスタの数
cluster_std=1, # クラスタの標準偏差
random_state=42
)
# データの可視化
plt.figure(figsize=(10, 6))
plt.scatter(X[:, 0], X[:, 1])
plt.title('Sample Data')
plt.show()
作成されたデータ
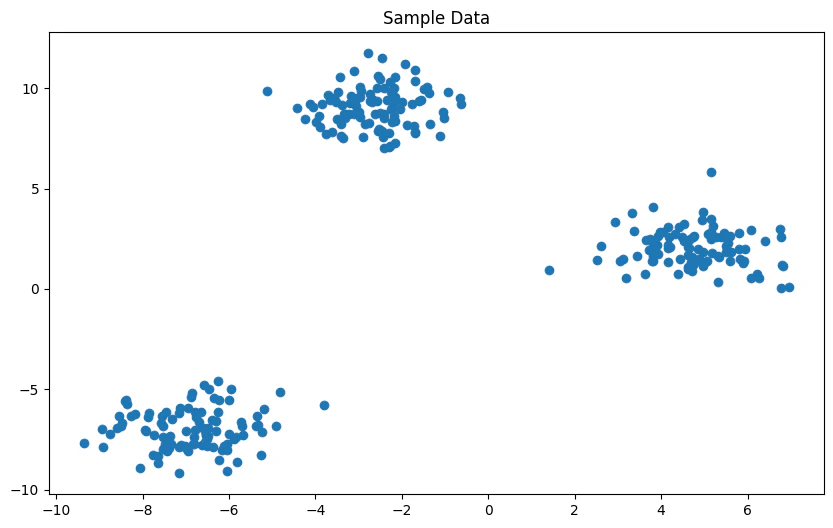
ここからクラスタの数(k)を3にして、k-meansの実装を行なっていきます。
from sklearn.cluster import KMeans
# K-meansクラスタリングの実行
kmeans = KMeans(n_clusters=3, random_state=42)
kmeans.fit(X)
# クラスタリング結果の可視化
plt.figure(figsize=(10, 6))
# 各クラスタを個別にプロット
for i in range(3):
mask = kmeans.labels_ == i
plt.scatter(X[mask, 0], X[mask, 1],
label=f'Cluster {i+1}',
cmap='viridis')
# クラスタ中心のプロット
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1],
marker='x', s=200, linewidths=3, color='r', label='centroids')
plt.title('K-means Clustring')
plt.legend()
plt.show()

1.2 k-means++法
通常のk-meansでは乱数を使って、ランダムにセントロイドの初期値を設定していました。このようなアプローチでは、セントロイドの初期値が不適切であるために、クラスタリングがうまくいかなかったり、収束に時間がかかったりすることがあります。そこで、セントロイドの初期値を最適に配分しようとすることにした手法が**k-means++**です。詳しい計算式はここでは省略しますが、最初のセントロイドをお互いに離れた位置に配置することで、適切なセントロイドの初期配置を設定します。scikit-learnのKMeansオブジェクトでinitパラメータに対する引数として'auto'もしくは、'k-means++'を指定することで実装できます。
1.3 ハード/ソフトクラスタリング
ハードクラスタリングとは、先に見たk-meansやk-means++などの手法で、データ点がそれぞれちょうど1つのクラスタに割り当てられるアルゴリズムです。一方、データ点を1つ以上のクラスタに割り当てる手法はソフトクラスタリングもしくはファジークラスタリングと呼ばれ、代表例として、ファジーC-平均法(Fuzzy C-Means)やSoft k-means、Gaussian Mixture Model(GMM)などがあります。
ハードクラスタリングと比べて、ソフトクラスタリングはクラスタ境界が曖昧になるため、柔軟性が高く、外れ値にも強いとされています。その一方、ハードクラスタリングようりも解釈が複雑になることがあります。
ハードクラスタリングでの割り当てでは、データ点$\mathbf{x}$の所属関係を2値の疎ベクトルで表現できます。クラスタk=3、各クラスタのインデックス$j \in\lbrace 1, 2, 3 \rbrace$であるとすれば、以下のように書けます。
\left[
\begin{aligned}
x \in \mu^{(1)} \rightarrow w^{(i, j)} = 0 \\
x \in \mu^{(2)} \rightarrow w^{(i, j)} = 1 \\
x \in \mu^{(3)} \rightarrow w^{(i, j)} = 0 \\
\end{aligned}
\right]
対して、ソフトクラスタリングでは、該当するクラスタへの所属確率を使って表現されます。
\left[
\begin{aligned}
x \in \mu^{(1)} \rightarrow w^{(i, j)} = 0.1 \\
x \in \mu^{(2)} \rightarrow w^{(i, j)} = 0.85 \\
x \in \mu^{(3)} \rightarrow w^{(i, j)} = 0.05 \\
\end{aligned}
\right]
Soft k-means法の手順は、通常のk-meansと似ていますが、目的関数が異なり以下のように書けます。
\mathbf{J}_m = \sum^n_{i=1} \sum^k_{j=1} w^{(i, j)^m}||x^{(i)} - \mu^{(j)}||^2_2
ここで、$w^{(i, j)}$は2値($w^{(i, j)} \in\lbrace 0, 1 \rbrace$)ではなく、クラスタ所属確率を表す実数値です。ここで、$m$(1以上の任意の数、通常はm=2)は、ファジー性の度合いを制御するファジー係数です。mの値が大きいほど、クラスタ所属確率$w^{(i, j)}$は小さくなり、よりファジーなクラスタ(クラスタの境界があいまい)になります。
実務で最も利用されるケースが多いとされるソフトクラスタリングはGMM(Gaussian Mixture Model)です。GMMは実装が容易かつ確率的な解釈ができ、柔軟性も高いという特徴から、より利用されるモデルです。実装は、scikit-learnの GaussianMixtureオブジェクトで簡単に実装できます。
1.4 クラスタ数kの決め方
k-meansなどのクラスタリング手法のいくつかでは、クラスタリングの個数が分からないにも関わらず、クラスタリングの個数kを事前に指定する必要があります。この節では、クラスタリング個数kを決める方法を紹介します。
理想的なクラスタリングの数は、k-meansの目的関数でもあるクラスタ内誤差平方和(歪み)(SSE)が最小になるものです。KMeansモデルを適合した後は、以下のコードを使うことで、簡単にSSEを計算することができます。
print("Distortion: {:.2f}".format(kmeans.inertia_))
# Distortion: 566.86
1.4.1 エルボー法
理論的にはkの数が大きくなるにつれて、データ点がそれらの割り当て先であるセントロイドに近づくため、SSEの値は小さくなります。そこで、「どこまでkを増やせば効果があるか」を可視化するための手法がエルボー法です。すなわち、以下のようなグラフで歪みが急速に増える点(エルボー)、この例だと3を使って、事前のクラスター数を決定する手法です。
# エルボー法による最適なクラスタ数の探索
inertias = []
K = range(1, 10)
for k in K:
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(X)
inertias.append(kmeans.inertia_)
# エルボー法の可視化
plt.figure(figsize=(10, 6))
plt.plot(K, inertias, 'o-')
plt.xlabel('No. of Clusters (k)')
plt.ylabel('Distortion (Inertia)')
plt.title('Elbow Method for Optimal K')
plt.grid(True)

1.4.2 シルエット分析
もう1つのクラスタ数を決定する手法としては、シルエット分析(Silhouette Analysis)があります。シルエット分析はk-means以外の手法にも利用できる手法です。この方法では、クラスタの凝集度と乖離度を元に計算されるシルエット係数が最も大きいkを最適なクラスタ数が考えます。シルエット係数は以下のように計算されます。
1. クラスタの凝集度$a(i)$(クラスタ内での他の点との平均距離)を計算する。これは、同一クラスタのデータ点$\mathbf{x}_i$と他のデータ点との平均距離として計算する。
$|C_i|$を$\mathbf{x}_i$ が属しているクラスタのデータ点数として
a^{(i)} = \frac{1}{|C_i| - 1} \sum_{\substack{j \in C_i \\ j \neq i}} \| \mathbf{x}_i - \mathbf{x}_j \|
2. 最も近いクラスタから乖離度$b(i)$(一番似ている他のクラスタとの平均距離)を計算する。データ点$\mathbf{x}_i$ と最も近くにあるクラスタ内の全データとの平均距離として計算する。
b(i) = \min_{k \ne C_i} \left( \frac{1}{|C_k|} \sum_{j \in C_k} \| \mathbf{x}_i - \mathbf{x}_j \| \right)
3. シルエット係数は「分離度と凝集度の差」を「より大きい方」で割ったもの
s(i) = \frac{b(i) - a(i)}{\max\{a(i), b(i)\}}
シルエット係数は-1~1の値で表され、値が大きい方が適切にクラスタに所属していることを表します。そのため、kの値を検討する際は、全データに対してシルエット係数を計算し、その平均値を比較することで決めます。
以下に、今回のサンプルデータにおけるシルエット係数の平均値がどう変化するかをプロットし、最適なクラスタ数(シルエット係数の平均が最大になるk)を決定します。
from sklearn.metrics import silhouette_score
# シルエット係数の計算
silhouette_scores = []
K = range(2, 10) # シルエット係数は2クラス以上で計算可能
for k in K:
kmeans = KMeans(n_clusters=k, random_state=42)
cluster_labels = kmeans.fit_predict(X)
silhouette_avg = silhouette_score(X, cluster_labels)
silhouette_scores.append(silhouette_avg)
# シルエット係数の可視化
plt.figure(figsize=(10, 6))
plt.plot(K, silhouette_scores, 'o-')
plt.xlabel('No. of Clusters (k)')
plt.ylabel('Silhouette Score')
plt.title('Silhouette Analysis for Optimal K')
plt.grid(True)
plt.show()
# 最適なクラスタ数の表示
optimal_k = K[np.argmax(silhouette_scores)]
print(f'最適なクラスタ数: {optimal_k}')
# 最適なクラスタ数: 3

さらに、k=3とk=2としたときの全データ点のシルエット係数をプロットしてみましょう。
k=3の時のシルエット図を可視化するコード
# k=3の時のシルエット図を可視化
from sklearn.metrics import silhouette_samples
# kmeansのクラスタ数を3に設定
kmeans = KMeans(n_clusters=3, random_state=42)
kmeans.fit(X)
# シルエット係数の計算
silhouette_scores = silhouette_samples(X, kmeans.labels_)
# シルエット係数の可視化
y_ax_lower, y_ax_upper = 0, 0
yticks = []
for i, c in enumerate(np.unique(kmeans.labels_)):
c_silhouette_values = silhouette_scores[kmeans.labels_ == c]
c_silhouette_values.sort()
size_cluster_i = c_silhouette_values.shape[0]
y_ax_upper += size_cluster_i
color = colors[i]
plt.fill_betweenx(np.arange(y_ax_lower, y_ax_upper), 0, c_silhouette_values,
facecolor=color, edgecolor=color, alpha=0.7)
yticks.append(y_ax_lower + (y_ax_upper - y_ax_lower) / 2)
y_ax_lower += size_cluster_i
yticks = np.array(yticks)
yticks[yticks == 0] = 1
# 軸ラベルの設定
plt.xlabel('Silhouette Coefficient')
plt.ylabel('Cluster')
plt.yticks(yticks, [f'{i+1}' for i in range(len(np.unique(kmeans.labels_)))])
k=2の時のシルエット図を可視化するコード
# k=2の時のシルエット図を可視化
from sklearn.metrics import silhouette_samples
# kmeansのクラスタ数を2に設定
kmeans = KMeans(n_clusters=2, random_state=42)
kmeans.fit(X)
# シルエット係数の計算
silhouette_scores = silhouette_samples(X, kmeans.labels_)
# シルエット係数の可視化
y_ax_lower, y_ax_upper = 0, 0
yticks = []
for i, c in enumerate(np.unique(kmeans.labels_)):
c_silhouette_values = silhouette_scores[kmeans.labels_ == c]
c_silhouette_values.sort()
size_cluster_i = c_silhouette_values.shape[0]
y_ax_upper += size_cluster_i
color = colors[i]
plt.fill_betweenx(np.arange(y_ax_lower, y_ax_upper), 0, c_silhouette_values,
facecolor=color, edgecolor=color, alpha=0.7)
yticks.append(y_ax_lower + (y_ax_upper - y_ax_lower) / 2)
y_ax_lower += size_cluster_i
yticks = np.array(yticks)
yticks[yticks == 0] = 1
# 軸ラベルの設定
plt.xlabel('Silhouette Coefficient')
plt.ylabel('Cluster')
plt.yticks(yticks, [f'{i+1}' for i in range(len(np.unique(kmeans.labels_)))])
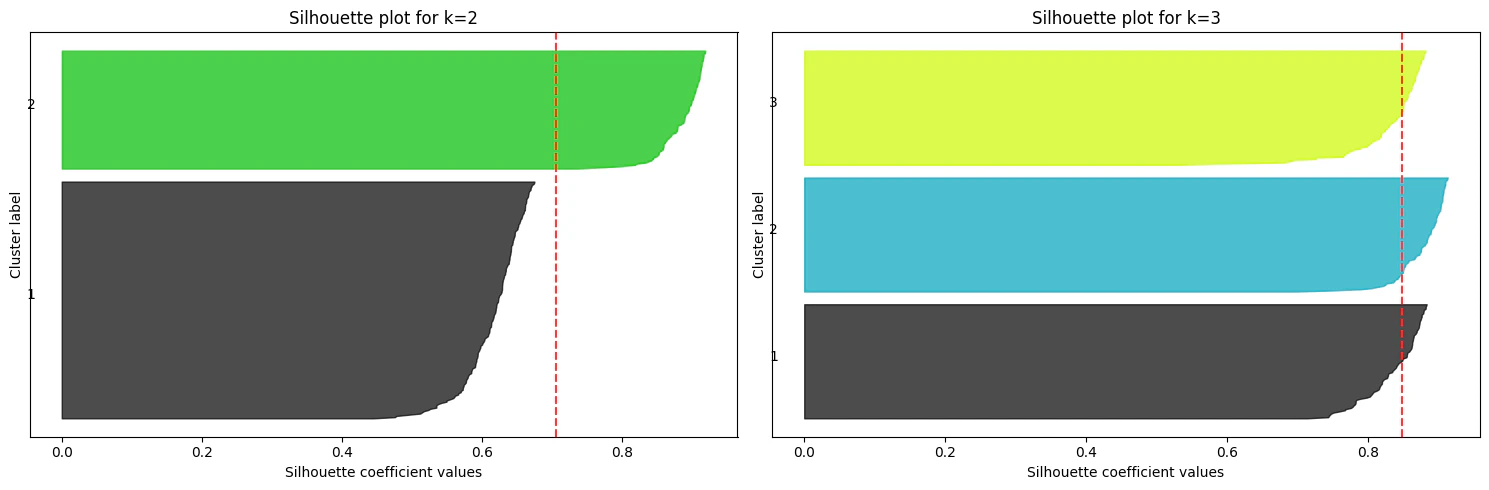
この図から、k=2のシルエット図はk=3の時と比べて、各クラスタごとのシルエット図の幅がバラバラで、シルエット係数の値も小さいことが分かります。
2 階層木によるクラスタリング
ここまでは、プロトタイプベースのクラスタリングアルゴリズムに関しての説明をしてきました。ここからは、階層的クラスタリングについて説明します。階層的アルゴリズムの利点として、樹形図がプロットできることと、クラスタ数を事前に指定する必要がないことが挙げられます。樹形図は二分木のクラスタリングアルゴリズムを可視化したもので、結果の解釈を助ける役割を持ちます。
階層的クラスタリングには、以下の2つのアプローチがあります。
- 分割型(divisive):全データセットを含む1つのクラスタを定義し、すべてのクラスタにデータ点が1つだけ含まれた状態になるまで、クラスタをより小さなクラスタに分割する方法
- 凝集型(agglomerative):個々のデータ点を1つのクラスタとして扱い、クラスタが1つのクラスタになるまで、最も近くにある2つのクラスタをマージしていく方法
分割型は、特定のケースを除いて実務で用いられるのは稀なので、本記事では凝集型についてのみ解説します。
2.1 凝集型階層的クラスタリング
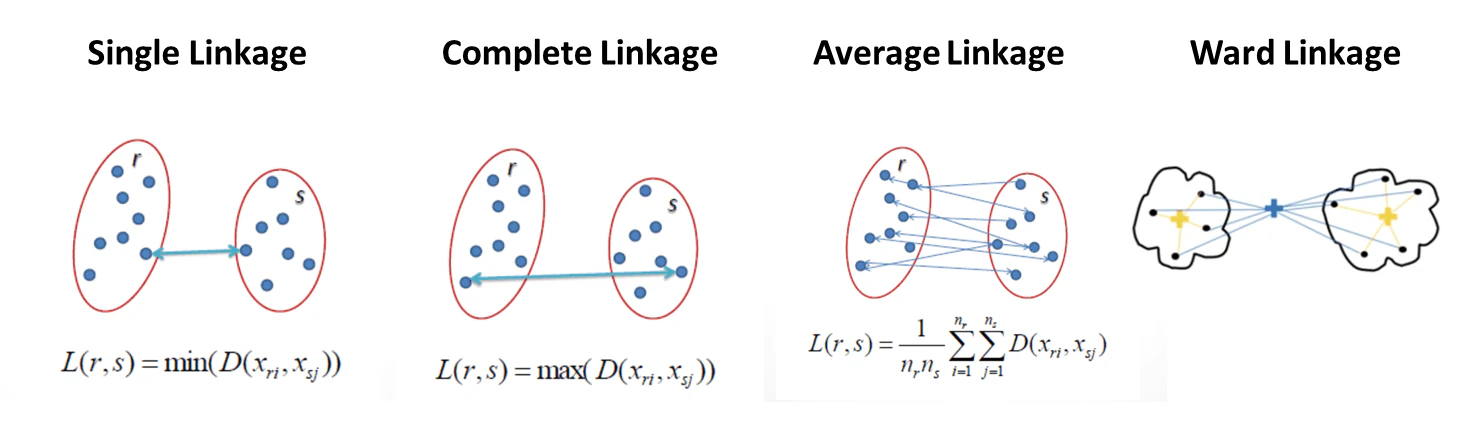
凝集型階層的クラスタリング(Agglomerative Clustering)においては、クラスタ同士をマージする際、クラスタ間の距離を最小となるような方法で2つのクラスタをマージします。その際、クラスタ間の距離の計算に用いられる標準アルゴリズムとして、以下の4つがあります。
- 単連結法(Single Linkage):クラスタペアごとの最も類似度の高いメンバー同士を比較する
- 完全連結法(Complete Linkage):クラスタペアごとの最も類似度の低メンバー同士を比較する
- 平均連結法(Average Linkage):クラスタペアに含まれるすべてのメンバー間の距離の平均を比較する
- ウォード連結法(Ward's Linkage):クラスタ内誤差平均(SSE)の合計の増加量が最小となるペアをマージ
ウォード連結法はクラスタの形状が自然で安定しており、ノイズや外れ値に強いため最もよく使われる連結手法です。
2.1.1 凝集型階層的クラスタリングの実装
まず、実装で使うランダムなデータを作成します。今回は3つの特徴量(X, Y, Z)をもつ5つのデータ点(ID_0 ~ ID_4)を扱います。
演習用のデータを作成
import pandas as pd
# サンプルデータの作成
np.random.seed(42)
X = np.random.random_sample([5, 3])*10
# データフレームの作成
df = pd.DataFrame(X, columns=['X', 'Y', 'Z'],
index=['ID_0', 'ID_1', 'ID_2', 'ID_3', 'ID_4'])
print("サンプルデータ:")
print(df)
# サンプルデータ:
# X Y Z
# ID_0 3.745401 9.507143 7.319939
# ID_1 5.986585 1.560186 1.559945
# ID_2 0.580836 8.661761 6.011150
# ID_3 7.080726 0.205845 9.699099
# ID_4 8.324426 2.123391 1.818250
scikit-learnのAgglomerativeClusteringオブジェクトを使うと、簡単に実装できます。また、linkageパラメータを指定することで、様々な連結手法を指定できます。
# 凝集型階層的クラスタリングの実装
from sklearn.cluster import AgglomerativeClustering
# 凝集型階層的クラスタリングの実行
agg_clustering = AgglomerativeClustering(n_clusters=3, metric='euclidean', linkage='ward')
cluster_labels = agg_clustering.fit_predict(X)
for i, label in enumerate(cluster_labels):
print(f"{df.index[i]}: クラスタ {label}")
# ID_0: クラスタ 0
# ID_1: クラスタ 1
# ID_2: クラスタ 0
# ID_3: クラスタ 2
# ID_4: クラスタ 1
# 樹形図をプロット
from scipy.cluster.hierarchy import dendrogram, linkage
# 凝集型階層的クラスタリングの実行
Z = linkage(X, metric='euclidean', method='ward')
# 樹形図をプロット
plt.figure(figsize=(10, 5))
dendrogram(Z, labels=df.index, orientation='top', distance_sort='descending', show_leaf_counts=True)
plt.tight_layout()
plt.show()
# ヒートマップをプロット
import seaborn as sns
# ヒートマップの作成
sns.heatmap(X, annot=True, cmap='viridis', cbar=False)
plt.show()
# ヒートマップと樹形図を組み合わせた可視化
fig = plt.figure(figsize=(15, 5))
# 樹形図のプロット(左側)
ax1 = fig.add_axes([0.09, 0.1, 0.2, 0.6])
dendrogram(Z, orientation='left', labels=df.index)
ax1.set_xticks([])
# ヒートマップのプロット(右側)
ax2 = fig.add_axes([0.3, 0.1, 0.6, 0.6])
im = ax2.imshow(X, aspect='auto', cmap='viridis')
# 各セルに値を表示
for i in range(X.shape[0]):
for j in range(X.shape[1]):
ax2.text(j, i, f'{X[i,j]:.2f}',
ha='center', va='center',
color='white' if X[i,j] > 3 else 'black')
# カラーバーの追加
axcolor = fig.add_axes([0.91, 0.1, 0.02, 0.6])
plt.colorbar(im, cax=axcolor)
# 軸ラベルの設定
ax2.set_xticks(range(X.shape[1]))
ax2.set_xticklabels(['X', 'Y', 'Z'])
ax2.set_yticks(range(X.shape[0]))
ax2.set_yticklabels(df.index)
plt.show()



3. DBSCAN
最後に密度ベースのクラスタリングアルゴリズムの代表例として、DBSCAN(Density-based Spatial Clustring of Applications with Noise)を解説します。DBSCANでは、データ点の局所的な密度に基づいてクラスタラベルを割り当てます。
DBSCANアルゴリズムでは、次の条件に基づいて各データ点に特別なラベルを割り当てます。
- コア点:指定された半径$\epsilon$以内に少なくとも指定された個数(MinPts)の隣接点があるような点
- ボーダー点:半径$\epsilon$以内の隣接点の個数がMinPtsに満たないものの、コア点の半径$\epsilon$以内に位置するような点
- ノイズ点:コア点でもボーダー点でもないその他すべての点
これらを図示すると以下のようになります。

その後、2つの単純な手順によりクラスタリングを行います。
- コア点、あるいはコア点ごとの接続関係(接続関係を持つには$\epsilon$以内にある必要がある)に基づいて、別々のクラスタを形成する
- 各ボーダー点をそれと対になっているコア点のクラスタに割り当てる
DBSCANの主な利点
- (k-meansと異なり)クラスタが球状という前提を設けない
- データ点を必ずクラスタに割り当てる必要がないので、ノイズ点を除去することができる
3.1 DBSCANの実装
ここから、半月上の構造を持つデータを作成し、k-means、階層的クラスタリング、DBSCANを比較してみます。
半月上の構造を持つデータを作成
# 半月上のデータを作成
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=200, noise=0.05, random_state=0)
plt.scatter(X[:,0], X[:,1])
plt.tight_layout
plt.show()

k-meansと階層的クラスタリングを実装
# k-meansクラスタリングと階層的クラスタリングを比較する
# 2つのサブプロットを作成
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
# k-meansクラスタリング
kmeans = KMeans(n_clusters=2, random_state=0)
kmeans_labels = kmeans.fit_predict(X)
# 階層的クラスタリング
from sklearn.cluster import AgglomerativeClustering
hierarchical_clustering = AgglomerativeClustering(n_clusters=2, metric='euclidean', linkage='ward')
hierarchical_labels = hierarchical_clustering.fit_predict(X)
# k-meansの結果をプロット
ax1.scatter(X[:, 0], X[:, 1], c=kmeans_labels, cmap='viridis')
ax1.set_title('K-means Clustering')
ax1.set_xlabel('X')
ax1.set_ylabel('Y')
# 階層的クラスタリングの結果をプロット
ax2.scatter(X[:, 0], X[:, 1], c=hierarchical_labels, cmap='viridis')
ax2.set_title('Hierarchical Clustering')
ax2.set_xlabel('X')
ax2.set_ylabel('Y')
plt.tight_layout()
plt.show()

図から、k-meansも階層的クラスタリングも正確に分類できていないことが分かります。
次に、DBSCANを実装してみます。sklearnのDBSCANオブジェクトを用いて、簡単に実装できます。
# DBSCANクラスタリングの実装
from sklearn.cluster import DBSCAN
# DBSCANの実行
dbscan = DBSCAN(eps=0.2, min_samples=5, metric='euclidean')
dbscan_labels = dbscan.fit_predict(X)
# DBSCANの結果をプロット
plt.figure(figsize=(10, 6))
plt.scatter(X[:, 0], X[:, 1], c=dbscan_labels, cmap='viridis', marker='o')
plt.title('DBSCAN Clustering')
plt.xlabel('X')
plt.ylabel('Y')
plt.show()

DBSCANアルゴリズムは半月上のクラスタをうまく検出できます。DBSCANの任意の形状をもつデータのクラスタリングが可能である、という特徴が浮き彫りになっています。
DBSCANもそうだが、他のk-means法や階層的クラスタリングでもユーグリッド距離を使用している際は、次元の呪いに気をつける必要があります。特徴量が増え、高次元空間になると、データ点同士のユークリッド距離がすべてほぼ等しくなるという現象が起こるからです。高次元のデータセットに対して、クラスタリングを実行する際は、主成分分析(PCA)などの次元削減法を用いると良いでしょう。
出典
Python機械学習プログラミング 達人データサイエンティストによる理論と実践の第10章を参考にしている。
本記事で用いたPythonとライブラリのバージョン
Python version: 3.10.4
pandas version: 2.2.3
scikit-learn version: 1.6.1
matplotlib version: 3.10.1
numpy version: 2.2.5
seaborn version: 0.13.2