はじめに
とある事情で大量にウェブ上のデータが必要となって、スクレイピングを試みました。が、8年分のデータを取得するのに私のデスクトップでなんと24時間もかかるのです。別に待てばいい話なのですが、PCの負荷が高まって動作が不安定になるのと、つい癖でPCにスリープをかけてしまってスクレイピングが止まってしまうのです。なので、AWSで代わりに実行させることにしました。
構成
全体の流れ
Step FunctionでMapでイテレートしながらLambdaを呼び出して、結果をS3に保存というシンプルな流れです。

Lambdaの同時実行数は1000であり、最大実行時間は15分です。24時間分の処理が、単純計算で、24 * 60 / 1000 = 1.4 分で完了する目論見です。
Step Functionの構成
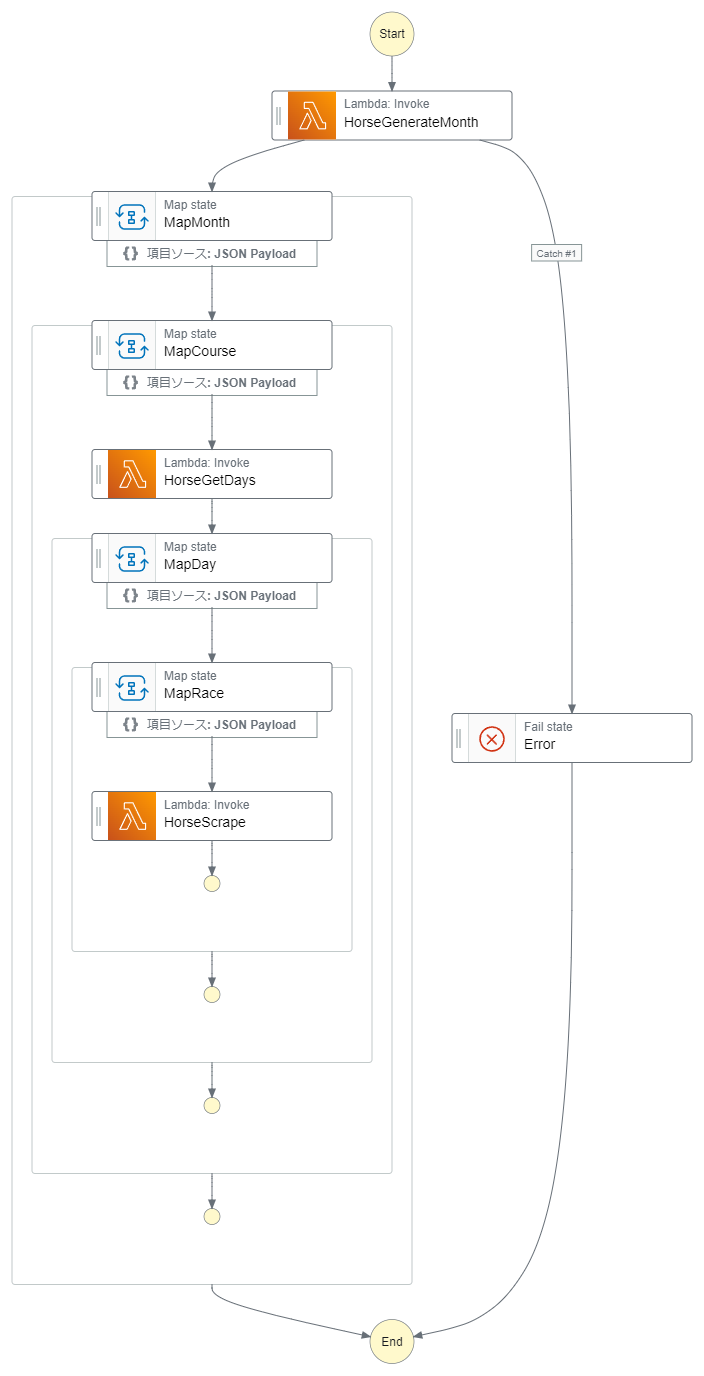
Step Functionのコード
{
"Comment": "Horse Race Scraping",
"StartAt": "HorseGenerateMonth",
"States": {
"HorseGenerateMonth": {
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:671798687873:function:HorseGenerateMonth",
"Next": "MapMonth",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "Error"
}
]
},
"MapMonth": {
"Type": "Map",
"MaxConcurrency": 100,
"ItemsPath": "$.list_months",
"Parameters": {
"yearmonth.$": "$$.Map.Item.Value",
"list_course.$": "$.list_course"
},
"End": true,
"Iterator": {
"StartAt": "MapCourse",
"States": {
"MapCourse": {
"Type": "Map",
"MaxConcurrency": 100,
"ItemsPath": "$.list_course",
"Parameters": {
"yearmonth.$": "$.yearmonth",
"racecourse.$": "$$.Map.Item.Value"
},
"End": true,
"Iterator": {
"StartAt": "HorseGetDays",
"States": {
"HorseGetDays": {
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:671798687873:function:HorseGetDays",
"Next": "MapDay"
},
"MapDay": {
"Type": "Map",
"MaxConcurrency": 100,
"ItemsPath": "$.list_days",
"Parameters": {
"yearmonth.$": "$.yearmonth",
"racecourse.$": "$.racecourse",
"list_race.$": "$.list_race",
"day.$": "$$.Map.Item.Value"
},
"End": true,
"Iterator": {
"StartAt": "MapRace",
"States": {
"MapRace": {
"Type": "Map",
"MaxConcurrency": 100,
"ItemsPath": "$.list_race",
"Parameters": {
"yearmonth.$": "$.yearmonth",
"racecourse.$": "$.racecourse",
"day.$": "$.day",
"raceround.$": "$$.Map.Item.Value"
},
"End": true,
"Iterator": {
"StartAt": "HorseScrape",
"States": {
"HorseScrape": {
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:671798687873:function:HorseScrape",
"End": true
}
}
}
}
}
}
}
}
}
}
}
}
},
"Error": {
"Type": "Fail",
"Cause": "An error occurred"
}
}
}
HorseGenerateMonthのコード
import json
import pandas as pd
def lambda_handler(event, context):
start = event['start'] # e.g. '2023-5-1'
end = event['end'] # e.g. '2023-6-1'
yearmonth = [{'year': date.year, 'month': date.month} for date in pd.date_range(start=start, end=end, freq='MS')]
RACECOURSE_DICT = {'浦和': 42, '船橋': 43, '大井': 44, '川崎': 45, '門別': 30, '盛岡': 35, '水沢': 36, '金沢': 46, '笠松': 47, '名古屋': 48, '園田': 50, '姫路': 51, '高知': 54, '佐賀': 55, '帯広ば': 65}
list_course = list(RACECOURSE_DICT.keys())
return {
'list_months': yearmonth,
'list_course': list_course,
}
HorseGetDaysのコード
import pandas as pd
def lambda_handler(event, context):
yearmonth = event['yearmonth']
racecourse = event['racecourse']
year = yearmonth['year']
month = yearmonth['month']
RACECOURSE_DICT = {'浦和': 42, '船橋': 43, '大井': 44, '川崎': 45, '門別': 30, '盛岡': 35, '水沢': 36, '金沢': 46, '笠松': 47, '名古屋': 48, '園田': 50, '姫路': 51, '高知': 54, '佐賀': 55, '帯広ば': 65}
racecourse_id = RACECOURSE_DICT[racecourse]
url = f'https://nar.netkeiba.com/top/calendar.html?year={year}&month={month}&jyo_cd={racecourse_id}'
df = pd.read_html(url)[0]
lst = [str(a) for a in sum(df.values.tolist(),[])]
list_day = [int(i.split()[0]) for i in lst if racecourse in i]
list_race = list(range(1, 13))
return {
'yearmonth': yearmonth,
'racecourse': racecourse,
'list_days': list_day,
'list_race': list_race,
}
HorseScrapeのコード
# 簡易版です
import re
import json
import time
import boto3
import requests
import pandas as pd
from bs4 import BeautifulSoup
def save_txt(fname, txt, encoding):
s3 = boto3.client('s3')
upload_res = s3.put_object(Bucket='horserace-dx', Key=f'raw/{fname}', Body=txt, ContentType="text/plain; charset=utf-8")
def extract_db_id(soup, type_):
# type_ : horse or jockey
horse_a_list = soup.find('table', class_='RaceTable01')\
.find_all('a', attrs={"href": re.compile(r"https://db\.netkeiba\.com/" + type_)})
return {a["href"].split('/')[-1] for a in horse_a_list}
def save_race_get_id(race_id):
url_past = f'https://nar.netkeiba.com/race/shutuba_past.html?race_id={race_id}&rf=shutuba_submenu'
r = requests.get(url_past)
r.encoding = 'EUC-JP'
save_txt(f'past/past{race_id}.html', r.text, 'utf-8')
url_race = f'https://nar.netkeiba.com/race/shutuba.html?race_id={race_id}&rf=shutuba_submenu'
r = requests.get(url_race)
r.encoding = 'EUC-JP'
save_txt(f'race/race{race_id}.html', r.text, 'utf-8')
soup = BeautifulSoup(r.content, 'html.parser')
horse_id = extract_db_id(soup, 'horse')
jockey_id = extract_db_id(soup, 'jockey')
trainer_id = extract_db_id(soup, 'trainer')
save_txt(f'id/horse_id{race_id}.json', json.dumps(list(horse_id)), 'utf-8')
save_txt(f'id/jockey_id{race_id}.json', json.dumps(list(jockey_id)), 'utf-8')
save_txt(f'id/trainer_id{race_id}.json', json.dumps(list(trainer_id)), 'utf-8')
def lambda_handler(event, context):
time.sleep(0.01)
day = event['day']
yearmonth = event['yearmonth']
raceround = event['raceround']
racecourse = event['racecourse']
RACECOURSE_DICT = {'浦和': 42, '船橋': 43, '大井': 44, '川崎': 45, '門別': 30, '盛岡': 35, '水沢': 36, '金沢': 46, '笠松': 47, '名古屋': 48, '園田': 50, '姫路': 51, '高知': 54, '佐賀': 55, '帯広ば': 65}
racecourse_id = RACECOURSE_DICT[racecourse]
raceround = event["raceround"]
try:
race_id = f'{yearmonth["year"]}{racecourse_id:02}{yearmonth["month"]:02}{day:02}{raceround:02}'
save_race_get_id(race_id)
except Exception as ex:
# in case the race round doesn't exist
print(ex)
レイヤー
レイヤーは以下の手順で作成しました。
(1) 以下を実行してpythonフォルダ内にファイルを作成する(名前は必ずpythonとする)。
pip install requests==2.25.0 -t ./python --no-user
pip install beautifulsoup4 -t ./python --no-user
pip install pytz -t ./python --no-user
(2) PyPIで、numpyとpandasのページに行き、以下のwhlファイルをダウンロードする。
- numpy-1.24.3-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
- pandas-2.0.2-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
(3) whlファイルを解凍する。Zip形式の解凍でよい。中身をpythonフォルダに移す。
(4) pythonフォルダをZip形式で圧縮しAWS Lambdaのレイヤーにアップロードする。
難しかったところ
レイヤー
Lambdaの組み込み関数ではない機能を使っているためレイヤーが必須となりますが、これが曲者でした。全ては以下に書いてありますが、
レイヤー追加後にLambdaでこのようなエラーが出て詰まってしまいました。
{ "errorMessage": "Unable to import module 'lambda_function': cannot import name 'DEFAULT_CIPHERS' from 'urllib3.util.ssl_' (/opt/python/urllib3/util/ssl_.py)", "errorType": "Runtime.ImportModuleError", "requestId": "fb66bea9-cbad-4bd3-bd4d-6125454e21be", "stackTrace": [] }
エラーの文言でGoogle検索して、urllib3のバージョンが原因らしいというのは分かったのですが、pip installのときにurllib3<2などとバージョンを絞っても効果がアリませんでした。
最終的に、requestsがurllib3に依存していることに気づき、Lambdaであらかじめインストールされているurllib3のバージョンを調べ、それに対応したrequestsのバージョンをpip installすることでこのエラーは解決しました。
ですが、また別のエラーが発生しました。今度はnumpy関連です。こちらは先程とは違い、numpyのバージョンや、内部でnumpyを使っているpandasのバージョンを変えても功を奏しませんでした。ですが、エラーを調べるうちにlinux向けのnumpyのライブラリがPyPIにあることが分かり、そちらをインストールしたところエラーは解決しました。おそらくは、LambdaのインスタンスがLinuxのためライブラリもそれ向けのものを使うように、とのことだと思います。
このレイヤー関連のエラーだけで6時間は潰れたと思います。
Step Function
やるべきことのおおまかな構想は頭に浮かんでいて、リストをStep FunctionのMapでイテレートしてやり、その中でLambdaを実行するという流れです。が、具体的にどうやればいいかが分かりませんでした。欲しい情報をGoogleでキーワード検索なり自然言語の形式で検索なりしても、意外と望む情報が出てこないのです。そこで、アルゴリズムを自然言語の形式で記述し、ChatGPTに質問しました。
In AWS, in step function, write a function which achieves the following:
- Task_generate_month generates list_months and passes down list_months to Map1
- Map1 iterates through list_months and passes down list_months[i] to Map2
- Map2 iterates through list_course and passes down list_months[i] and list_course[j] to Task_get_days
- Task_get_days generates list_dates and passes down list_months[i], list_course[j] and list_dates to Map3
- Map3 iterates through list_dates and passes down list_months[i], list_course[j], and list_dates[k] to Map4
- Map4 iterates through list_race and passes down list_months[i], list_course[j], list_dates[k], and list_race[l] to Task_scrape
- Task_scrape does its job using the passed down variables.
- When an error occurs, the program goes to Error state and it stops.
返ってきた回答がこちらです。
{
"Comment": "Example Step Functions State Machine",
"StartAt": "Task_generate_month",
"States": {
"Task_generate_month": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:function:Task_generate_month",
"ResultPath": "$.list_months",
"Next": "Map1",
"Catch": [
{
"ErrorEquals": ["States.ALL"],
"Next": "Error"
}
]
},
"Map1": {
"Type": "Map",
"ItemsPath": "$.list_months",
"Iterator": {
"StartAt": "Map2",
"States": {
"Map2": {
"Type": "Map",
"ItemsPath": "$.list_course",
"Iterator": {
"StartAt": "Task_get_days",
"States": {
"Task_get_days": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:function:Task_get_days",
"InputPath": "$.input",
"OutputPath": "$.output",
"Next": "Map3",
"Catch": [
{
"ErrorEquals": ["States.ALL"],
"Next": "Error"
}
]
}
}
},
"End": true
}
}
},
"End": true
},
"Map3": {
"Type": "Map",
"ItemsPath": "$.list_dates",
"Iterator": {
"StartAt": "Map4",
"States": {
"Map4": {
"Type": "Map",
"ItemsPath": "$.list_race",
"Iterator": {
"StartAt": "Task_scrape",
"States": {
"Task_scrape": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:function:Task_scrape",
"InputPath": "$.input",
"End": true,
"Catch": [
{
"ErrorEquals": ["States.ALL"],
"Next": "Error"
}
]
}
}
},
"End": true
}
}
},
"End": true
},
"Error": {
"Type": "Fail",
"Cause": "An error occurred",
"End": true
}
}
}
こちらでも様々な問題が起こりました。
- Mapでイテレートしている変数の取り出し方が分からない(のちに
$$.Map.Item.Valueでよいと判明) - ResultPath, InputPath, OutputPathの意味を理解しないままChatGPTの出力を鵜呑みにしていたので入出力がおかしなことになった
- "Catch"が全てエラーを出力するので結局全て削除した。
こちらは全て対処するのに6時間はかかったと思います。
結果
全体のシステムが組み上がり、2015-01-01~2023-05-31の期間で、データを取得してみました。しかし、最大実行履歴数25000の制限に引っかかり、実行が失敗してしまいました。最下層のHorseScrapeは必ずデータ件数と同回数だけ実行されることを考えると、この制限を回避するのは難しそうです。膨大なエネルギーを注いだ本システムですが、残念ながらここまでのようです。
ただ、個人的な話をすれば、Step FunctionとLambda、S3を使って何かを製作する経験が得られたのは収穫でした。