はじめに
結論から言うとMecab側の文字コードをターミナル側の文字コードに合わせてあげると文字化けしなくなります.
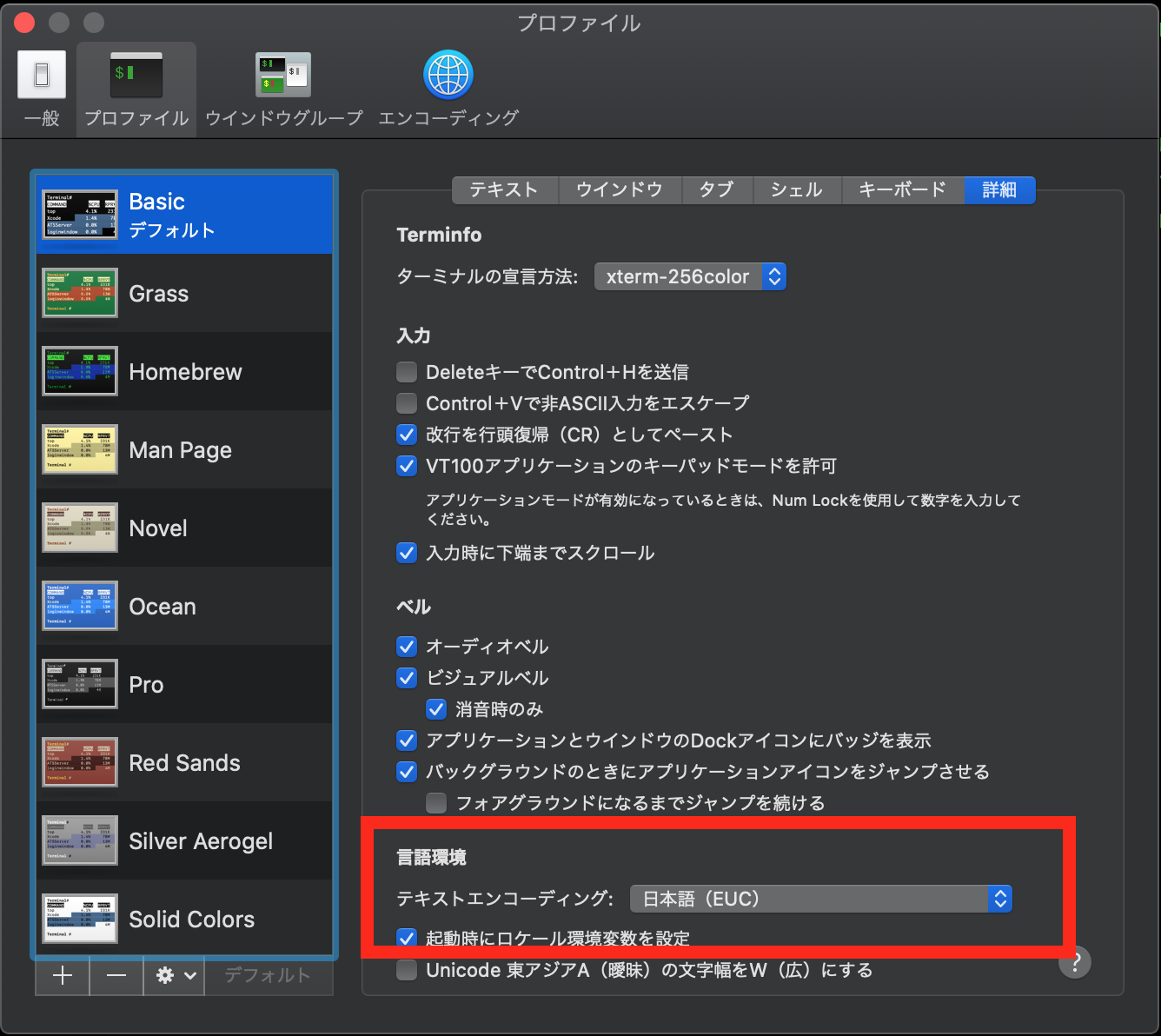
HomebrewでMecabをインストールする場合Mecabの文字コード設定がEUC-JPになることがあります.
開発環境等で特別な事情がなければ,文字コードの設定はUTF-8にすることを推奨します.
変更前の状態
 文字化けしてます.
とりあえず実験として一時的にターミナルの文字コードを「**UTF-8**」から「**EUC-JP**」に変更して再度Mecabしてみます.
文字化けしてます.
とりあえず実験として一時的にターミナルの文字コードを「**UTF-8**」から「**EUC-JP**」に変更して再度Mecabしてみます.

文字化けすることなく形態素解析できてます.
つまり原因はターミナル側が「UTF-8」でMacab側が「EUC-JP」の設定になっているから.
というわけでこれからMecab側の設定をUTF-8に変更します.
やることとしてはMecabをUTF-8で再設定してipadic辞書のdicrcの設定(Config)をUTF-8に変更します.
MecabをUTF-8でインストール
こちらを参考にMecabをインストールします.
./configureのときに--with-charset-=utf8(オプション)をつけます!
Xの部分はダウンロードしたMecabのバージョンによって変わるのでそこだけ変えてください.
$ cd [インストール先のディレクトリ]
$ cd mecab-X.X
$ ./configure --with-charset=utf8
$ make
$ make check
$ sudo make install
ipadic辞書のインストール
同様にipadic辞書もインストールします.
$ tar zxfv mecab-ipadic-2.7.0-XXXX.tar.gz
$ cd mecab-ipadic-2.7.0-XXXX
$ ./configure --with-charset=utf8
$ make
$ sudo make install
ipadic辞書ディレクトリ内の拡張子がcsvまたはdefのファイルをUTF-8に変換する
EUC-JPで書かれたcsvおよびdefファイルを全てUTF-8に変換して上書き保存します.
nkfコマンドが使えることを前提に進めます.
nkfは$ brew install nkfでインストールできます.
一個一個のファイルに対してコマンド打って変更してもいいのですが面倒なのでいっぺんに処理します.
まずはcsvファイル
# csvファイルを一括でUTF-8に変換
$ foreach f ( *csv )
$ nkf -w --overwrite $f
$ end
# UTF-8になっていることを確認
foreach f ( *csv )
nkf -g $f
end
f は変数なのでなんでも構いません.
同様にdefファイルも変換します.
# defファイルを一括でUTF-8に変換
$ foreach f ( *def )
$ nkf -w --overwrite $f
$ end
# UTF-8になっていることを確認
$ foreach f ( *def )
$ nkf -g $f
$ end
foreachで一括処理してもいいですが,こっちのがシンプルでいいかもです.
$ nkf -w --overwrite *.csv
$ nkf -w --overwrite *.def
dicrcの編集
ipadic辞書のディレクトリ内に
dicrcという設定ファイルがあるはずなので以下の箇所を編集します.
- config-charset = EUC-JP
+ config-charset = UTF-8
ipadic辞書の設定変更を有効にする
インストール
$ ./configure --with-charset=utf8
$ make
$ sudo make install
これでうまく直りました!(°▽°)
$ mecab
おはようございます
おはよう 感動詞,*,*,*,*,*,おはよう,オハヨウ,オハヨー
ござい 助動詞,*,*,*,五段・ラ行特殊,連用形,ござる,ゴザイ,ゴザイ
ます 助動詞,*,*,*,特殊・マス,基本形,ます,マス,マス
EOS
おわりに
mecab-neologd辞書にdicrc等の設定ファイルはなかったのでネオログ辞書は設定しなくても大丈夫です.
参考