著者:Leilei(プロダクトマーケティング担当)
Difyは、AIやRAGワークフロー向けのWeb検索API「Tavily」のサポートを開始しました。これにより、ユーザーはライブWebデータを直接ナレッジパイプラインに取り込み、情報の精度向上と最新状態の維持を実現できます。
本日より、AIアプリケーションやRAG、エージェントフロー向けに設計された高機能Web検索API「Tavily」が、Difyマーケットプレイスのデータソースプラグインとして利用可能になりました。
数週間前にリリースした 「Difyナレッジパイプラン」 は、ユーザーがRAGワークフローを自由に構築できる新たな出発点です。データソースのアップロードや解析、チャンク化、埋め込みなど、すべてのコンポーネントがプラグインとして提供されています。この柔軟性により、非構造化データに最適化したRAGソリューションを設計でき、LLMによる応答もより正確かつ文脈に即したものとなります。
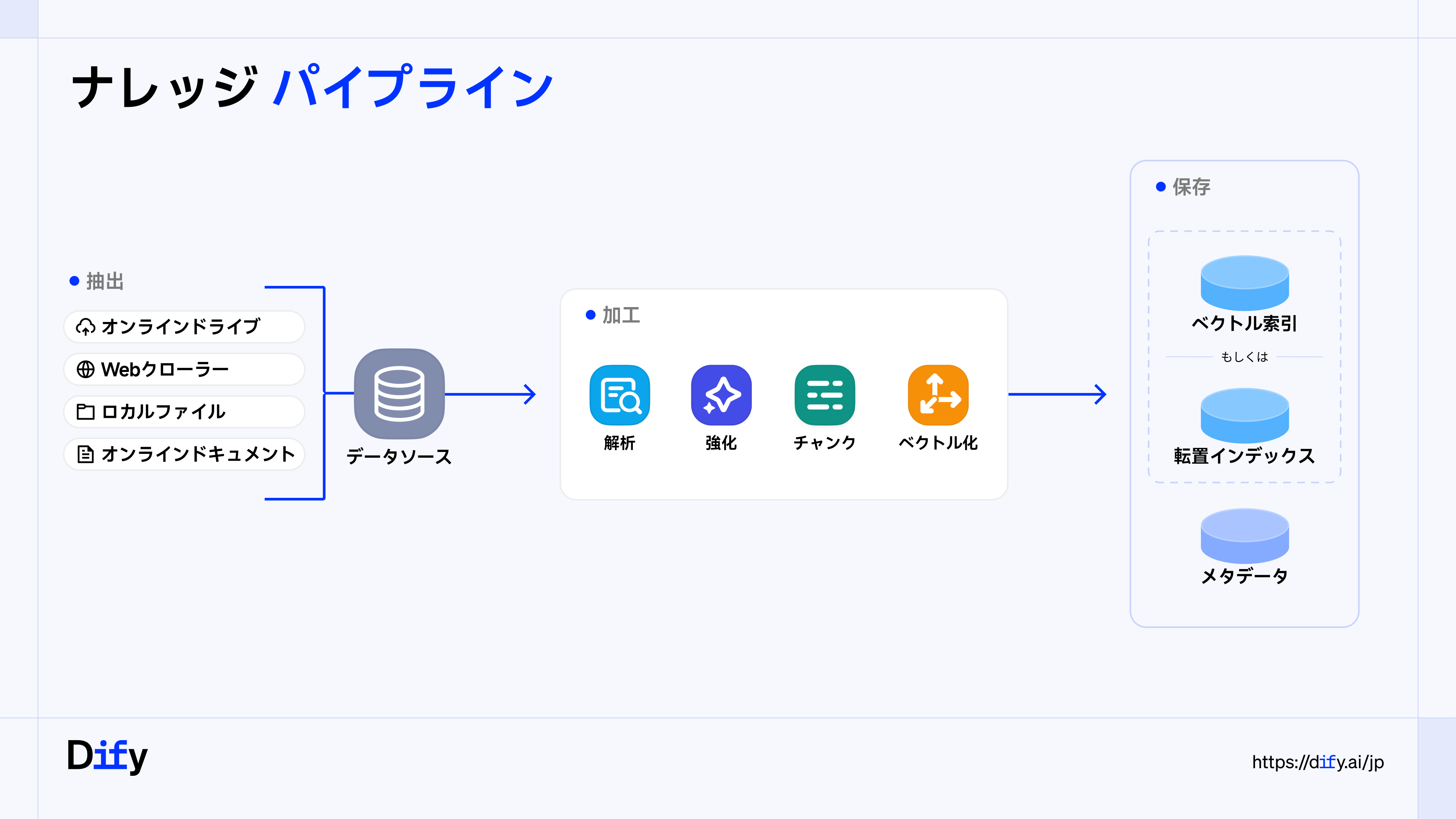
以下では、Tavilyをナレッジパイプランに組み込む方法について具体的に解説します。
Tavilyの利用開始方法
セットアップ
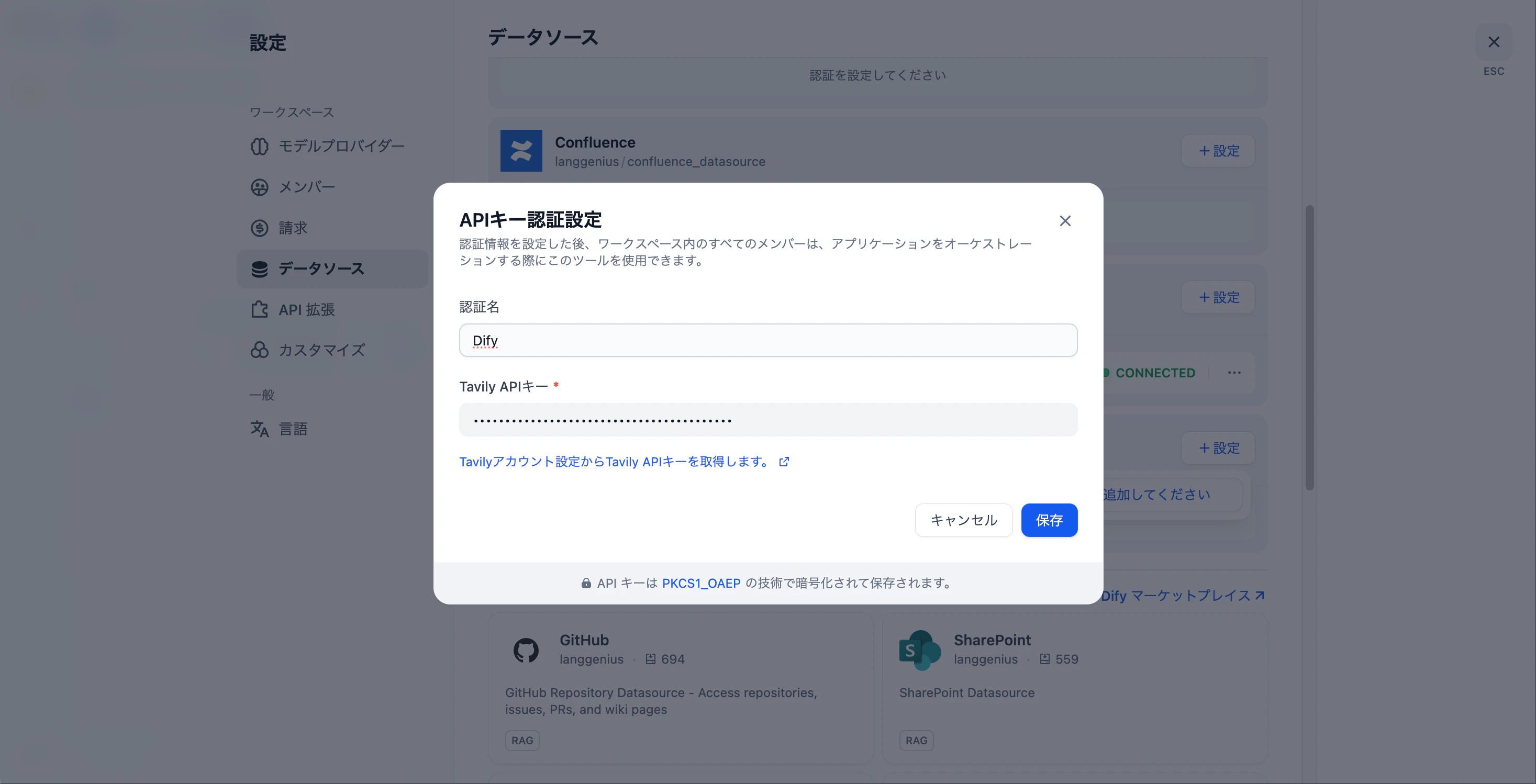
- DifyマーケットプレイスからTavilyプラグインをインストールします。
- Tavilyに登録し、無料アカウントを作成してAPIキーを取得します。
- Difyの「設定 > データソース > Tavily」でAPIキーを入力・設定します。
パイプラインの構築
- 既存のテンプレートを選択するか、一から作成することも可能です。
- 簡単な文書、長大な技術マニュアル、複雑なPDF、構造化されたテーブルなど、代表的なユースケースに対応したテンプレートを用意しています。
- テンプレートは目的に合わせてカスタマイズでき、すぐに利用を開始できます。

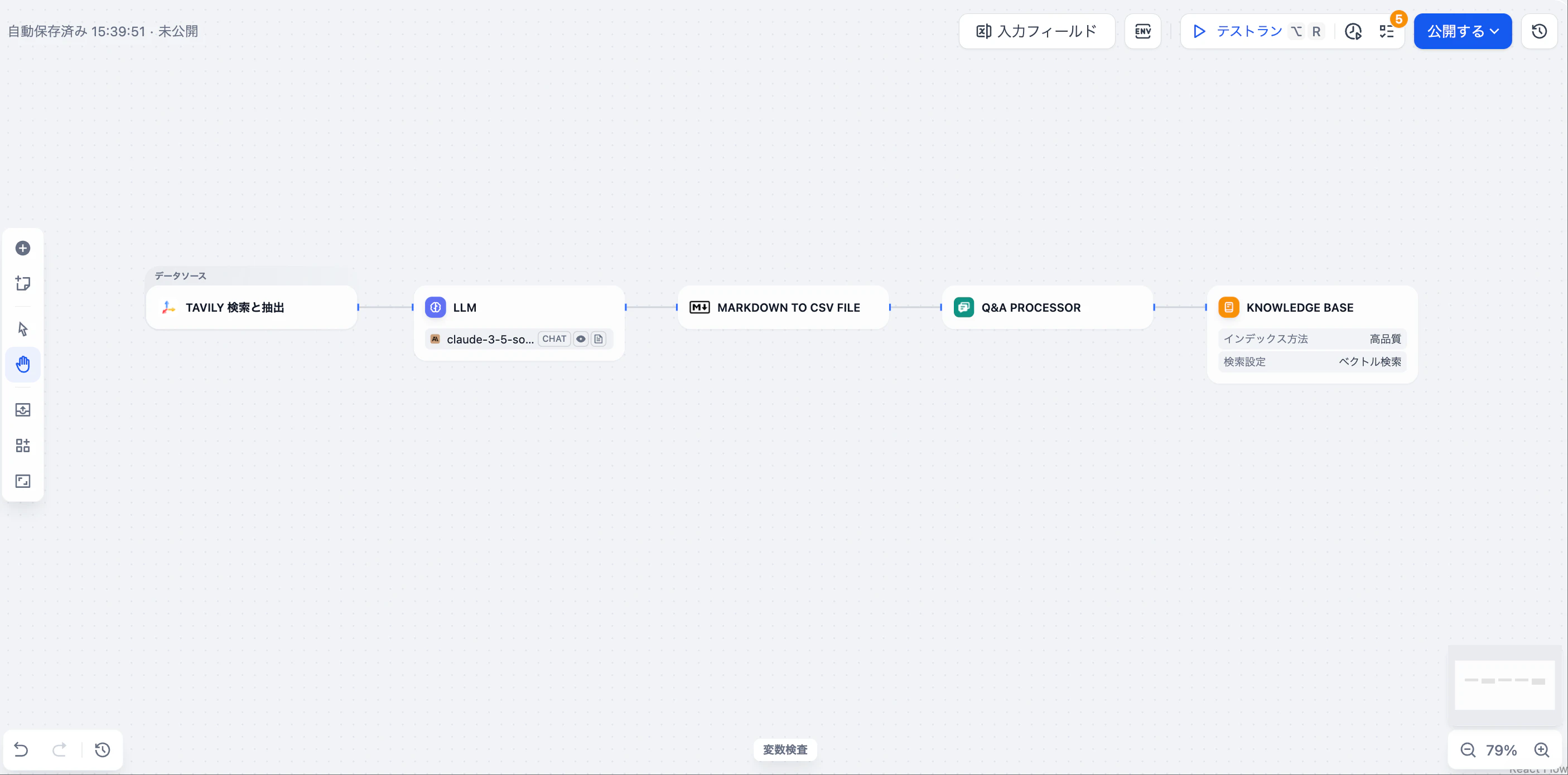
例:LLM生成のQ&AテンプレートでTavilyをデータソースに設定する方法
このパイプラインでは、TavilyによるWebクロールから抽出された重要な情報をLLMが解析し、Q&Aペアを生成します。生成されたデータはナレッジベースに保存され、必要に応じて取り出すことが可能です。
設定のポイント
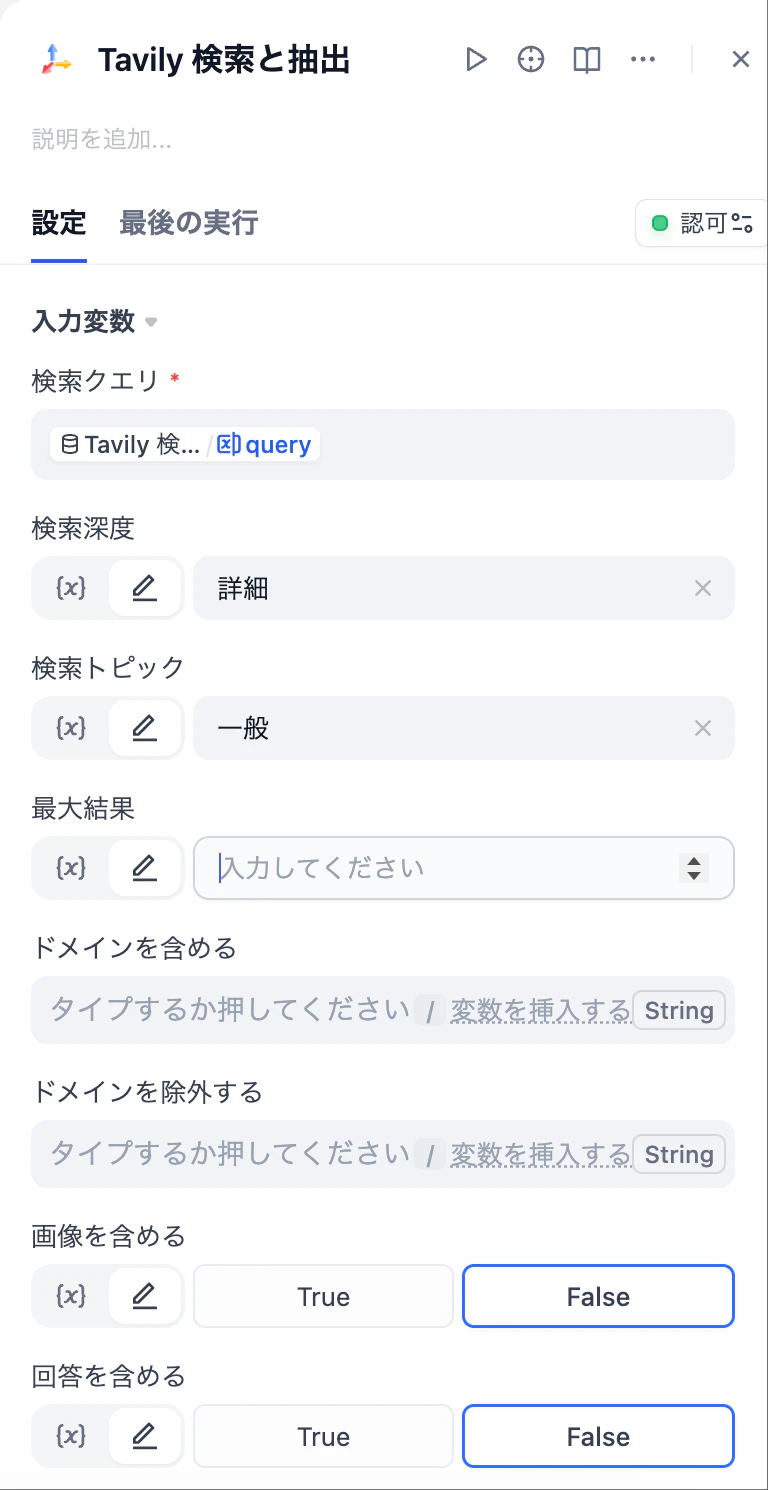
- 設定画面で検索クエリ用の変数を作成します。
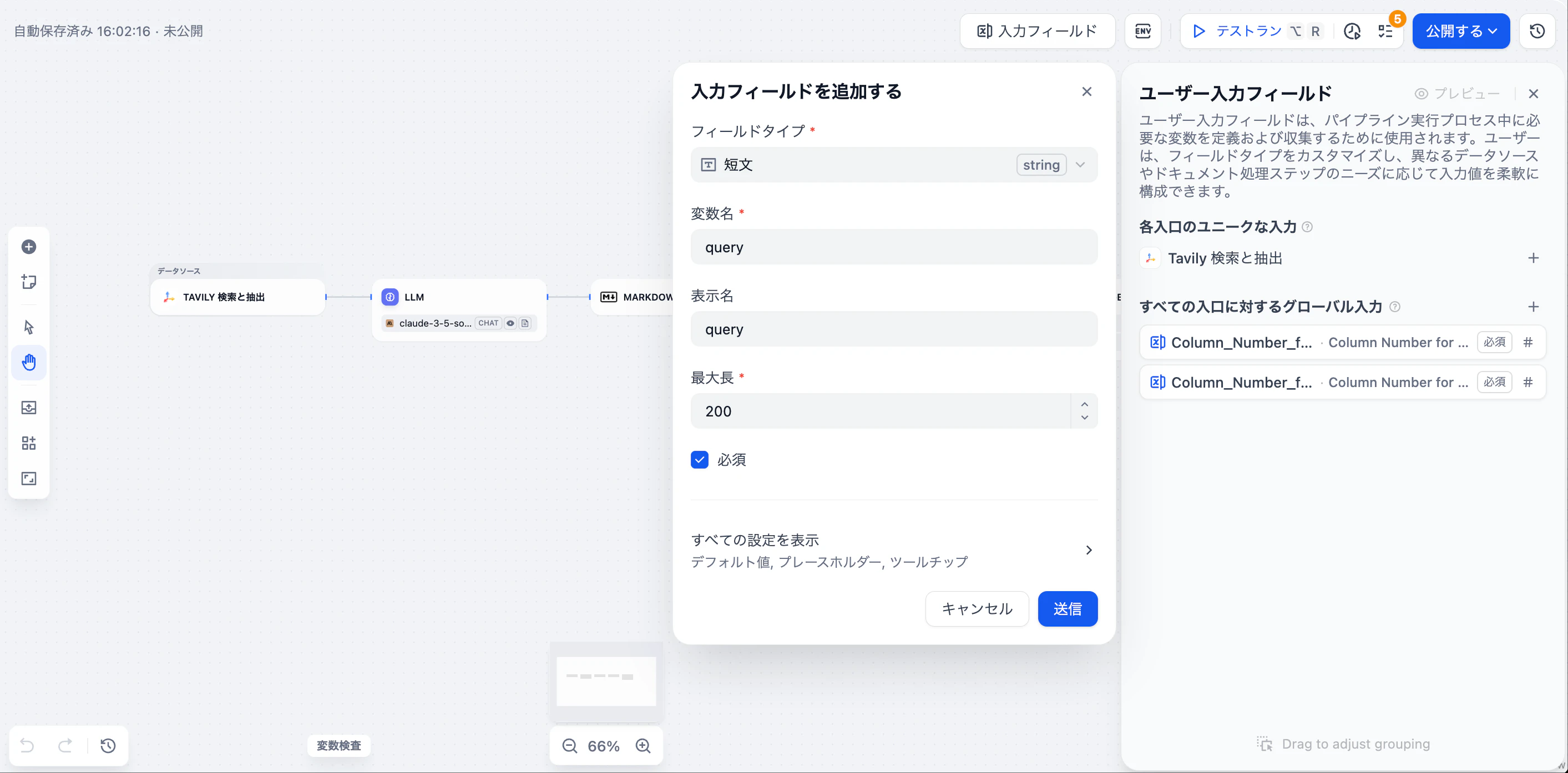
- クロールパラメータ(検索深度、最大結果数、トピックフィルターなど)は、ユースケースに応じて調整可能です。
-
LLMノードでは、システムプロンプト内でTavilyの出力をコンテキストとして利用する設定を行います。
-
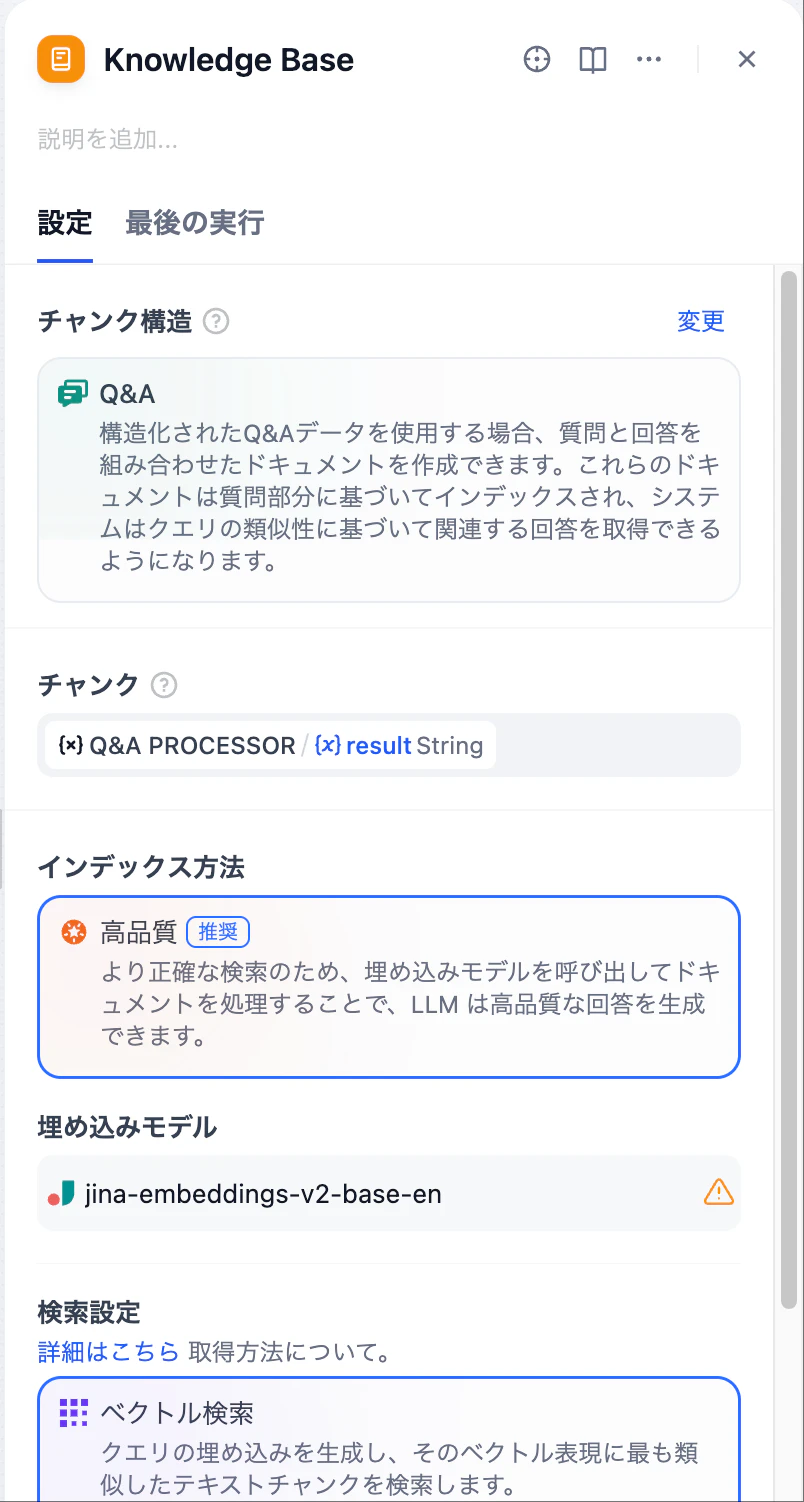
最終ステップ:インデックス、埋め込みモデル、検索時の各種設定を行い、パイプラインを公開すれば準備完了です。
実際の活用例
Tavilyのサポートドキュメントをクロールし、各記事をQ&Aペアに変換してナレッジベースへ保存するなどの活用方法があります。
保存したナレッジベースは、Difyのチャットボットやエージェント、ワークフロー等、さまざまなアプリケーションから活用可能です。文脈情報が必要な場面で幅広く利用できます。
Tavilyとは
Tavilyは、検索・抽出・クロール機能を統合したWebアクセススタックで、開発者による開発者のためのツールです。リアルタイム検索、構造化データの抽出、完全レンダリングを含むクロールをワンストップで提供し、ライブWebへのアクセスとその上での推論処理をサポートします。RAG、自律型エージェント、実運用環境向けエージェントシステムのために特別に設計されています。
Difyについて
Difyは、オープンソースのLLMアプリケーション開発プラットフォームです。直感的なインターフェースで、エージェントAIワークフローやRAGパイプライン、モデル管理、オブザーバビリティ(可観測性)などを統合。これにより、プロトタイプから本番運用までスムーズに移行できる環境を実現します。