再現手順
まず説明すべきなのが、AUTO_INCREMENTが同期されないというのはどう言うことなのかだ。
これは簡単に再現できるので、順を追って説明しよう。
普段DBに触れない人だと、「そもそもAUTO_INCREMENTって何やねん」と言いたくなるかもしれないが、そう言う方はまずこちらの記事を読んでいただきたい。
それでは、事象を再現させてみよう
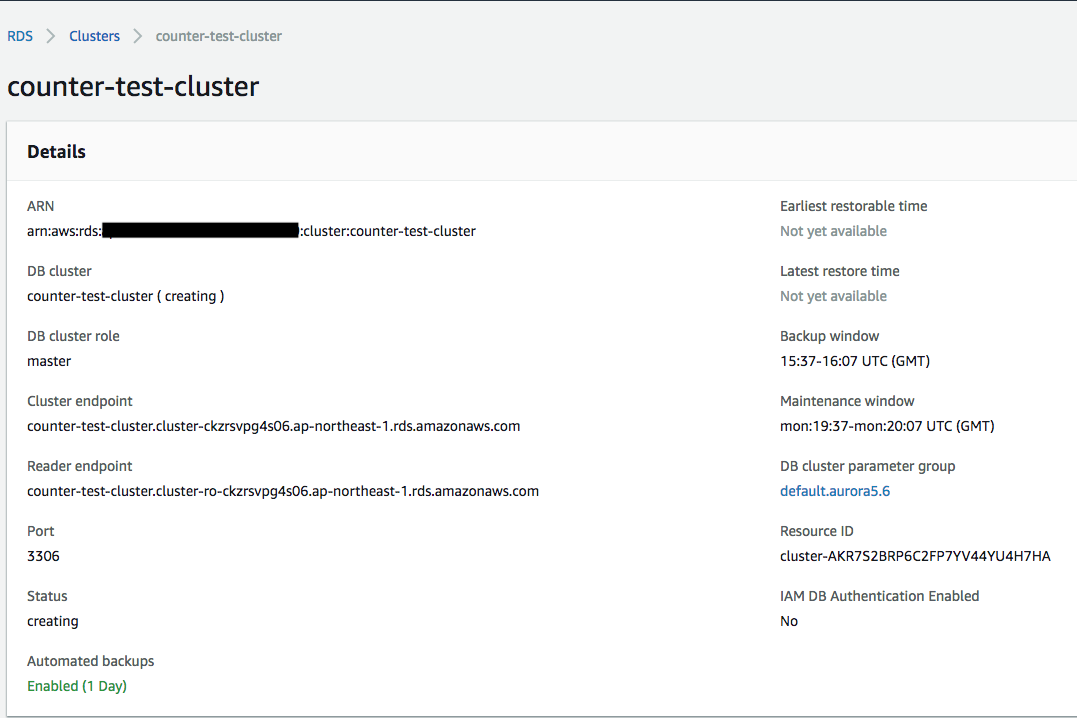
1. Auroraクラスターを作る
とりあえずテスト用に適当なクラスターを作ってみる。
タグにもある通りDBエンジンはMySQLを選択している。とりあえずバージョンは5.6にしているが、5.7でも変わらないはず。
PostgreSQLだとどうなるのかは確認していないので、申し訳ないが今回は割愛させてほしい。
エンドポイントを惜しげも無く晒しているが、このクラスターはすでに削除されているのでアクセスしようとしても無駄だと言うことは先に言っておこう。
2. テスト用のテーブル作成
上記の記事を参考にしつつ、まずはプライマリインスタンスの方にアクセスして適当なテーブルを作成する。
CREATE TABLE
fruit(
id INT AUTO_INCREMENT NOT NULL PRIMARY KEY,
name VARCHAR(50) UNIQUE, price INT
);
3. テストデータを追加
INSERT INTO
fruit(name, price)
VALUES
("apple", 120),
("pineapple", 300),
("orange", 150);
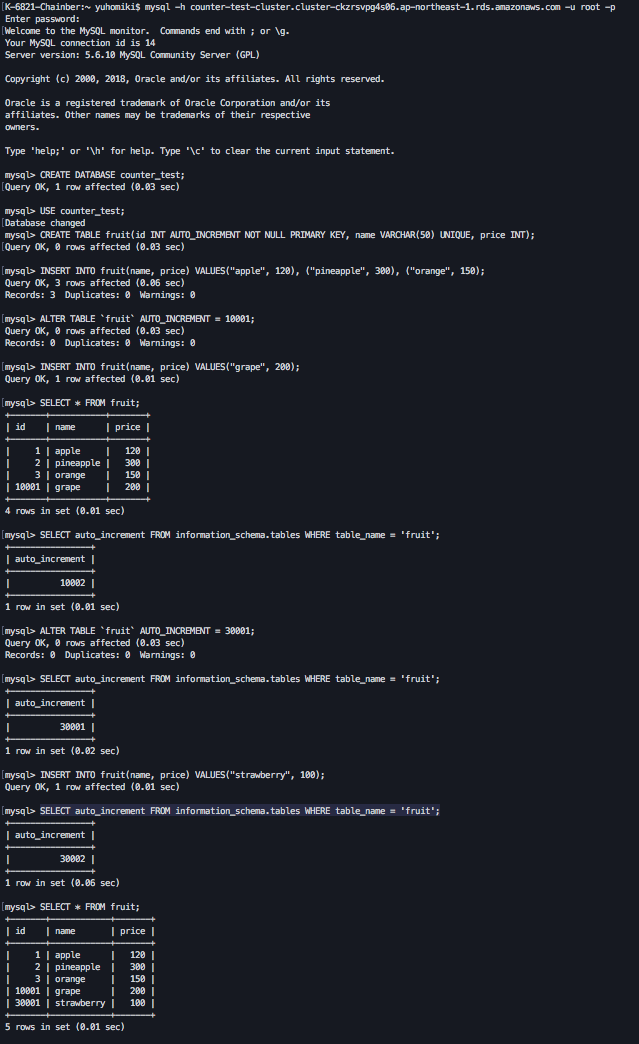
ここでAUTO_INCREMENTをいじってデータを追加してみる
ALTER TABLE `fruit` AUTO_INCREMENT = 10001;
INSERT INTO fruit(name, price) VALUES("grape", 200);
ALTER TABLE `fruit` AUTO_INCREMENT = 30001;
INSERT INTO fruit(name, price) VALUES("strawberry", 100);
これで現在AUTO_INCREMENTのカウンタは30002になっているはずだ。
ちょっと長いが画面キャプチャを添付する。
4. それではリードレプリカを見てみよう
まあ、まずはこいつを見てほしい
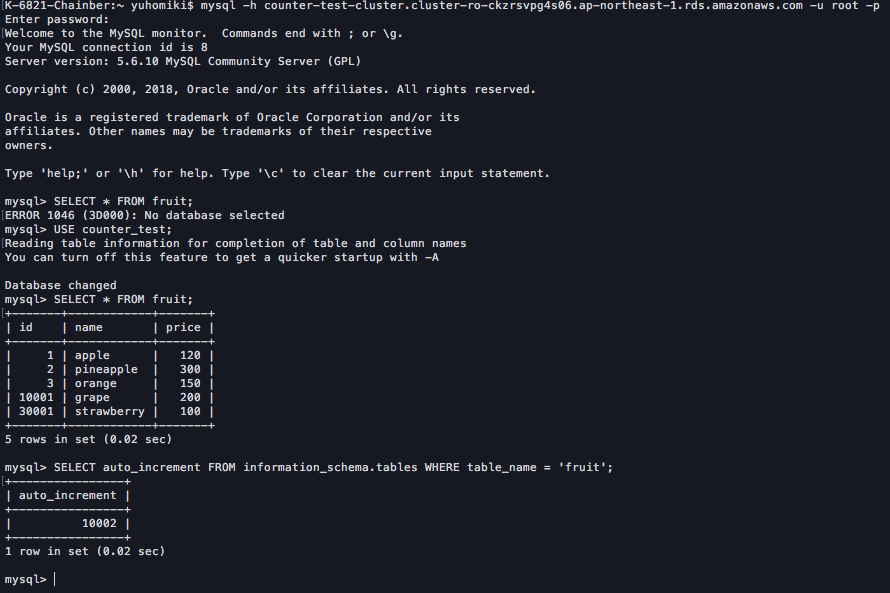
何と、strawberryのidは確かに30001なのに、AUTO_INCREMENTのカウンタは10002になっているではないか。
「データの同期が取れてねぇじゃねえか!」と切れそうになるが、これは公式のドキュメントの記載から説明できる仕様なのである。
解説
1. Auroraのプライマリインスタンスとリードレプリカのデータ同期
あまり詳細にはドキュメント内でも語られていないのだが、実はさらっとヒントはある。
Q: 単一の Amazon Aurora データベースの可用性をどのように向上できますか?
Amazon Aurora レプリカを追加できます。Amazon Aurora レプリカは基盤となるストレージをプライマリインスタンスと共有します。
そう、Auroraはストレージを共有することでプライマリインスタンスとリードレプリカのデータ同期を実現しているのだ。
2. AUTO_INCREMENTはどこにいる?
ストレージを共有している以上、ストレージに保存されているデータは否応無く同期されるはずである。
しかし、AUTO_INCREMENTのカウンタは同期されていなかった。
つまり、AUTO_INCREMENTのカウンタはストレージにはいないのだろうか。
これも答えはドキュメントにある。
InnoDB テーブルに AUTO_INCREMENT カラムを指定すると、InnoDB データディクショナリ内のテーブルハンドルに、カラムに新しい値を割り当てる際に使用される自動インクリメントカウンタと呼ばれる特別なカウンタが含まれます。このカウンタは、ディスク上には格納されず、メインメモリー内にのみ格納されます。
「このカウンタは、ディスク上には格納されず、メインメモリー内にのみ格納されます。」
そう、カウンタはメモリにしかいないのである1。
ストレージ共有によってデータを同期している以上、メモリにあるものが同期されないのは当然である。
3. それは大丈夫なのか...?
「仕様なのはわかった。でもそれはやばいんじゃないのか?」と言うのが大方の感想であろう。
まずAuroraクラスターにおいて書き込みを行うインスタンスは1台だけ2なので、普段は問題になりそうな場面はない。
問題はフェイルオーバーが発生して、リードレプリカの1台がプライマリインスタンスに昇格した時だ。
先ほどの例に沿うなら、AUTO_INCREMENTのカウンタは30002であるはずなのに、フェイルオーバーが発生してリードレプリカがプライマリインスタンスに昇格した場合、次にレコードをINSERTするときにリードレプリカが持っていた10002と言うカウンタが使われてしまうのではないか。
これは発生しようものなら大問題である。
そこで一度手動でフェイルオーバーを発生させ、カウンタがどうなったか確認してみる。
まずはプライマリインスタンス
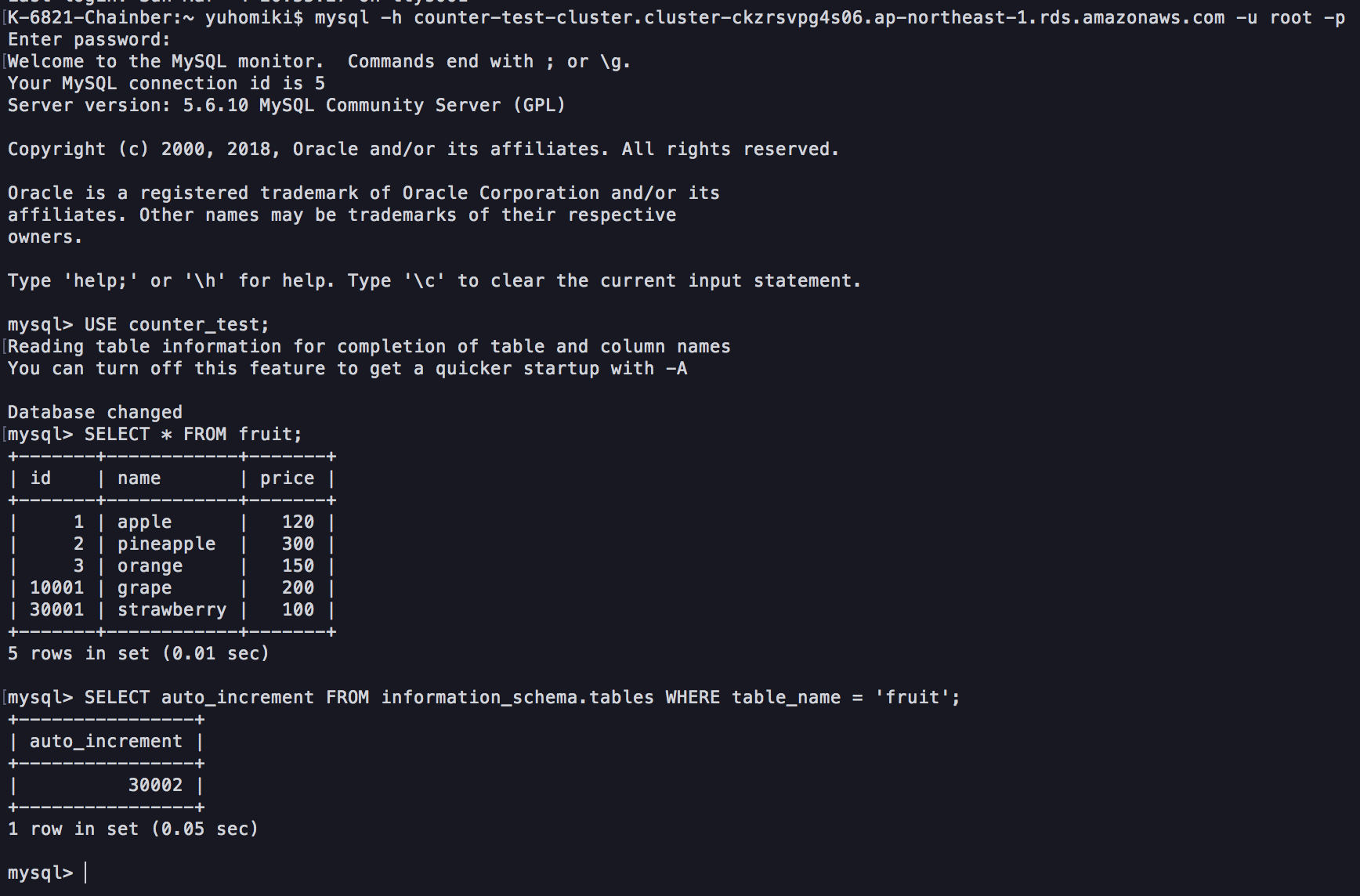
次にリードレプリカ(接続しているエンドポイントを確認してほしい)。

おや、カウンタが適切な値になっている。
どうやらフェイルオーバー発生時にAUTO_INCREMENTのカウンタが初期化されているようなのだ。
とりあえず上述の懸念は杞憂で済みそうなのだが、果たしてこのとき何が起きているのか。
考えられるのは
- 普段のデータ同期とは別経路でインメモリの情報を同期している
- 再起動している
の二つであろう。
ここでちらっとドキュメントを見る。
DB クラスターに 1 つ以上の Aurora レプリカがある場合は、障害発生中に 1 つの Aurora レプリカがプライマリインスタンスに昇格されます。障害イベントによって短い中断が発生し、その間例外によって読み取りと書き込みオペレーションが失敗します。ただし、一般的なサービスの復元時間は 120 秒未満であり、多くの場合 60 秒未満で復元されます。
気になるのはフェイルオーバー発生時に1〜2分ほどDBが全く使えなくなることだ。
はっきりした根拠があるわけではないが、実はフェイルオーバー発生時にリードレプリカも再起動していると考えれば、AUTO_INCREMENTの初期化も中断時間も説明がつくのではないだろうか。
-
この挙動はMySQL5.7でも同様である。MySQL :: MySQL 5.7 Reference Manual :: 14.8.1.5 AUTO_INCREMENT Handling in InnoDB ↩
-
マルチマスターなる機能がプレビュー段階で、今後は書き込み可能なインスタンスが複数になる可能性はある。流石に何らかの手は打っている信じたい。Amazon Aurora マルチマスターのプレビューにサインアップする ↩