目的
通勤手段で都道府県ごとにクラスタリング分析してみる。
前回の国勢調査データを使ったクラスタリング分析では人口データを使ったが、今回は、通勤手段を使ってみたい。
前回記事 年齢別人口の男女比を都道府県ごとにクラスタリング分析してみる。 を適宜参照してください。
国勢調査データのダウンロード
従業地・通学地による人口・就業状態等集計 からダウンロードするのだが、ダウンロードできるファイルのサイズ制限があり、csvは、項目を絞らないとダウンロードできないため、エクセルファイルでダウンロードする。
国勢調査データの読み込み
エクセルでみると、1シートしかなく、ヘッダは8行目から4行あるため、
skiprows=8, header=[0,1,2,3] をパラメータ指定して読み込む。
import pandas as pd
# 読み込み
excel_file = pd.ExcelFile('./data/e18.xlsx')
for sheet_name in excel_file.sheet_names:
df = excel_file.parse(sheet_name, index_col=0, skiprows=8, header=[0,1,2,3])
print(df.head())
Unnamed: 1_level_0 Unnamed: 2_level_0 Unnamed: 3_level_0 0_常住地による人口 \
Unnamed: 1_level_1 Unnamed: 2_level_1 Unnamed: 3_level_1 人
地域識別コード 都道府県 地域名 利用交通手段
a 00_全国 00000_全国 00_総数 57152761
a 00_全国 00000_全国 01_徒歩のみ 3999367
a 00_全国 00000_全国 02_鉄道・電車 14575628
a 00_全国 00000_全国 03_乗合バス 3890283
a 00_全国 00000_全国 04_勤め先・学校のバス 684451
a 00_全国 00000_全国 05_自家用車 28315168
国勢調査データの前処理
ヘッダ整形
4行あるヘッダのうち、前半は3行目の 地域識別コード/都道府県/地域名/利用交通手段 を採用し、後半は、1行目の 0_常住地による人口 (以降)を採用する。
# ヘッダ整形
front_col = [col for col in df.columns.get_level_values(2) if not col.startswith('Unnamed')]
back_col = [col for col in df.columns.get_level_values(0) if not col.startswith("Unnamed:")]
front_col = [col for col in front_col if not col.startswith(" ")]
new_col = front_col + back_col
df.columns = new_col
都道府県 地域名 利用交通手段 0_常住地による人口 001_従業も通学もしていない 002_自市区町村で従業・通学 0021_自宅で従業 0022_自宅外の自市区町村で従業・通学 003_他市区町村で従業・通学 0031_自市内他区で従業・通学 ... 0034_従業・通学市区町村「不詳・外国」 004_従業地・通学地「不詳」 0R1_(再掲)流出人口 1_従業地・通学地による人口 101_うち他市区町村に常住 1011_自市内他区に常住 1012_県内他市町村に常住 1013_他県に常住 102_うち従業地・通学地「不詳」又は従業・通学市区町村「不詳・外国」で当地に常住している者 1R1_(再掲)流入人口
a 00_全国 00000_全国 01_徒歩のみ 3999367 - 3736864 - 3736864 220806 102950 ... 4553 41697 - 3999367 216253 102950 75030 38273 46250 -
a 00_全国 00000_全国 02_鉄道・電車 14575628 - 1666279 - 1666279 12801798 3729954 ... 178316 107551 - 14575628 12623482 3729954 4866967 4026561 285867 -
a 00_全国 00000_全国 03_乗合バス 3890283 - 1265371 - 1265371 2586104 820524 ... 39057 38808 - 3890283 2547047 820524 1069016 657507 77865 -
a 00_全国 00000_全国 04_勤め先・学校のバス 684451 - 290836 - 290836 387212 39815 ... 6063 6403 - 684451 381149 39815 261742 79592 12466 -
必要なデータのみ残す
文字列⇒数値変換した後、必要なデータのみを残し、不要なデータは削除する。
- 都道府県単位で分析したいので、市区町村と全国のデータを削除
- 各利用交通手段を合計しても、利用交通手段の総数とならなかったため、総数を削除(総数は各利用交通手段を合計して別途計算することにする)
- 従業地による人口は、大きく分けて、定住地人口、流出人口、流入人口とあるが、今回は定住地人口を採用
また、カラム名を使いやすいアルファベットに変換し、不要な都道府県コードも削除する。
# 文字列⇒数値変換
for col in df.loc[:, '0_常住地による人口':].columns:
df[col] = pd.to_numeric(df[col], errors='coerce').fillna(0).astype(int)
# 都道府県レベルのみ(市区町村レベルと全国を削除する)
pref_level = df['地域名'].map(lambda x: '000_' in x and (not '00000_全国' in x ) )
df_pref = df[pref_level]
# 00_総数は一旦削除
df_pref = df_pref[df_pref['利用交通手段']!='00_総数']
# 必要な列のみ(都道府県/利用交通手段/0_常住地による人口)
df_pref = df_pref.loc[:,['都道府県','利用交通手段','0_常住地による人口']]
df_pref.rename(columns={'都道府県': 'pref','利用交通手段':'commute by','0_常住地による人口':'population'},inplace=True)
# 都道府県のコードを削除
df_pref['pref'] = df_pref['pref'].map(lambda x: x[3:] )
print(df_pref.head())
pref commute by population
a 北海道 01_徒歩のみ 256106
a 北海道 02_鉄道・電車 352288
a 北海道 03_乗合バス 205581
a 北海道 04_勤め先・学校のバス 44902
a 北海道 05_自家用車 1308686
2次元データ化
通勤手段毎の人数は、縦1次元のデータフレームなので、都道府県別に2次元化する。
都道府県のリストを作って、1都道府県ずつ処理する。
都道府県名(pref)が一致するデータのみを抽出し、転置することで縦⇒横のデータに変換する。
それをリストにアペンドすることで2次元のデータフレームができあがる。
ついでに、通勤手段名称をカラム名称として設定する。
import numpy as np
# 通勤手段毎の人数
population_list = []
# 都道府県のリストを作成
pref_list = df_pref['pref'].unique()
# 都道府県のリストのループ
for pref in pref_list:
# 対象の都道府県のデータのみ
df_temp = df_pref[df_pref['pref']==pref]
# 人数を取得し、転置(縦⇒横)
df_population = df_temp['population'].T
# numpy配列としてリストに追加
np_population = np.array(df_population)
population_list.append(np_population)
# 通勤手段毎の人数
np_population_list = np.array(population_list)
# 通勤手段の名称リスト
col = ['walk','train','public bus','private bus','car','taxi','motorcycle', 'bicycle','other','unknown']
# 通勤手段のデータフレーム
df_pref = pd.DataFrame(np_population_list,index=pref_list,columns=col)
print(df_pref.head())
walk train public bus private bus car taxi motorcycle bicycle other unknown
北海道 256106 352288 205581 44902 1308686 10774 8294 217597 57288 62412
青森県 44465 15912 24012 13319 420743 1548 2920 47789 10087 12004
岩手県 41249 25940 22785 9194 437679 1113 4132 47516 9408 9932
宮城県 84357 186933 73377 11622 657838 2357 17559 109607 19764 25621
秋田県 26546 14318 10544 3571 350972 441 1394 34717 4974 7588
合計と比率を計算
各都道府県で人口に差があるので、通勤手段別人口にも差があるため、差ではなく比率を計算する。
前述の通り、ダウンロードしたデータの総数は数が合わないので、自分で合計を計算する。
# 合計を求める
df_sum = df_pref.sum(axis=1)
# 各通勤手段の比率を計算
df_pref_ratio = ( df_pref.T / df_sum * 100 )
print(df_pref_ratio.head())
北海道 青森県 岩手県 宮城県 秋田県 山形県 \
walk 10.147120 7.500856 6.773813 7.094577 5.833452 5.487031
train 13.957926 2.684215 4.259805 15.721404 3.146364 3.076838
public bus 8.145280 4.050614 3.741699 6.171139 2.317032 1.284219
private bus 1.779052 2.246799 1.509817 0.977431 0.784723 0.901730
car 51.851162 70.975660 71.874610 55.325369 77.125685 78.084589
ようやく前処理が終わったので可視化する。
可視化(都道府県別)
都道府県別でグラフ表示する。
import matplotlib.pyplot as plt
import japanize_matplotlib
fig_size_x = 12
fig_size_y = 5
fig = plt.figure(figsize=(fig_size_x, fig_size_y))
plt.plot(df_pref_ratio)
plt.title( '通勤手段比率(都道府県別)')
plt.xlabel('通勤手段')
plt.ylabel('比率(%)')
plt.grid(axis='y')
plt.grid(axis='x')
plt.show()
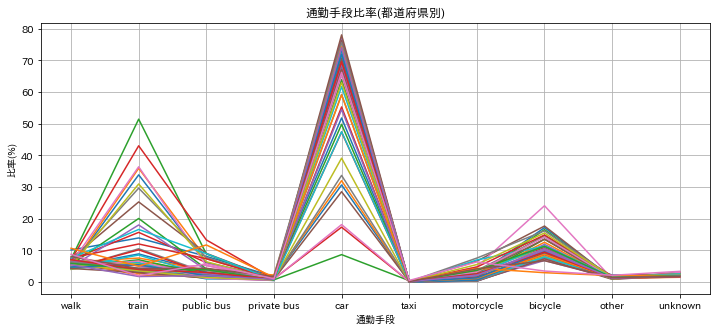
車>電車>自転車の順にばらついているようだが、線が多くてわかりにくいので、クラスタリング分析してみる
クラスタリング分析
from scipy.cluster import hierarchy
import japanize_matplotlib
fig = plt.figure(figsize=(fig_size_x, fig_size_y))
method = 'ward'
Z = hierarchy.linkage(df_pref_ratio.T, method=method)
hierarchy.dendrogram(Z, color_threshold=0,labels=df_pref_ratio.columns)
plt.ylabel('distance')
plt.title( '通勤手段比率')
plt.xticks(rotation=90)
plt.show()
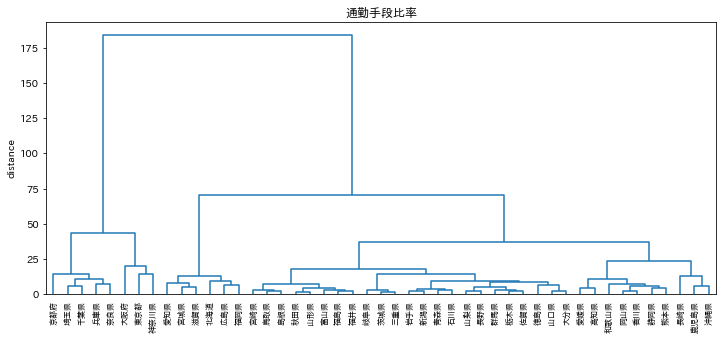
ぱっとみ、都会と田舎グループでクラスタリングされているように見えるが、5クラスタとして分類し、クラスタ毎の平均を可視化する。
可視化(クラスタ別平均)
from sklearn.cluster import AgglomerativeClustering
n_clusters = 5
clustering = AgglomerativeClustering(linkage=method, n_clusters=n_clusters)
clustering.fit(df_pref_ratio.T)
df_clustering_result = pd.DataFrame( clustering.labels_, index=df_pref_ratio.columns, columns=['label'])
fig = plt.figure(figsize=(fig_size_x, fig_size_y))
# クラスタ毎に処理
for i in range(n_clusters):
df_work = pd.DataFrame()
for j, rec in df_clustering_result.iterrows():
# 対象クラスタに分類された結果のみ抽出
if rec.label==i:
# インデックス(=都道府県名称)
name = j
df_work[name] = df_pref_ratio[name]
# クラスタ毎の平均をプロット
plt.plot(df_work.mean(axis=1),label=f'#{i}クラスタ')
plt.title( '通勤手段比率(クラスタ別)')
plt.xlabel('通勤手段')
plt.ylabel('比率(%)')
plt.grid(axis='y')
plt.grid(axis='x')
plt.legend()
plt.show()
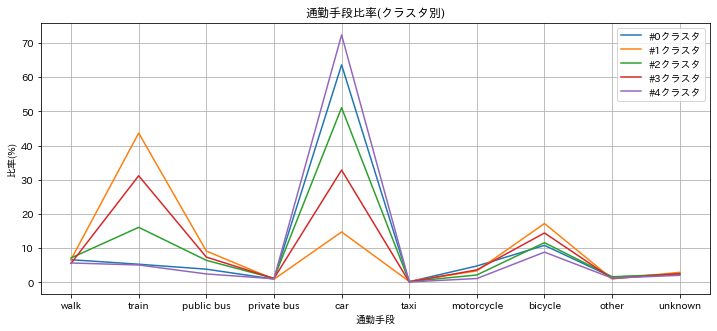
やはり、ばらつきの大きい、車、電車、自転車の影響が強そうだ。
今度はクラスタ毎に可視化する。
理解しやすいように、都会から表示してみる。
(クラスタ番号はクラスタリング分析で付与されるものなので、意味はありません。都会順に表示できるように、あらかじめ確認しておき、表示順番をリスト化しました。)
可視化(クラスタ別)
# クラスタ毎に処理
#for i in range(n_clusters):
for i in [1,3,2,0,4]: # 都会順に表示できるようにリスト化
fig = plt.figure(figsize=(fig_size_x, fig_size_y))
for j, rec in df_clustering_result.iterrows():
# 対象クラスタに分類された結果のみ抽出
if rec.label==i:
plt.plot(df_pref_ratio[j],label=f'{j}')
plt.title( f'通勤手段比率(#{i}クラスタ)')
plt.xlabel('通勤手段')
plt.ylabel('比率(%)')
plt.grid(axis='y')
plt.grid(axis='x')
plt.ylim(0, 80)
plt.legend(loc='upper right')
plt.show()
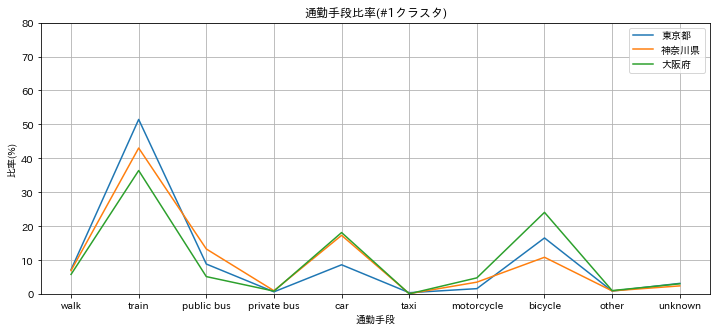
#1 クラスタ
電車が多く(40%超)、車が少ない(10%台)大都会型。
唯一、電車>車となるクラスタ。東京、神奈川、大阪。
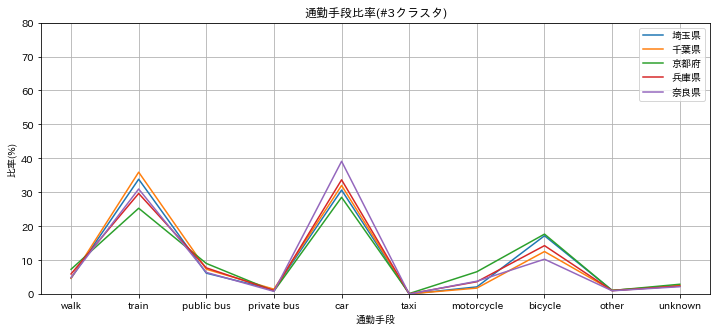
#3 クラスタ
電車(30%)、車(30%)ほぼ同じとなる、都会型。埼玉、千葉など。
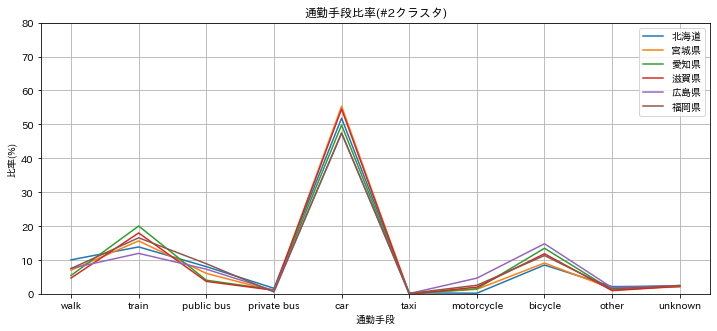
#2 クラスタ
電車(20%台)、車(50%台)となり、車が多くなるが、電車利用が多い準都会型。愛知、福岡など。
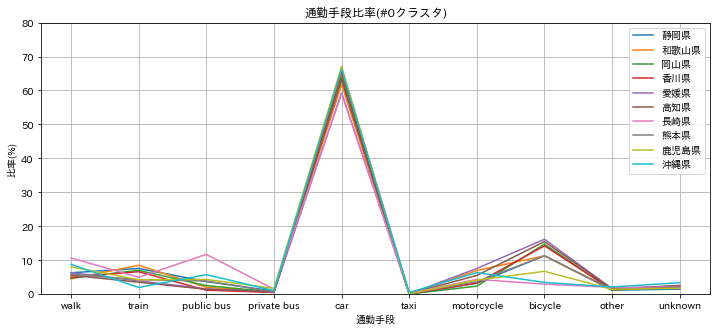
#0 クラスタ
電車(10%以下)、車(60%超)となり、車がないと不便な田舎型。静岡、和歌山など。
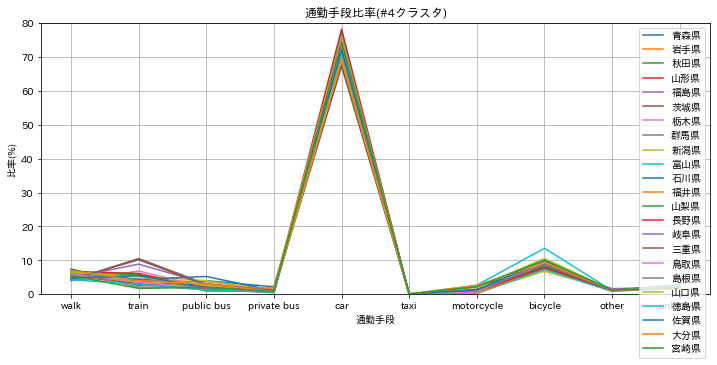
#4 クラスタ
電車(10%以下)、車(70%超)となり、車がないと生活できないど田舎型。約半数の都道府県。
可視化(通勤手段別比率)
通勤手段別に比率を棒グラフに表示する。(インタラクティブなグラフにて)
まずは、転置し表示用の都道府県名の列を作成する
df_pref_ratio_T = df_pref_ratio.T
# x軸表示用に都道府県名称の列を追加
df_pref_ratio_T['pref'] = df_pref_ratio_T.index
次にpanelに通勤手段別の棒グラフを表示する。
import plotly.express as px
import panel as pn
from typing import List
import itertools
pn.extension('plotly', sizing_mode="stretch_width")
# 各エリアのデータ観察(棒グラフ)
# ①4列目以降の列名のリストを作成(都道府県名称、他、不明を除く)
cols_list = list(df_pref_ratio_T.columns[:-3].values)
# ②グラフ作成の関数を定義
def show_chart(col_name):
'''col_nameで指定された列名で指定されたデータ
をソートし棒グラフを返す'''
fig = px.bar(df_pref_ratio_T.sort_values(col_name,ascending=False),
x='pref',
y=col_name,
title=f'交通手段の比率: {col_name} (%)'
)
return fig
# ③列名を選択するウィジェットを作成
col_sel = pn.widgets.Select(name='bar_sel', options=cols_list, value='walk')
# ④ウィジェットの値が更新されるとグラフが更新されるよう設定
interactive_chart = pn.bind(show_chart, col_sel)
# ⑤ウィジェットとグラフが並んで配置されるよう、レイアウトを作成
panel1 = pn.Column(
col_sel,
interactive_chart
)
panel1.save('commute-ratio.html',embed=True)
panel1
以下、傾向がわかりやすい/面白いグラフのみを表示する
徒歩
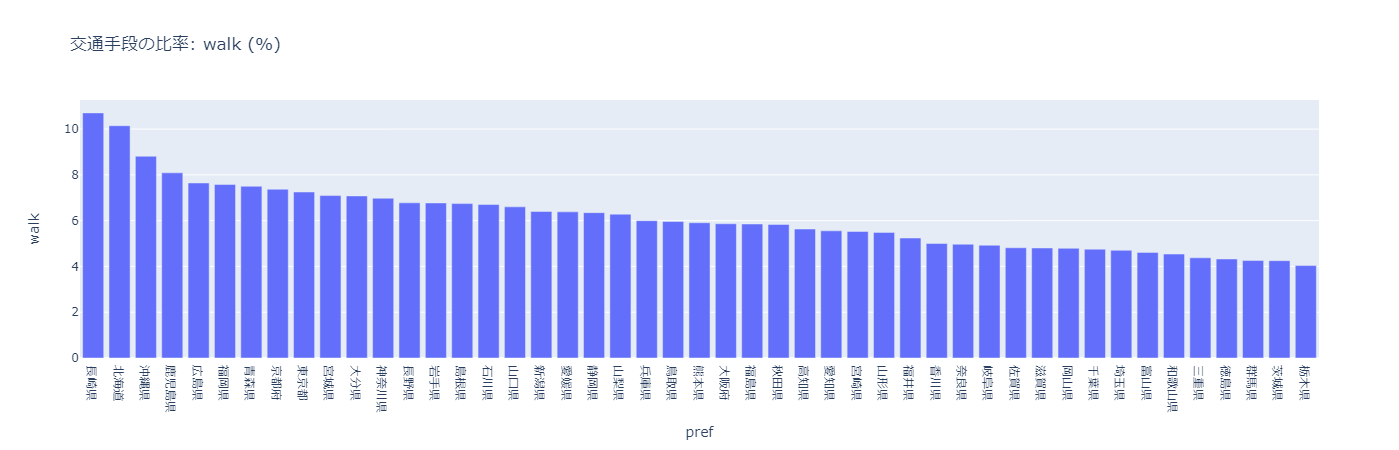
長崎県、北海道の比率が高く、健康志向が高いと考えられる。
タクシー
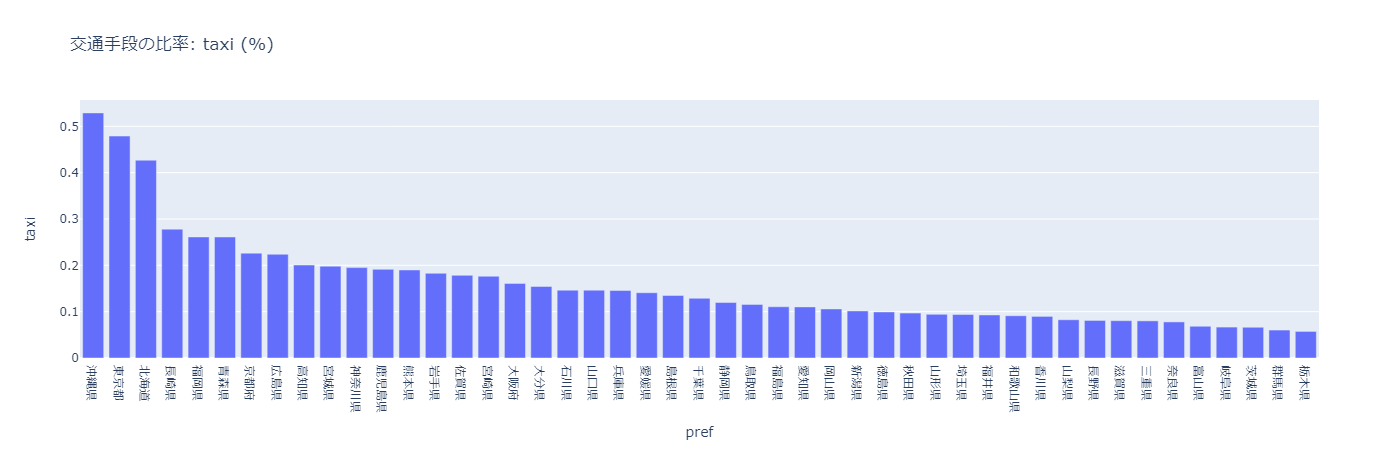
全体的に割合が低く、1%未満ではあるものの、その中でも、沖縄県、東京都、北海道が突出している。この3都道県には富裕層が多く住んでいるのではないかと考えられる。
バイク
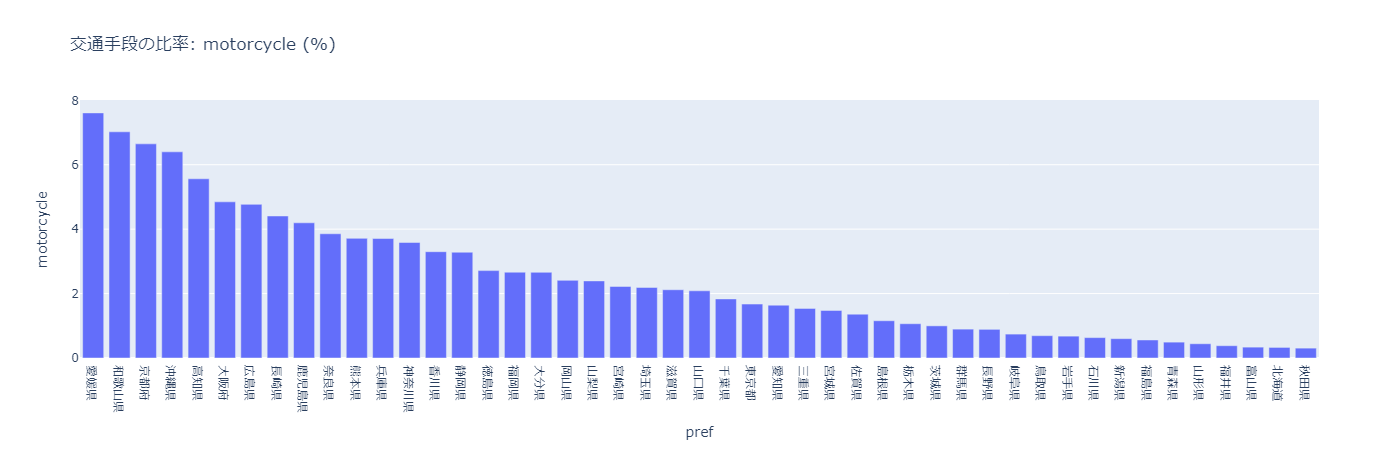
愛媛県、和歌山県、京都府、沖縄県など、近畿以西の暖かい府県が多い。
逆に、秋田県、北海道、富山県など、北海道、東北、北陸はバイク利用が少ない。やはり冬寒く雪が多いとバイク通勤はできないようだ。
自転車
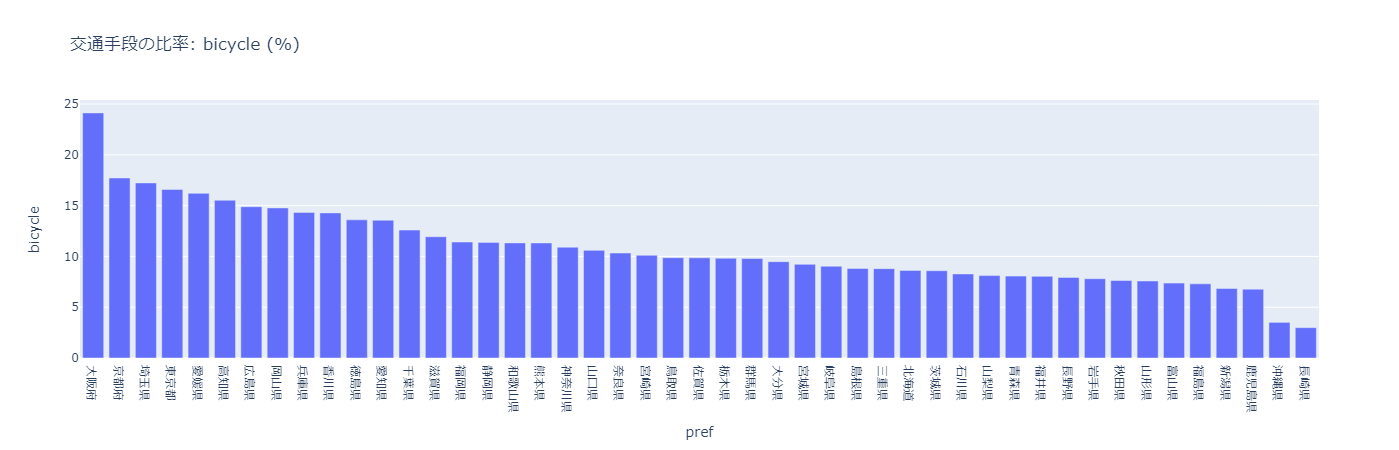
大阪府の自転車通勤が突出して高い。大阪府民は健康志向が高いのか、節約志向が高いのか。大阪府にも富裕層は多く住んでいそうだが、タクシー利用の割合が高くないことも考えると、後者ではないかと考えてしまう。
逆に、長崎県、沖縄県は自転車利用の割合が突出して低い。長崎県は坂が多いので自転車は利用しにくいか。そう考えると、長崎県は徒歩が多いことも納得できる。
沖縄県はどうしてだろう。台風が多いため、自転車が飛ばされてしまうからではないだろうか。
まとめ
通勤手段で都道府県ごとにクラスタリング分析したところ、都会か田舎かというグループ化になった。
田舎度≒車がないと生活できない、ということと考えられるが、以下の道県は、(個人的な)イメージ以上に都会になっている。
- 奈良県が、京都府、兵庫県と型を並べる都会型
- 北海道、宮城県、滋賀県が、愛知県、福岡県と型を並べる準都会型
通勤手段別でみてみると、さらに面白いことがわかった。
- 沖縄県、東京都、北海道にはタクシーを利用する富裕層が多く住んでいる。
- バイクは、暖かい地域での利用が多く、寒い地域での利用は少ない。
- 長崎県は坂が多いため、自転車利用は少なく、徒歩が多い。
- 大阪府は節約志向のため、自転車利用が極めて多い。
大阪府の富裕層は、タクシーを利用せず、自転車で通勤しているのではないか、と考えてしまいます。
(大阪府は節約志向です。いい意味で!!大阪府をディスっているわけではありません。)