目的
二本松提灯祭りでは、7台の太鼓台に提灯をつけて町内を曳き回す。
その提灯は、7台それぞれで異なり、字名(町名)の頭文字(もしくは2文字)を表している。
字毎に異なる提灯を物体検知できないか検証してみた。
二本松提灯祭り とは、「7台の太鼓台にそれぞれ300個余りの提灯をつけて町内を曳き回す。」Wikipediaより引用
物体検知 とは、「デジタル画像処理やコンピュータビジョンに関連する技術の一つで、デジタル画像・動画内に映っている特定のクラスの物体を検出するものである。」Wikipediaより引用
YOLO
物体検知のライブラリとしては、YOLOを使用する。
【YOLO V5】AIでじゃんけん検出を参考としました。
ラベリングについても詳しく解説してあり、とても参考になりました。
提灯の字名(町名)
提灯は紅提灯(赤)で、白抜き文字で字名(町名)を表している。
「本町」の場合は、「本」
また、表面と裏面にそれぞれ「本」があり、見る角度によって、文字の一部がかけたり、表面/裏面の文字が半分ずつ見えたり、さまざまな見え方となる。

「亀谷(かめがい)」のみ、表面と裏面で文字が異なり、「龜」と「谷」となる。

他の字は、「竹田」「松岡」「根崎」「若宮」「郭内」の1文字目で以下の通り。

なお、「松岡」の「枩」は、「松」の偏(へん)「木」と旁(つくり)「公」を縦に並べた異体字である。
個人的には、赤みが強いのが好みなので、字画の少ない「本」「竹」が好きである。画像認識する際も、字画が少ないほうが有利ではないかと思う。
「亀谷」は、表裏で違う字なので、画像認識では不利になるのではないか。
「松岡」は、異字体ではあるが、これを教師データとして学習すれば、問題なく画像認識できるはずである。
教師データ
通常、画像認識の教師データ(画像)を取得するのは大変なことだが、1台の太鼓台に300個もの提灯がついているので、1枚の写真で、40~50個の教師データが取れる。(太鼓台の周囲4面で300個なので、1枚の写真(≒1面)では、40~50個となる。)
この画像の場合、52個の教師データを抜き出した。提灯の文字が正面を向いているものだけでなく、斜めを向いているものや、表裏2文字が半分ずつ見えているものなど、人間が認識できるものは全部抜き出した。

太鼓台の屋根の上に提灯を取り付けるので、見上げるアングルの画像が多い。

この教師データを抜き出す作業(ラベリング、バウンディングボックス作成)が、1個1個必要なので、labelImgというツールは使えたものの、この作業は大変だった。
字毎に用意した画像数、抜き出した教師データの数は下表の通りである。できるだけ字毎でばらつきがないようにしたつもりではある。
| 字 | 画像数 | 教師データ数 |
|---|---|---|
| 本町 | 21 | 882 |
| 亀谷 | 22 | 867 |
| 竹田 | 26 | 861 |
| 松岡 | 25 | 849 |
| 根崎 | 24 | 834 |
| 若宮 | 27 | 855 |
| 郭内 | 23 | 839 |
学習
この教師データを使って学習する。
まず、設定ファイル(chochin.yaml)を作成する。参考とさせていただいた「じゃんけん検出」と同様、学習データと検証データは同一のものとしている。認識結果が字名そのまま表示されるように、漢字でクラス名を記述した。
# Chochin dataset
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: ./train
val: ./train
# number of classes
nc: 7
# class names
names: ['本町','亀谷','竹田','松岡','根崎','若宮','郭内']
字名(日本語)が正しく表示されるように、オリジナルのtrain.pyに、以下の1行を追加した。
import japanize_matplotlib # 日本語表示のために追加
これを、train_JP.pyとし、以下のコマンドで学習実行した。
python yolov5/train_JP.py --batch 20 --epochs 300 --data './train/chochin.yaml' --name chochin
学習結果
学習が完了すると、yolov5/runs/train/chochinフォルダ以下に、学習結果が保存される。F1カーブと、PRカーブを見ると、うまく学習できているようである。


評価(物体検知)
学習に使った画像とは別に、評価用の画像(各字30枚ずつ)を用意し、testフォルダに格納する。これを以下のコマンドで評価する。
python yolov5/detect.py --weights ./yolov5/runs/train/chochin/weights/best.pt --source ./test/ --data train/chochin.yaml --save-csv --hide-conf --imgsz 1008 756
これで認識した提灯にラベル付けした画像を./yolov5/runs/detect/exp/以下に保存してくれる。各字の認識結果(各1枚)は以下の通り。かなりうまく認識できている。
| 字 | 評価用の元画像 | 認識した画像 |
|---|---|---|
| 本町 |  |
 |
| 亀谷 |  |
 |
| 竹田 |  |
 |
| 松岡 |  |
 |
| 根崎 |  |
 |
| 若宮 |  |
 |
| 郭内 |  |
 |
認識した提灯
前述の通り、丸い提灯の文字は、見る角度によって、さまざまな見え方をするが、以下の通りうまく認識できている。

さらに、提灯の一部しか見えてない場合や傾いている場合でも、うまく認識できている。

「本」の上が一部だけしか映ってない場合も認識できているので、人間を超えた神レベルと言ってもよいかもしれないが、逆に、他の字「若」と区別がつかず、誤認識もしている。(正解は「本町」なのに「若宮」と予測。これは「若」の草冠にも見える。)

表裏で異なる字となる「龜」「谷」は、どちらの字も認識できている。

認識結果一覧
./yolov5/runs/detect/exp/predictions.csv に、画像毎の認識結果(ラベル)の一覧が出力されるので、正解数などの評価指標でまとめる。まず、predictions.csv を以下のコードで一覧化する。なお、集計しやすいように、ファイル名の1文字目は、ラベル(0,1,2,3,4,5,6)としてある。
# 結果まとめ
import pandas as pd
import numpy as np
predict_filename = './predictions.csv'
df_predict = pd.read_csv(predict_filename, header=None)
df_predict = df_predict.rename(columns={0:'filename',1: 'predict',2: 'prob'})
df_predict = df_predict.set_index('filename')
label_list = {
'本町':0,
'亀谷':1,
'竹田':2,
'松岡':3,
'根崎':4,
'若宮':5,
'郭内':6,
}
# 縦:予測、横:正解
np_result = np.zeros([7,7])
for filename, rec in df_predict.iterrows():
label = int(filename[0])
predict = label_list[rec.predict]
np_result[label][predict] += 1
df_result = pd.DataFrame(np_result,index=label_list.keys(),columns=label_list.keys())
df_result = df_result.astype(int)
print(df_result)
縦軸が認識結果、横軸が正解ラベルとなる。
例えば、「本町」と認識したうち、正しく「本町」と認識したのが1885個あり、誤って「亀谷」と認識したのが3個、「若宮」と認識したのが2個、というように見る。よって、対角成分が正解、対角成分以外が間違いなので、0になるのが望ましい。
| 本町 | 亀谷 | 竹田 | 松岡 | 根崎 | 若宮 | 郭内 | |
|---|---|---|---|---|---|---|---|
| 本町 | 1885 | 3 | 0 | 0 | 0 | 2 | 0 |
| 亀谷 | 0 | 1428 | 1 | 0 | 0 | 0 | 1 |
| 竹田 | 0 | 40 | 1225 | 0 | 1 | 0 | 0 |
| 松岡 | 0 | 46 | 1 | 1461 | 4 | 5 | 0 |
| 根崎 | 0 | 2 | 8 | 0 | 1785 | 0 | 0 |
| 若宮 | 0 | 13 | 0 | 2 | 4 | 1738 | 0 |
| 郭内 | 0 | 63 | 32 | 1 | 3 | 3 | 1460 |
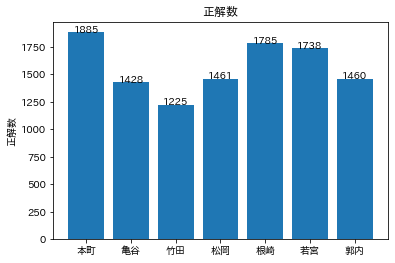
正解数(正しく予測できた数)
この一覧表から、正解数を可視化する。正解数は、この行列の対角成分(np.diag)である。
import matplotlib.pyplot as plt
import japanize_matplotlib
# 正解数(正しく予測できた数)
np_positive = np.diag(np_result)
plt.bar(label_list.keys(),np_positive)
# 数値を表示する関数
def add_value_label(x_list, y_list, number_type='float'):
for i in range(0, len(x_list)):
if number_type=='int':
plt.text(i, y_list[i], '%d' % y_list[i], ha='center')
else:
plt.text(i, y_list[i], '%.2f' % y_list[i], ha='center')
add_value_label(label_list.keys(),np_positive,'int')
plt.title('正解数')
plt.ylabel('正解数')
plt.show()
正解数にはばらつきがある。
第一位は「本町」で最下位が「竹田」。ともに字画が少なく認識しやすそうと予想していたが、異なる結果となったのは以外である。
適合率(予測した中で、正ししく予測できた割合)
# 適合率(予測した中で、正ししく予測できた割合)
np_precision = np.diag(np_result/np_result.sum(axis=0))*100
plt.bar(label_list.keys(),np_precision)
add_value_label(label_list.keys(),np_precision)
plt.title('適合率')
plt.ylabel('適合率(%)')
plt.show()

これも「本町」が第一位。「本町」と予測したものは全て正解100%。
「亀谷」が最下位であり、表裏で違う文字のため、他の字の文字を、「龜」もしくは「谷」と認識しやすかったと考えられる。
特に「郭内」を間違うケースが多く、画像を見ると、「郭」の旁(つくり)も偏(へん)も、どちらも「亀谷」と認識していることがある。どちらも字画が多く認識が難しそうだが、逆に「郭内」を「亀谷」と認識したのは1件と少ない。

再現率(実際の提灯の中で、正しく予測できた割合)
再現率については、写真を見て提灯を数えるのが面倒なので、画像で提灯と検知できた数(他字含む)を分母として計算する。
# 再現率(実際の提灯の中で、正しく予測できた割合)
# -> 写真を見て、提灯数えるのが面倒なので、画像で提灯と検知できた数(他字含む)を分母として計算する
np_recall = np.diag(np_result/np_result.sum(axis=1))*100
plt.bar(label_list.keys(),np_recall)
add_value_label(label_list.keys(),np_recall)
plt.title('再現率')
plt.ylabel('再現率(%)')
plt.show()

再現率は「亀谷」が第一位。適合率と再現率は互いにトレードオフの関係にある、ということが出ている。つまり、「亀谷」は、取りこぼしは少ない(再現率は高い)が、逆に、誤検知が多い(適合率は低い)ということになる。
最下位は、「郭内」。字画が多いので、認識が難しい。「亀谷」と間違えるのは前述の通り63個と最多だが、「竹田」と間違えるのが32個と、次に多い。
F値
適合率、もしくは、再現率だけで評価すると誤解しやすいので、一般に、F値で評価するのがよいとされる。F値は、適合率と再現率の調和平均で求まる。
np_f1_score = 2 * np_recall * np_precision / (np_recall+np_precision)
plt.bar(label_list.keys(),np_f1_score)
add_value_label(label_list.keys(),np_f1_score)
plt.title('F値')
plt.ylabel('F値(%)')
plt.show()

F値でも、第一位は、「本町」である。下位は、「亀谷」と「郭内」。
考察
- 丸い提灯に書かれた文字でもうまく検知、認識できた。
- 特に、字画の少ない「本町」の認識率がよい。(F値で99.86%)
- 同じく、字画の少ない「竹田」は認識が難しかったようだ。「竹田」を「亀谷」と誤認識するケース、「郭内」を「竹田」と誤認識するケースが多く、認識の難しい「亀谷」「郭内」に足を引っ張られたようである。
- 表裏のある「亀谷」や、字画の多い「郭内」は、認識が難しい。(F値は、94.41%、96.59%)
まとめ
360余年の伝統ある二本松提灯祭りは、昔ながらのやり方を守り続けているので、太鼓台が進む・止まるはもちろん、坂を上る・下るや角を曲がるのもすべて人力である。提灯の明かりも、ろうそくの火を灯している。電気はもちろん、ガスや灯油も使っていない。この昔ながらのやり方で灯っている提灯を、現代のテクノロジー(AI)で画像認識できた、ということは対照的であり、面白い結果が得られたと思う。
皆さんのお住まいの地域でも、伝統的なお祭りや行事の特徴的なシーンを画像認識してみてはいかがでしょうか?面白い結果が得られると思います。
おまけ
認識した結果をYouTube動画にしましたので、よかったら、ご覧ください。