はじめに
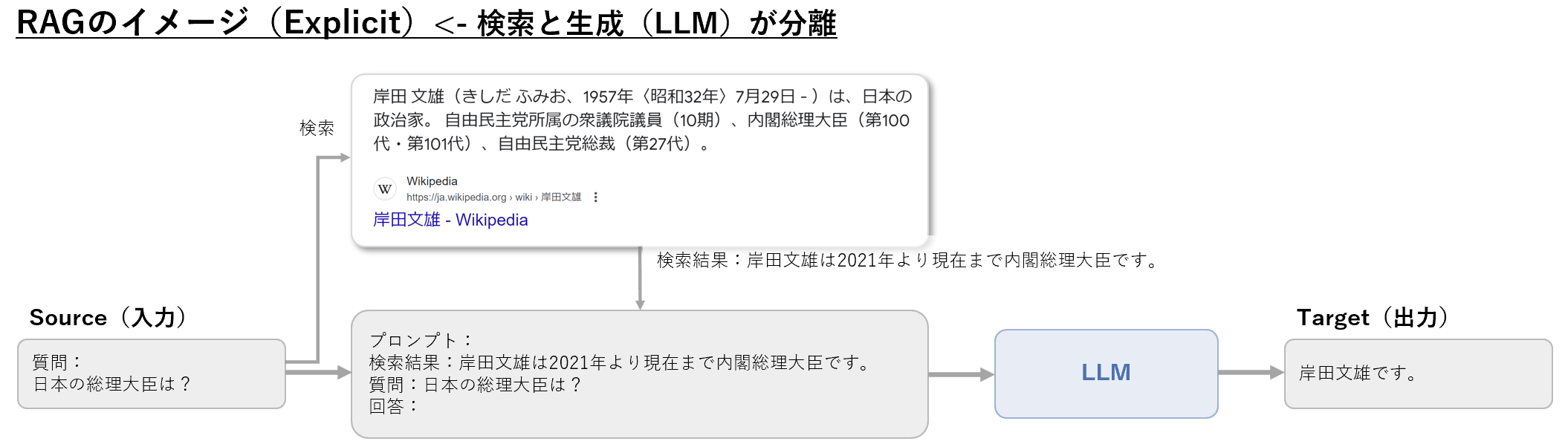
論文「RegaVAE: A Retrieval-Augmented Gaussian Mixture Variational Auto-Encoder for Language Modeling」では、現在の検索機能付き言語モデル2つの主要な課題を概説し、それらに対処するためにRegaVAEを提案しています。検索の方法として、Explicit Aggregation(明示的集約)と、Implicit Aggregation(暗黙的集約)の2つの種類が紹介されています。Explicitな方法として、代表的なものがRAGがあげられます。RAGに関しては、別記事で整理しましたので、興味ある方はこちらの記事も見ていただけるとうれしいです。
コード
背景:現在の検索補強言語モデルの2つの主要な課題
- 検索時には、現在の意味情報だけでなく、将来の意味情報も考慮する必要がある
- 検索された文書とソーステキストを明示的に集約することは、モデル入力の長さによって制限され、ノイズが多すぎる
課題解決:RegaVAEの提案
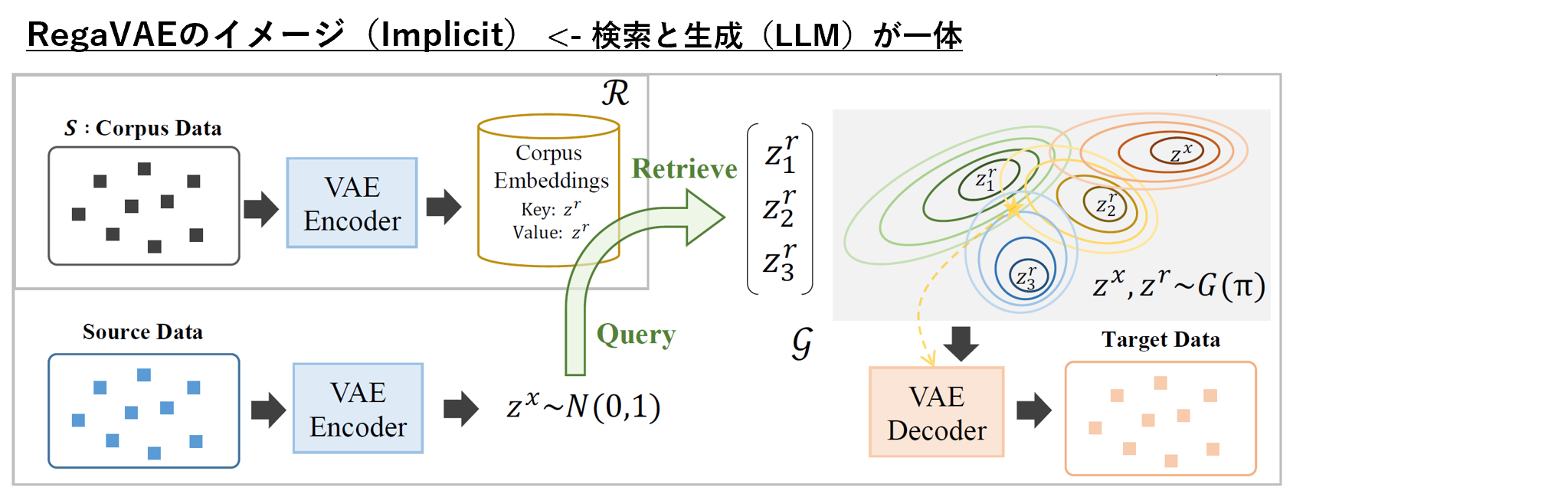
RegaVAEは、Retrieval-Augmented Gaussian Mixture Variational Auto-Encoderの略で、言語モデリングのための新しい手法です。RegaVAEは、Variational Auto-Encoder(VAE)をベースにしたリトリーバル拡張言語モデルで、テキストコーパスを潜在空間にエンコードし、ソーステキストとターゲットテキストの現在と未来の情報を捉えます。
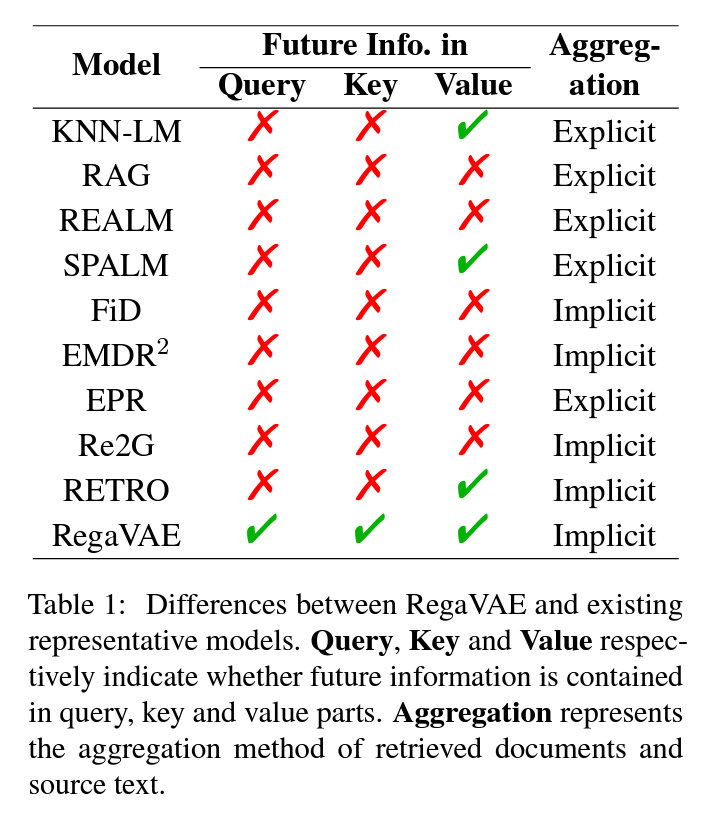
- 現在と未来の情報を暗黙的に結合する検索手法を提案する。これは、Query、Key、Valueの部分に未来の情報を同時に導入することで、文書の類似度が高いほど、生成者にとって有益になるようにするものです。
- 変分オートエンコーダ(VAE)と検索生成の確率論的フレームワークを統合し、効率的なアグレグリーメントを行う。
- 実験によれば、RegaVAEは品質、多様性、幻覚の排除において競争力がある。
モデルのアーキテクチャ
(ChatGPT4で翻訳)
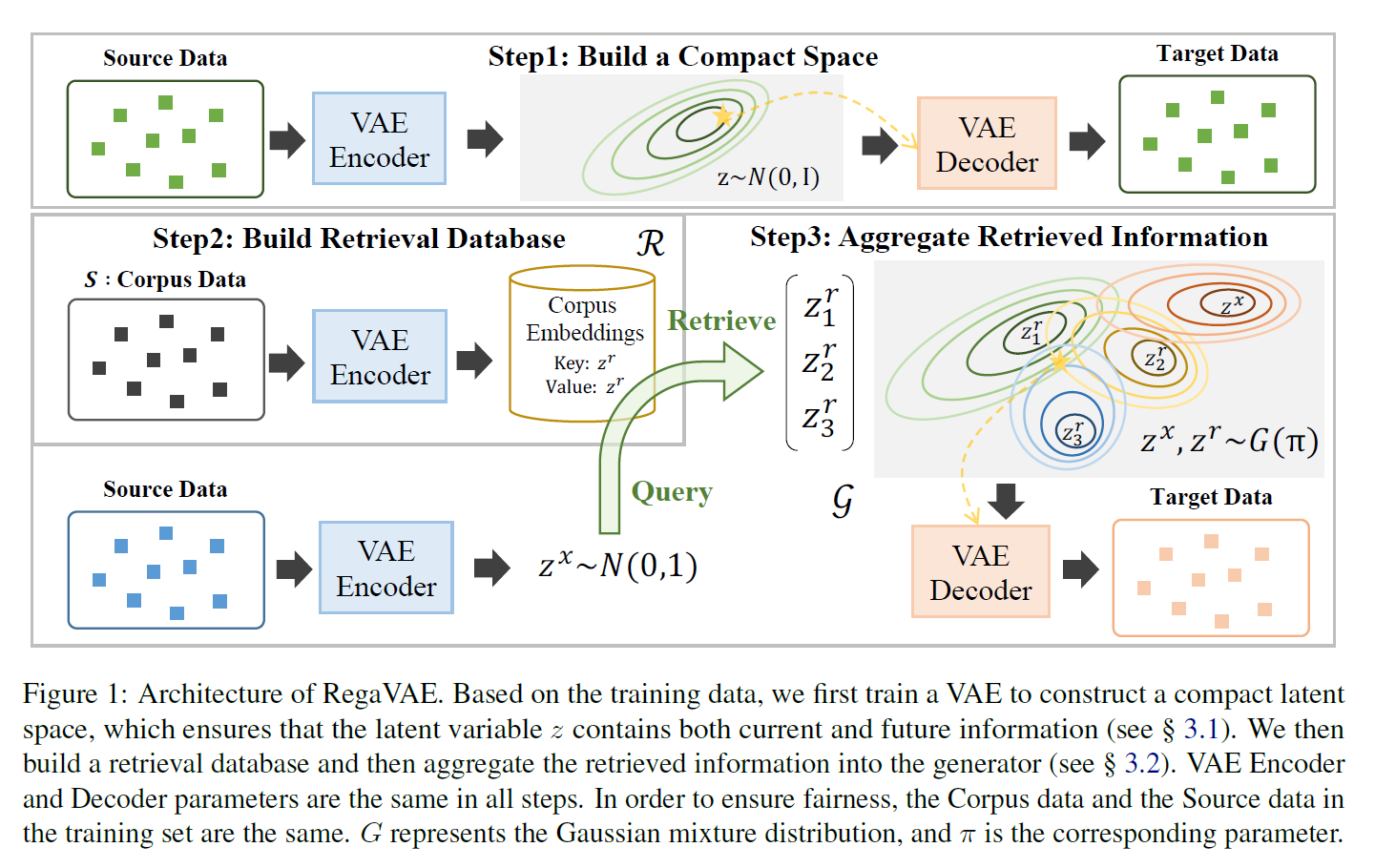
トレーニングデータに基づいて、まずはVAE(変分オートエンコーダ)をトレーニングして、コンパクトな潜在空間を構築します。これにより、潜在変数zが現在および将来の情報の両方を含むようになります(§ 3.1参照)。次に、検索データベースを構築し、そこから取得した情報をジェネレータに統合します(§ 3.2参照)。VAEのエンコーダとデコーダのパラメータは全てのステップで同じです。公平を確保するために、トレーニングセット内のコーパスデータとソースデータは同じものを使用します。Gはガウス混合分布を表し、πはそれに対応するパラメータです。
制約事項
モデルのアーキテクチャから推測できる通り、残念ながら、大規模言語モデル(LLM)での利用今後の課題のようです。
現在の大規模な言語モデルは、大規模なコーパスで事前学習されており、計算リソースの制約のために、RegaVAEを大規模なコーパスで事前学習することはできません。これにより、パフォーマンスが低下する可能性があります。さらに、モデルは事後崩壊問題のために安定していないため、トレーニングが困難です。低ランクのテンソル積を採用しても、この問題は完全に解決できません。
まとめ
RegaVAE自体の利用はまだ難しそうです。が、これからもRAGでの課題を追っていきたいと思います。有効な情報などありましたら、ぜひ情報いただけるとうれしいです。また、記載に誤りなどありましたらご指摘お願いします。