はじめに
LangChainやLlamaIndexを利用したり、フレームワークを利用せずにRAGをしている方も多いと思いますが、今回はRAG(Retrieval-augmented language model)について、その概要とあわせて精度向上について、Llamaindex(v0.9.3.post1)で実現する方法も含めて記載していきます。進化の早い領域ですので、継続して更新していきたいと思います。
RAGとは
RAGとは、「Retrieval Augmented Generation」の略で、情報検索と言語モデル(LLM)を組み合わせた手法のことです。検索結果をLLMのプロンプトに含めるというアプローチが一般的です。

RAGの仕組み
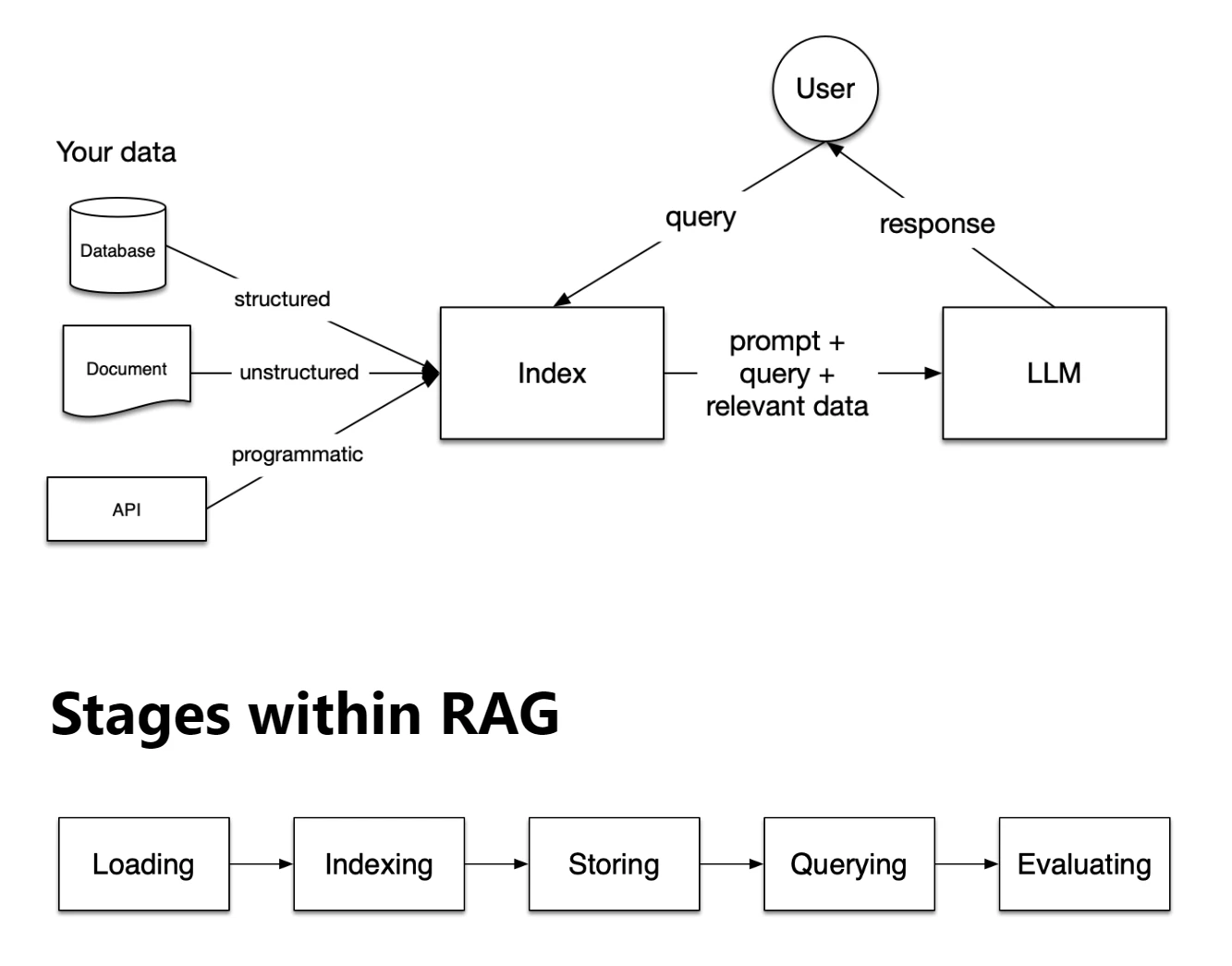
(引用元:LlamaIndex High-Level Concepts )
RAGの精度向上のためにできること
ここでは、Llamaindexでできることも含めて精度向上のためにできることを具体的に見ていきたいと思います。LangChainについては、**『生成AI/RAGで手持ちのソースコード解析(LangChain)』**として別記事に整理しましたので、こちらも参考にしていただけるとうれしいです。
①プロンプト設計
- LLM にはトークン制限があるため、プロンプトと応答内のトークンの数を計算する。
- 理想的なナレッジが手に入った前提でプロンプトを作成し、LLMから正解となる出力が得られるかを確認する(RAGの検索機能を使用せずに確認し、事前にナレッジをデザインしておく)。
②ナレッジの整備
[検索対象のテキストの前処理]
高品質な埋め込みを作るために検索対象のテキストの前処理をする。
- 不要な記号や非標準的な表現などを取り除き、一貫したフォーマットにする。
- 検索対象となる文章が長い場合は、短く要約する。
[データのロード]
- どのような情報でロードされているかを確認する(太字や取り消し線などにも注意)。
- 必要に応じてメタデータをつける(metadataを元にした検索をかけることができる)。
- 必要に応じてrelationshipsを定義する(Documentに木構造等がある場合)。
(Llamaindex)
Llamaindexでは、Node Paserを使用して、DocumentをNode(Documentのchunk)という単位に分割します。
- 使用するモデルのcontext windowに合わせてchunk_sizeを設定する。
- 日本語の文章に適用する場合はNode Paserのtokenizerを確認する(基本的に英語のみに対応)。
- 必要なchunk_sizeが長い場合は、Document Summary Indexや、SentenceWindowNodeParserを検討する。
③検索コンポーネント
RAGにおいて検索コンポーネントは非常に重要です。これは入力クエリに基づいて関連文書を見つける役割を担います。
[ベクトル検索]
- 精度が高い埋め込みモデルをリーダボード(Hugging Faceなど)を参考に選択する。
- 公開されているモデルに対してドメインのテキストで埋め込みモデルを学習する。
- 埋め込み空間に合った類似度を用いる(一般的にはCos類似度が利用されているが、使用するモデル(埋め込み空間)によっては、別の類似度を用いる)。
[インデックスの工夫]
データの特性にあわせてインデックスを工夫する。
- 大規模なデータセットを利用する場合、階層的なインデックス構造の導入を検討する。
- 情報が最新であることを保証するために、定期的にインデックスを更新する。
- データの特性によっては、ベクターインデックス以外のインデックスを検討する。
[クエリ拡張]
複雑なクエリが入ることが想定される場合は、クエリ拡張を検討する(RAGの場合はチャット形式での問い合わせとなるため、特にクエリの設計は重要)。
- 元のクエリに同義語や関連語を追加する。
- 特定のドメインやトピックに関連する追加情報をクエリに組み込む。
- ユーザーの意図やクエリの背景に基づいて、関連する情報をクエリに追加する。
- 複数の類似クエリで問い合わせるなどのクエリ拡張のアプローチを検討する。
(Llamaindex)
Llamaindexは検索システムとしては基本的な機能のみ提供しています。そのため、高い検索性能を要求する場合は、Elasticsearchなどの検索エンジンから検討する必要があります。
- 質問が複雑な場合、クエリ拡張や、Sub Question Queryを検討する。
- LLMにクエリを書き換えさせるQuery Generation/Rewritingを利用する。
- ChromaをはじめとしたVectorDatabaseを利用する(参考:Vector Stores)。
- BM25 Retrieverなどのベクトル検索以外の検索を利用する。
- 複数の検索アルゴリズムを併用するHybrid Searchを利用する。
- LLMでリランキングする(LLM Reranker Demonstration (Great Gatsby))。
④RAGパイプラインの工夫
そもそも検索を必要とするかどうかを確認し、処理を分岐させるか判断します。
- ベクトル検索を用いた場合、similarity scoreを利用して、関連ドキュメントが見つからない場合はRAGを使用しない(コストの観点で推奨)。
- 検索をAgentのtoolとして定義して、LLMに検索を使用するかどうかを決めてもらう。
- RAGを使うパイプラインと使わないパイプラインで生成を行い、最後にリランキングをする。
まとめ
改めて整理してみると、新たな気づきも多く、精度向上にむけて引き続き情報収集&更新をしていきたいと思います。何かお気づきの点などございましたらご連絡いただけるとうれしいです。
参考文献
Retrieval-AugmentedGenerationfor Knowledge-IntensiveNLPTasks
Efficient streaming language models with attention sinks.
https://dev-kit.io/blog/ai/llm-rag-strategies
https://docs.llamaindex.ai/en/stable/optimizing/production_rag.html
https://zenn.dev/kun432/scraps/81813cf6d4e359