業務でLLMを利用する場合に重要となっていくる事実を回答させるためのアプローチ。2024年1月のMicrosoftの『Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs』という論文でFine-Tuning に RAGが勝利したことが示されています。RAGを選択する根拠として活用できそうです。
結論
Fine-Tuning vs. RAG:MMLUと時事問題の両タスクの結果では、RAGに大きなアドバンテージがあった。
[MMLU Results]
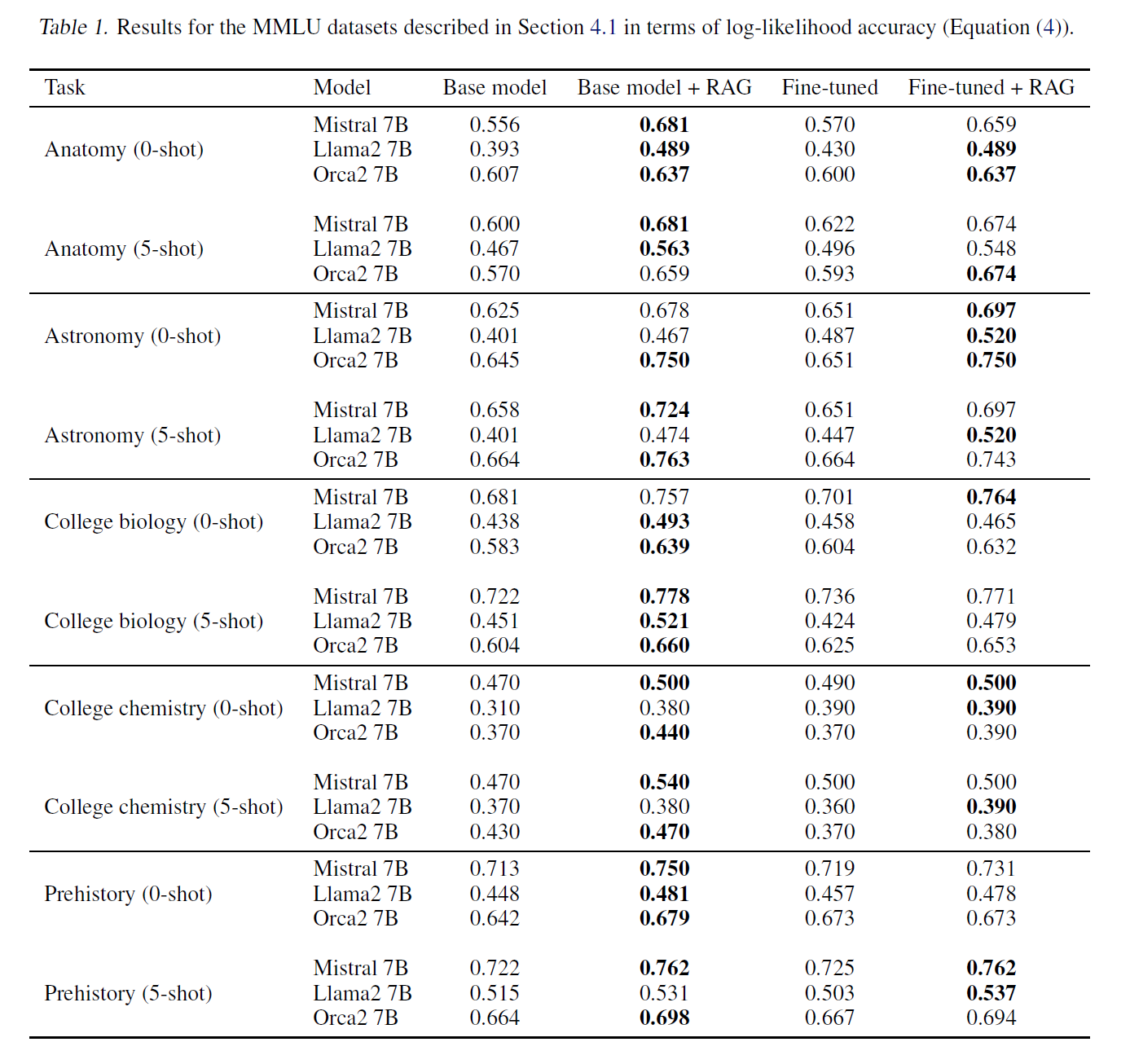
(引用元:論文)
ベースモデル、RAG、FT(Fine-Tuning)、FTとRAGの組み合わせを比較した結果、RAGはすべてのケースでベースモデルよりも優れたパフォーマンスを示した。Fine-TuningされたモデルをRAGのジェネレータとして使用すると、さらなる改善が見られることがあったが、この結果は一貫していない。また、ほとんどのケースで5ショットアプローチが結果をわずかに向上させる傾向がある。
[Current Events Results]

(引用元:論文)
RAGとFine-Tuningを組み合わせることは、RAG単独と比較して性能が劣ることに注意。
背景や評価方法などの詳細
Background
言語モデルにおける事実知識を、モデルが事実に関する質問に正確かつ一貫して答え、真実と偽りを区別できる能力として定義。既にもっていた知識と、新しい事実を区別することが重要。LLMの知識評価は推論、読解、一般的な言語能力の広範なベンチマークが考慮されるべきだが、ここでは主に事実情報を重視。
Causes for Factual Errors
事実的な質問に正確に答えられないモデルレベルの主な5つの原因
- 領域知識の欠如:触れていない特定の分野における包括的な専門知識を欠いている可能性がある
- 時代遅れの情報:最後のトレーニング更新後に発生したイベント、発見、または変化は、外部ソースへのアクセスなしではモデルの知識に含まれていない
- 記憶されないこと:トレーニングデータセットに稀にしか現れない珍しい事実については、触れていても保持していないことがある
- 忘却:Fine-Tuningによって破滅的な忘却と呼ばれる現象が起こり、以前持っていた一部の知識を失ってしまうことがある
- 推論の失敗:複雑な多段階推論タスクや、同じ事実について異なる質問がされた場合に異なる結果が出る場合持っている知識を適切に利用できないことがある
Fine-Tuning
特定の、しばしば狭い範囲のデータセットやタスクで事前トレーニングされたモデルを調整し、その特定の領域での性能を向上させるプロセス
[異なるタイプのFine-Tuning]
-
Supervised Fine-Tuning(SFT):
インストラクションチューニングでは、自然言語のタスクの説明に対して望ましい振る舞いを学習するためのもので、一般的なSFT方法では、モデルに新しい知識を教えることは困難で、知識注入問題の解決には不十分 -
Reinforcemnt Learning:
強化学習を用いたFine-Tuningは、RLに基づく最適化戦略を活用するもので、人間のフィードバックからの強化学習(RLHF)、直接の好みの最適化(DPO)、近接ポリシー最適化(PPO)などがこの分野の主な例。主に応答の品質に焦点を当て、知識の幅を増やすことには限定的 -
Unsupervised Fine-Tuning:
ラベルなしでモデルの学習を継続する方法。この技術は、継続的事前トレーニングや非構造化FTとしても知られ、事前トレーニングフェーズの直接的な継続として行われる。このプロセスでは、次のトークンを予測する方法でトレーニングし、破滅的な忘却を避けるために低い学習率を使用する。教師なしFTは、モデルが事前トレーニング中に蓄積した知識を基にして、新しい情報の学習能力を強化することを目的としている
Retrieval Augmented Generation(RAG)
外部知識ソースを活用して大規模言語モデル(LLM)の能力を特に知識集約的なタスクで拡張する技術。この方法では、補助的な知識ベースと入力クエリから類似した文書を見つけて、それらをクエリに追加し、モデルに更なる文脈を提供する。実装は、補助知識ベースからの文書の埋め込みを作成し、新しいクエリに最も近い文書を検索して、これらをクエリに結合してモデルの出力を得るというプロセスを含む。(※過去にRAGについて記事にまとめていますので、こちらも見ていただけるとうれしいです。)
Task Selection and Rationale
-
MMLU(Massively Multilingual Language Understanding Evaluation)Benchmark:
解剖学、天文学、大学生物学、大学化学、先史学、人文学のタスクを選択。 -
Current Events Task
モデルの学習データのカットオフ後に発生した出来事に関する多肢選択問題(アメリカの「時事問題」)
Experiments and Results
-
Experimental Framework:
知識集約型タスクにおけるLLMの性能を評価するために業界標準となっているベンチマーキングツール「LM-Evaluation-Harness」を使用。 -
Model Selection:
推論評価には、Llama2-7B、Mistral-7B、Orca2-7Bの3つのモデルを使用。また、RAGコンポーネントは、現在のオープンソースのSOTAである、埋め込みモデル:bge-large-en、ベクトルストア:FAISS を使用。 -
Configuration Variations:
ベースラインとFine-Tuningされたモデルと、RAG コンポーネントとの性能を比較。RAG においてコンテキストに追加するテキストチャンクの最適な数を探索し、K∈{0, .5}を採用。5 ショットの性能と0 ショットの性能を比較。 -
Training Setup:
すべてのモデルは4つのNVIDIA A-100 GPUで最大5エポック、バッチサイズ64で学習。 -
Evaluation method:
すべての評価は、質問に対する多肢選択式。選択肢ごとの対数確率スコアを取得し、最も高いスコアをモデルの選択と解釈し、精度計算に使用。
おわりに
Microsoftから出た論文を整理してみました。7Bのモデルでの現段階での1つの評価結果として認識しつつも、RAGを選ぶ1つの根拠として活用したいと思います。今後もRAGについては深堀していきたいと思います。