この記事は、Aimpoint Digital社の有志による執筆記事です。Aimpoint Digital社は、先進的な分析、データサイエンス、エンジニアリングサービスのリーディングカンパニーであり、データから具体的な価値を引き出そうとする企業のための信頼できるアドバイザーとして活動しています。
OpenAIのChatGPTシリーズのような大規模言語モデル(LLM)の出現は、データ分析の分野における無数の新しい機会への道を切り開きました。この強力なモデルによって、コーディングの専門知識を持たない人でも、複雑なデータセットに簡単にアクセスし、理解し、分析することができるようになりました。ただ指示するだけで、データセットを視覚化し、要約し、解釈し、そして洞察を引き出すことができるため、より多くの人々がより幅広くデータ分析能力を活用できるようになってきています。
→Ebookを入手する『企業におけるChatGPT、GPT-4、LLMの使用』
残念ながら、これらのモデルは非常に複雑で、何千行ものコード、何百万もの学習データ、何十億もの学習済みモデルパラメータを含んでいます。これらを使いこなし、特定のユースケースに合わせて調整し、その真価を効率的に発揮させるのは大変なことです。
しかし、これらのLLMをDataikuと統合することで、大規模言語モデルの能力を企業環境で活用することができるようになります。
このブログでは、ChatGPTの会話型プロンプトでデータ分析を可能にするためのさまざまな方法を説明します。組織に迅速に価値を実現するための武器として、ChatGPTのようなツールを探している方も、モデルの活用方法を探しているDataikuユーザーも、このブログを通して、Dataikuと生成系AIのパワーを感じていただけると思います。
ChatGPTの活用例
ユーザーからの会話プロンプトに基づき、レポート、チャート、集計表などを作成するユースケースを作成してみました。アウトプットは高精度、かつデータに適合していて、包括的・効率的なデータ解析・表現手段を提供します。それでは、ここからいくつかの利用例を詳しく解説していきます。
1. ChatGPTを使って、会話プロンプトからPythonコードを生成する
正確なSQLクエリやPythonコードを生成することは、とくにコーディング経験がない人にとっては困難な作業です。ChatGPTは、自然言語のプロンプトからSQLクエリやPythonコードを生成し、データセット上で手軽に実行することができます。
私たちのケースでは、ChatGPTをeコマースのデータセットに使用して、インサイトを生成しました。このデータは、異なる小売業者(Walmart、Costcoなど)の販売情報を時系列でまとめたものです。
ユースケースの目的としては、データに適したPythonコードを生成し、それを実行して結果を得ることでした。異なる小売店の売上高に関連するインサイトを抽出し、各小売店がどのようなパフォーマンスをしているのかを教えてくれます。この分析から抽出されたチャートは、各業者特有のトレンドやパターンをより深く掘り下げるのに役立ちます。
データに適合したコードを生成するためには、モデルへのテキストクエリの一部として、データのスキーマを提供する必要があります。図1では、入力データのスキーマを変数 ’schema’に格納する方法を示しています。

図1. データフレーム 'input_df' のスキーマを収集するコード(このスキーマを利用し、ChatGPTはデータセット上で実行可能なコードを生成する)
次に、ユーザーにプロンプトを入力させます。プロンプトには、データセット名、スキーマ、コードを生成する言語を入力する必要があります(図2)。今回の例では、Costcoで発生したすべてのトランザクションを取得していきます。

図2. ユーザープロンプト、関連するデータセット、スキーマを指定
ChatGPTに対応するため、通常はユーザープロンプトの整形が必要です。これにより、応答はより有用で簡単に実行できるものとなります。下図のように、プロンプトをデータセット名、スキーマ、出力言語でパディングします(図3)。このステップはオプションですが、強く推奨されています。
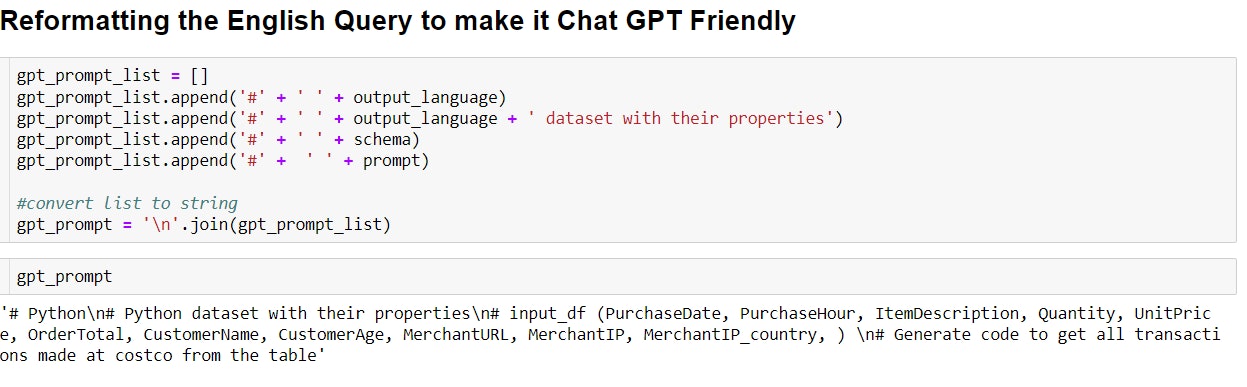
図3. ユーザープロンプトに情報をパディングで追加
ChatGPTにはさまざまなモデルがありますが、今回は言語生成に優れた「text-davinci-003」モデルを使用しました。前のステップで生成した、ChatGPT用のプロンプトをこのモデルに渡し、いくつかのパラメータも設定します(図4)。
temperature(サンプリング温度)は、0が最も創造的でなく(決定論的)、1が最も創造的(確率論的)です。max_tokensパラメータは、テキストの長さに制限を与えるために使用します。これは、ある処理に対して許容するコードの長さに合わせて変更が必要かもしれません。
top_pパラメータは、モデルの創造性/多様性を制御するもう一つの方法です(Open AIでは、temperatureとtop_pのどちらかを使うことを推奨していますが、私たちは両方で実験することを選びました)。penaltyは、生成されるプロンプト内の繰り返しを制御します。デフォルトでは、それらは0に設定されています。
重要なのは、モデルを期待通りに動作させるためには、これらの設定を色々と試してみる必要があるということです。私たちのプロンプトでうまく機能した値が、あなたのプロンプトでも同じように機能するとは限りません。
これらのパラメータを定義した後、API を呼び出してコードを生成できます。

図4. text-davinci-003モデルのパラメータ定義。下部に生成されたコードに注目
コード生成後、実行して結果を確認できます(図5)。
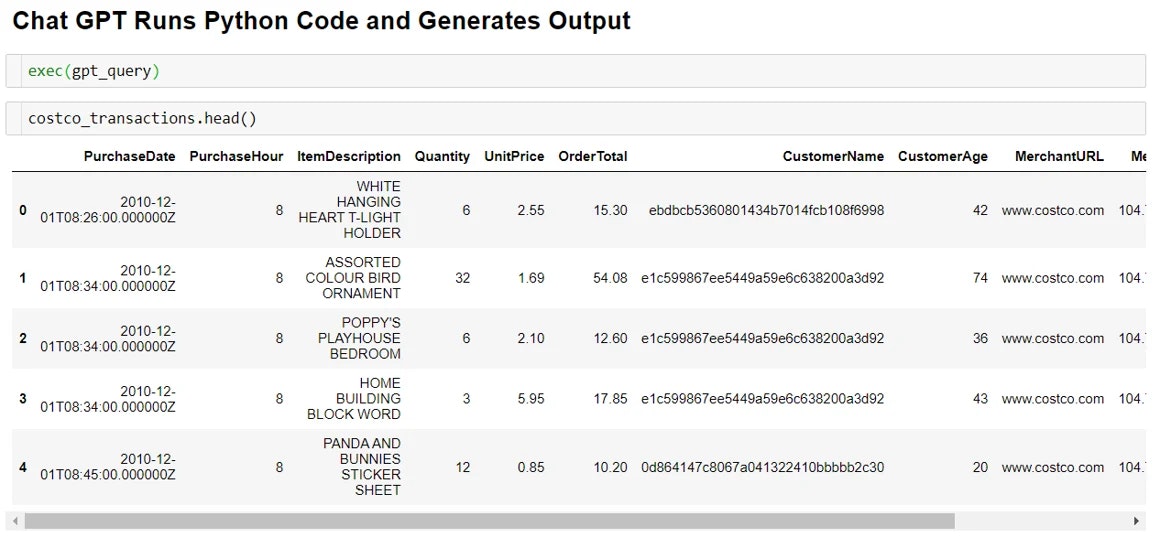
図5. eコマースデータに対して、モデルが生成したコードを実行した結果
2. ChatGPTを使って、技術者でないユーザーにコードを説明する
ChatGPTで生成されるコードは、通常きちんと構造化されていて、内容を理解しやすいですが、技術者でないメンバーに対して、実運用レベルのPythonコードを説明するのはやはり難しい作業です。
ChatGPTは、Pythonコードが何をしているのかを一行一行説明してくれます。ノンコーダーにも分かりやすい言葉でコードを説明してくれるので、コードの民主化を実現できます。技術者でないユーザーも、生成されたコードを十分に理解した上で、実行した結果が正確であることを確認できるので、非常に有用です。このような例を以下の図6に示します。

図6:モデルが生成したコード(各処理にコメントが記述されている)
3. ChatGPTでビジュアル(図表)を生成する
ChatGPTはビジュアルを直接生成できませんが、プロットやチャートなどを表示するためのコードを生成できます。このようなコードをテキストプロンプトから生成できるので、プレゼンテーション用のビジュアルを手早く生成するのにとても便利です。
データ分野におけるその他のLLMの例と同様、応答の質はプロンプトの性質(具体的、かつ明確)に大きく依存します。さらに、出力コードの言語、データセット名、スキーマなどの詳細をプロンプトに追加・パディングすることで、ChatGPTが実際のデータと用途に特化したコードを生成してくれます。
以下の利用例では、eコマースの取引データから円グラフを生成するために、テキストプロンプトを入力していきます。
初めのプロンプト
すべての異なる小売業者で販売された商品の総量を示す円グラフを表示して保存するコードを生成してください。
ChatGPTは上記の内容に基づいてコードを生成できますが、それはおそらく一般的なものであり、私たちの特定のデータセットに直接適用できるものではありません。こちらからの要望を調整するために、いくつかの追加情報(コーディング言語、データセット名、カラム名など)を含むように元のプロンプトにパディングを追加します。
変更後のプロンプト
Python データセット、プロパティ input_df (PurchaseDate, PurchaseHour, ItemDescription, Quantity, UnitPrice, OrderTotal, CustomerName, CustomerAge, MerchantURL, MerchantIP, MerchantIP_country, )
input_df.csvというデータセットを読み込んでください。
すべての異なる小売業者で販売された商品の総量を示す円グラフを表示して保存するコードを生成してください。
修正後のプロンプトはより詳細であるため、最初のプロンプトより優れています。ChatGPTは修正されたプロンプトに基づいて、以下のコードを生成しました。

図7:ECデータを元に円グラフを作成するため、ChatGPTが生成したコード
このコード(図7)はすぐに実行可能で、コードを実行した結果は以下の通りです(図8)。この例では、モデルは完全に正確なコードを生成しましたが、結果のコードに若干の調整が必要な場合があります。エラー無しで望む出力を生成できるようになるまでに必要なコード修正量は、プロンプトの品質に依存します。
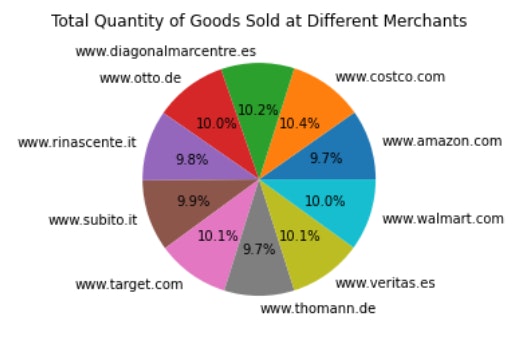
図8:モデルで生成したコードを用いて表示した円グラフ
データ文脈から見たLLMの限界
ChatGPTは、汎用人工知能(AGI: Artificial General Intelligence)の実現を目指す人類にとって、まさに画期的な進歩であるといえます。私たちはまだそのゴールまで到達していませんが、このモデルは多くの人々を驚かせつつ、その後継モデルはさらに発展していくでしょう。
OpenAIによるChatGPTのAPI公開を受けて、世界中の人々がその機能を使ったアプリケーションやプラグインを開発しており、今後地球上で使われるようになります。そのためにも、私たちはLLMの限界・および責任ある利用方法について理解することが必要です。
LLMは間違うことがある
ChatGPTは、天文学的な量のテキストデータに対して綿密な学習を行っています。学習方法は、教師あり学習、強化学習、人間の入力などを組み合わせて、モデルの応答を人間らしく、親しみやすいものにしています。また、モデルが最新の情報に対応できるようにするために、多くの努力が払われています。
しかし、このような多大な努力にもかかわらず、宇宙のすべてのデータを使ってモデルを学習させることは不可能です。そのため、ChatGPTは時折ミスを犯すことがあり、そのミスを発見するのは私たち人間です。このことは、LLMを使ってコードを生成する際に特に留意する必要があります。これらのモデルによって生成されたコードは、時に一般化されすぎていて、あなたが使いたいデータに合わせて変換されないことがあります。用途に合わせてコードを修正し、さらにバグがないかプロセス中のコードを徹底的にレビューすることは、価値を実現する上では不可欠です。
LLMは真にデータを理解しているわけではない
ChatGPTとDataikuのさまざまな応用例を紹介してきましたが、ChatGPTは私たち人間のように真にデータを理解しているわけではないことを理解しておく必要があります。この限界をよりよく理解するために、ある例を考えてみましょう。
米国の国勢調査データを含むデータセットがあります。イリノイ州のクック郡の一人当たりの平均所得を求めたいと思います。ChatGPTが学習中にこの関連データにアクセスしていれば、このプロンプトに対する回答を提供できるかもしれません。しかし、ChatGPTは自動的にデータセットに入り、適切な列を特定し、必要なフィルターを適用し、出力を提供することはできません。ChatGPTにクック郡の一人当たり平均所得を計算するコードを生成するように促すことはできますが、それはおそらく特定の目的・データには直接適用できない汎用的なコードになるでしょう。
このように、ChatGPTはテキスト入力を使ってコードや応答を生成するだけで、私たち人間のようにデータを理解することはできません。クエリをより明示的にすることで、この制約をある程度克服することができます。しかし、ChatGPTからの回答を利用する際には(特にデータ分析に利用する場合には)、注意が必要です。
まとめ
ChatGPTのような大規模言語モデルは、さまざまなコーディングスキルのユーザーを巻き込んで、パワーアップできるため、データ分析の分野を変革しています。ChatGPTとDataikuを組み合わせることで、自然言語処理、コード生成、コードの説明可能性をさらに強固なものとし、より多くの人々にデータ分析を理解してもらうことができるようになります。
ChatGPTは、適切に作成したプロンプトによって、正確なSQLクエリやPythonコードを生成し、データ理解のためのビジュアルを作成することができます。しかし、ChatGPTの限界を認識することも重要です。例えば、真のデータ理解には至らず、間違ったコードや適用できないコードが作成されることがあります。これらの限界を認識し、ChatGPTに質問を投げかけるスキルを磨くことで、ユーザーはモデルの潜在能力を最大限に引き出し、データ分析アプローチに革命を起こすことができます。
ChatGPTのような大規模言語モデルの進化が進むにつれ、データ分析領域における発展と革新の可能性は無限に広がっています。これらの強力なツールを採用し、Dataikuのようなプラットフォームと統合することで、組織は、技術的な専門知識に関係なく、データに基づいた意思決定を行うことができるようになります。
ニュースレター(英語)の購読を申し込む
新しいコンテンツ、製品のアップデート、今後のイベント、そしてDataikuチームが取り組んでいるあらゆることについて、更新情報を毎月お届けします。
→ニューズレター(英語)(を購読する(https://www.dataiku.com/company/newsletter)