2022年12月のOpenAI によるChatGPTのリリースは、非常に多くの注目を集めています。それに伴い、注目される技術範囲は一般的な人工知能から、とくにAIチャットボットを支えるテクノロジーにまで及んでいます。大規模言語モデル(LLM)と呼ばれるこれらのモデルは、限られたトピックに留まらず、あらゆる事項に関するテキストを生成できます。LLMを理解することは、ChatGPTの仕組みを理解するための鍵となります。
LLMが印象的なのは、ほぼすべての言語(コーディング言語を含む)において人間のようなテキストを生成できることです。このモデルこそが過去に類を見ないイノベーションと言われる所以になっています。
この記事では、これらのモデルが何か、どのように開発され、どのように機能するかについて説明します。本編でこのテクノロジーがどのように機能するのかをわかりやすくお話しします。結局のところ、これらのモデルがなぜ機能するのかについての理解は、ほんの一部に留まります。
→企業におけるChatGPT、GPT-4、大規模言語モデル(LLM)の使用
大規模言語モデル(LLM)はニューラル ネットワークの一種である
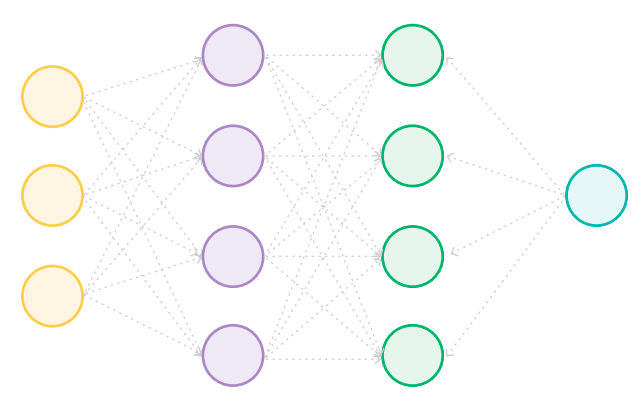
ニューラルネットワークは、ニューロンと呼ばれる多数の小さな数学関数に基づく機械学習モデルの一種です。人間の脳の神経細胞と同じように、最小単位レベルの計算です。
各ニューロンは、人間の脳の様に、入力に基づいて出力を計算する単純な数学関数ですが、ニューラル ネットワークの能力は、ニューロン間の接続によってもたらされます。
各ニューロンは相互に接続されており、各接続の強度は数値の重みによって定量化されています。それらは1つのニューロンの出力が次のニューロンへの入力として考慮される度合いを決定します。
ニューラルネットワークの構成は大小様々です。例えば6つのニューロンと合計8つの接続からなる基本構成もあれば、LLMのように非常に大きな構成もあります。これらは何百万ものニューロンから構成され、それらの間に何千億もの接続があり、各接続には独自の重みを持っています。
LLMはトランスフォーマーアーキテクチャーを利用している
LLMがニューラルネットワークの一種であることは、上述の通りです。より具体的には、LLMはトランスフォーマーと呼ばれる特定のニューラルネットワークアーキテクチャーを使用しており、テキストのように連続したデータを処理、生成するように設計されています。
ここで言うアーキテクチャーとは、ニューロンが互いにどの様に接続されているかを示すものです。すべてのニューラルネットワークは、ニューロンをいくつかの異なる層にグループ化します。層が多い場合、そのネットワークは「深い」と表現され、これが「深層学習」という言葉の由来となります。
非常に単純なニューラルネットワークのアーキテクチャーでは、各ニューロンは、その上の層のすべてのニューロンに接続されます。
また、近くにあるいくつかのニューロンと格子状に接続されるケースがあり、こちらは畳み込みニューラルネットワーク (Convolutional Neural Networks : CNN)と呼ばれます。CNNは画像内のピクセルのようにグリッドで構造化されているため、画像データに対してうまく機能します。
一方で、トランスフォーマーはGoogleの研究者によって2017年に開発され、特定のニューロンがシーケンス内の他のニューロンにより強く接続される(または「より多くの注意を払う」)事を表す「注意」の概念を導入します。
テキスト内の単語は順番に読み込まれますが、文中ではそれぞれ異なる部分を参照したり修飾したりします(例えば、形容詞は名詞を修飾しますが動詞は修飾しません)。
従って、言語処理においてはテキストベースのデータに対して、順序よく動作し、文章に応じて部分間の接続の強さが異なるように構築されたアーキテクチャーが機能するのです。
LLMは自らモデル改善を実施する
簡単に言えば、モデルはコンピュータプログラムです。これは、入力データに対してさまざまな計算を実行し、出力を提供する一連の命令です。
ただし、機械学習またはAIモデルの特徴は、人間のプログラマーは、一連の命令を記述するのではなく、アルゴリズムを設定し、大量の既存データを活用したモデルを構築することです。
LLMの場合、プログラマーがモデルのアーキテクチャーとそれを構築するためのルールを定義します。しかし、プログラマーはニューロンやニューロン間の重みの定義は行いません。これは「トレーニング」と呼ばれるプロセスで行われ、モデルはアルゴリズムの指示に従って、それらの変数を自ら定義します。
また、トレーニングで参照するデータはテキストであるため、場合に応じて一般的にも専門的にもなります。重要なのは、モデルにできるだけ多くの文法テキストを提供して学習できるようにすることです。
数億から数千億円相当のクラウドコンピューティングリソースを消費する可能性があるトレーニングのプロセスで、モデルは学習用のテキストを確認し、独自のテキストを生成していくのです。
最初は解読困難な出力結果となりますが、大規模な試行錯誤のプロセスにて、出力と入力を継続的に比較することで、出力の品質が徐々に向上し、文章がより分かりやすくなります。
十分な時間、コンピューティングリソース、トレーニングデータを利用する事で、モデルは人間が書いたテキストと見分けがつかないテキストを生成することが可能になります。場合によっては、読者が一種の報酬モデルでフィードバックを提供し、テキストが分かりやすいか、そうでないかを伝えることがあります (これは「人間のフィードバックからの強化学習」または RLHFと呼ばれます)。モデルはそのフィードバックに基づいて継続的に改善していきます。
LLMは前の単語に続く単語を予測する?
LLMに関して、「シーケンス内の次の単語を単純に予測する」という説明をする事があります。これは事実ですが、ChatGPTのようなツールが非常に高品質のテキストを生成する可能性があるという事実が述べられていません。「モデルは単純に計算を行っている」と言うのも同様で、モデルがどのように機能するかを理解したり、その効果を評価するのにはあまり役に立ちません。
上記のトレーニングプロセスの結果は、それぞれがモデル自体によって定義された数百万のニューロンと、数千億の接続を持つニューラルネットワークです。大規模なモデルは大量のデータを有し、すべての重みを格納するだけでもおそらく数百ギガバイトになります。
各重みと各ニューロンは、モデルに入力される単語(場合によっては単語の一部)と、モデルが出力する単語(または単語の一部)ごとに計算される数式となります。
技術的な用語として、「小さな単語または単語の一部」は「トークン」と呼ばれます。これは、多くの場合、これらのモデルの使用がサービスとして提供されるときに価格設定される対象になります。
これらのモデルの1つを操作するユーザーは、テキスト形式で入力を提供します。たとえば、次の文章をChatGPTに入力します。
Hello ChatGPT, please provide me with a 100-word description of Dataiku.
Include a description of its software and its core value proposition.
ChatGPTの背後にあるモデルは、その文章をトークンに分割します。平均して、トークンは単語の4/5の規模となるため、上記の文章内23単語で約30トークン程度になります。gpt-3.5-turboモデルには 1,750億の重みが設定されているため、入力テキストの30トークンは、30x1,750億=5.25兆回の計算になります。ChatGPTで現在利用できるGPT-4モデルのウェイト数は明らかになっていません。
次に、モデルは、トレーニングで分析した膨大な量のテキストに基づいて、適切に聞こえる応答の生成を実行します。重要なのは、設定したクエリについて何も調べていない事です。
「Dataiku」、「software」、「value proposition」またはその他の関連用語を検索できるメモリはありません。代わりに、出力テキストの各トークンの生成に取りかかり、1,750億回の計算を再度実行して、正しく聞こえる可能性が最も高いトークンを生成します。
LLM は正しく聞こえるテキストを生成するが、それが正しいとは保証できない
ChatGPTは、出力情報が正しいことを保証するものではなく、正しく聞こえることのみを保証できます。その応答自体は前述の 1,750億の重みに基づいて生成されます。
これはChatGPT固有の欠点ではなく、すべてのLLMの現状の欠点です。例えばデータベースであれば事実となる内容を保管し、確認する事ができますが、LLMの役割は異なります。LLMの強みは、人間が書いたテキストを読み込む事ができ、正しく聞こえるテキストを生成することです。ほとんどの場合、正しく聞こえるテキストは情報自体も正しくなりますが、常に保証されるものではありません。
将来的には、LLMのテキスト生成機能を計算エンジンまたは知識ベースと組み合わせて、説得力のある自然言語テキストで事実に基づく回答を提供するシステムが提供される事も考えられますが、現在はありません。そのようなシステムが見られるようになるまでにどれだけの時間がかかるでしょうか、それは私たちが考えるよりすぐのことかもしれません。
現状可能な事としては、既に所有している情報を自然言語の回答形式でユーザーに提供する場合、ChatGPTに正しい回答を情報提供し、その内容に基づいて回答を作成させることです。
Dataikuでは、まさに上記を実施するために、Dataiku のドキュメントから回答を提供するGPT-3 を利用したデモを開発しています。
GPT-4はLLMなのか?
2023年3月14日、OpenAIはGPTモデルの最新バージョンである GPT-4をリリースしました。GPT-3.5と比較して高品質のテキストを生成することに加えて、GPT-4では画像を認識する機能が導入されています。いずれは画像も生成できるかもしれません。このような機能はまだ利用できるわけではありません。さまざまなタイプ(テキスト、画像、ビデオ、オーディオなど)の入出力データを処理できるということは、GPT-4がマルチモーダルAIであることを意味します。
これら最新モデルの急速な進化に応じて、コミュニティでは「言語モデル」の呼び名は限定的すぎるとの議論があります。「基礎モデル」という用語は、スタンフォード大学の研究者によって一般化されましたが、いくつかの議論が進行中です。テクノロジーそのものと同様、テクノロジーを説明するために使用される言語も急速に進化し続けます。
ChatGPT、GPT-4、および大規模言語モデルの使用について
この記事では、ChatGPTとそのモデルの1つであるgpt-3.5-turboを例として使用しましたが、これは1つのモデルであり、多くの製品のうちの1つに過ぎません。一部の独自LLMは、ChatGPTなどのWebインターフェイスまたはAPIを介してアクセスできますし、他のLLMについてもオープンソースで、必要な計算能力とスキルがあれば、精通したデータサイエンティストまたはエンジニアがダウンロードして実行できます。それぞれのアプローチにはトレードオフがあります。詳細については、以下の記事もご覧ください。
→EBOO『企業におけるChatGPT、GPT-4、大規模言語モデル(LLM)の使用』はこちら
原文: What Is a Large Language Model, the Tech Behind ChatGPT?