アメリカ国立標準技術研究所(NIST)の「信頼と人工知能」レポートによると、「AIは、AIシステムを構築する人々でさえも常に予測できるとは限らない方法で、自身のプログラムを変更する能力を持っている(英語)」とされています。
スプレッドシート、ダッシュボード、ERPシステムとは異なり、AIソフトウェアは再訓練、適応学習、強化学習を通じて、自動的かつ自律的に自身のコーディングを変更することができます。AIはまた、人間の作業者の数千倍の速度で動作するため、AIソフトウェアが害を及ぼすときは、ほとんどの管理者がこれまで見たことのない規模で、悪影響を及ぼす可能性があります。
これらの理由により、AI実践者や開発者は、AIを信頼できるものにするための新しいプロセスを構築する必要があります。しかし、信頼性は非常に相対的なものなので、このタイプの技術開発は難しいと言われます。信頼できるAIは、最前線のユーザーの利用を推進しながら、リスクを管理する上で重要です(どちらも分析とAIプロジェクトの失敗を避けるための必須要素です)。
この2部構成のシリーズでは、これらを掘り下げ、以下の概要もお伝えします:
- リスク、害、バイアスの種類
- 信頼性の主な属性(正確性、信頼性、説明可能性など)
- 信頼できるAIを実践する方法
最前線のユーザーを導入するための信頼できるAI
最も正確なAIモデルでも、使用されなければビジネス価値を生み出すことはできません。
AI開発者が信頼できると考えるものと、経営陣が信頼できると考えるものは異なり、両方ともしばしばエンドユーザーの信頼性とは異なります。これら3つのレベルのうち2つは、技術的ではなく、人間による主観的な判断です。
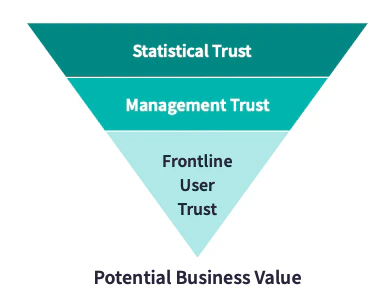
「信頼できる」ということは、データ、AIモデル、AIアプリの属性ではありません。人と、データ、モデル、アプリとの関係であり、人によってのみ作り出されるものです。」
AIの歴史には、最前線のユーザーが信頼しなかったために、統計的には優れていてもビジネス的には失敗したモデルが数多くあります。
実例:デューク大学
デューク大学病院の入院チーム(英語)は、救急室のスタッフが胸の痛みを訴える患者を集中治療室(ICU)に入院させるべきかどうかの判断を支援するAIアプリケーションを開発するのに1年を費やしました。この精度を向上させることで、ICUの作業負荷を減らし、患者ケアを改善し、病院と患者の両方のコスト削減につなげることができます。
しかし、医師たちは自分の仕事のやり方を指示されることに反対し、忙しい救急室のスタッフは、アプリケーションを使用するために必要な入院プロセスの追加ステップを拒否しました。この提案はわずか3週間で却下されました。
リスク管理のための信頼できるAI
AIの潜在的なメリットはユーザーの導入によって促進する一方で、リスク管理は潜在的なデメリットが注目されます。ここでの最初のステップは、「デメリット」を測定できるように、組織の理念と目標に基づいて定義することです。
組織によっては、収益やコストなどの財政的なものかもしれません。また、ブランドの評判や社会的公平性が重視されるかもしれません。組織や状況はそれぞれ異なり、時間とともに変化することがあります。例えば、経済不況時にはコストを重視し、成長期には収益を重視するなどです。
実例:Zillow
Zillowの住宅価格モデルは、リスクが時間と状況とともにどのように変化するかを示す教訓的な事例(英語)です。当初、その予測はZillow.comに表示され、ページ訪問者は自分の家(そして他の家)がどの程度の価値があるかを確認できました。
時間が経つにつれて、モデルは改善され、社内の不動産専門家からなる大規模チームが、短時間で利益を得るために住宅の売買にこのモデルを活用し始めました。それがあまりにもうまくいったため、経営陣は業務をスピードアップするため、意思決定プロセスから人間の専門家を排除し、十分な人間の監視なしに3,000軒の住宅を購入し、5億7,000万ドルの損失を出し、2,000人を解雇しました。
検討すべきAIリスクの種類
リスク = 潜在的な害 × 発生する可能性
ほとんどの業界、組織、部門は、各要素に対して異なる閾値を持っています。医学におけるヒポクラテスの誓いの「まず害を与えるな」は、その大きさに関係なく害を強調しています。アメリカ連邦取引委員会(FTC)は、市民の自由など、いかなる害も許されない特定の害について、リスクを同じ方法で定義しています。実際は、リスクは利益が以下のように比較検討されます。
不公平 = 潜在的な害 × 発生する可能性 – 利益
アメリカでは毎年300人が浴槽で溺死していますが、それでも私たちは浴槽を使っています。1日に80人以上が自動車事故で死亡していますが、毎年1,700万台の新車が販売されています。これは、発生確率が低く、利益が大きいためです。FTCはほとんどのAIリスクについてこの考え方を適用し、メリットとデメリットを同等に重み付けしています。「簡単に言えば... AIの実践がメリットよりデメリットをもたらす場合、それは間違っています。」
考慮すべき害の種類
AIシステムの信頼性(英語)を評価する際、どの種類の害が最も重大かを判断することは、組織の理念と目標によって異なります。害の種類には以下のようなものがあります。

今日、多くのAI実践者は、組織の財務やコンプライアンスなど、ごく一部の潜在的な害にのみ焦点を当てています。AIが普及するにつれて、開発者、管理者、ユーザーはより多くの種類のリスクを考慮し、どのリスクが重要で、本番環境でそれらをどのように測定するかについて、設計時に明確に決めておく必要があります。測定可能な方法で定義されていなければ単なる文書にすぎず、信頼を築くには不十分です。
AIシステムからの害は、通常、開発者が考慮していないか、意図しない結果です。害が発生する一般的な原因は、不良データです。AIモデルが害を及ぼす可能性があるのは、バイアスのかかったデータセットを使用することです:
- 真実を正確に表していない特徴量と目的変数のデータ
- 推論(予測またはスコアリングとも呼ばれる)データセットがトレーニングデータと大幅に異なる
- 悪意のある内部または外部の関係者がデータセットにバイアスを導入する
次のセクションでは、警戒すべきバイアスの種類を説明します。
考慮すべきバイアスの種類
問題は、トレーニングデータ、モデル、推論データにバイアスがあるかどうかではありません(バイアスはあります)。それがどの程度あなたにとって重要かどうかです。AIシステムにおけるバイアスの主な原因は3つあります。

実例:医療における統計的、人的、システム的なバイアス
広く使用されている商用モデルは、医療患者がどの程度の病気であるかを推定します。専任の看護師チームやプライマリケアの予約枠といった希少なリソースは、その推定に基づいて割り当てられます。しかし、このモデルは翌年の医療費を、病気の深刻さを表す変数として使用していました。開発者は、容易に入手できる請求データを使用することで、街灯バイアスを導入してしまいました。問題は、黒人患者は白人患者よりも医療保険の利用が少なく、同じ病状でも請求額が低くなることです。
そのため、同じ病状の場合、モデルは白人患者の方が病状が重く、追加のケアを受けていると推論しました。医療市場における体系的な不平等のため、請求額は目標変数の適切な代理変数ではありません。研究者は、このバイアスが除去されれば、追加のケアを受ける黒人患者の数は160%、つまり2倍以上に増加すると推定しています(英語)。
保護対象のクラスであっても、すべてのバイアスが有害であるわけではないことに注意してください。例えば、多くの小売アパレル製品の推奨モデルは、男性よりも女性に対してより正確な傾向にありますが、これは不公平とはみなされません。各組織は、どのバイアス、害、リスク、敏感なサブグループが自社にとって重要であるかを判断する必要があります。
敏感なサブグループにおけるバイアス検出のための指標
Dataiku — Universal AI Platform™ — は、分析とAIプロジェクト作成者(およびその関係者)が組織の価値観にそって行動し、信頼を高め、バイアスを排除するのに役立つ説明可能性機能を提供します。
トレーニング、推論、予測データにおける敏感なサブグループのバイアスを検出するための指標は多数あります。
人口統計的表現:データセットには、ターゲット集団と同じ敏感なサブグループの分布を持っているか?コルモゴロフ・スミルノフ検定を使用できます。
人口統計的同等性:モデル予測の平均は、全体的および敏感なサブグループについてほぼ同じか?例えば、電話料金を時間通りに支払う可能性を予測している場合、男性と女性についてほぼ同じ支払い率を予測するか?検定、ウィルコクソン検定、またはブートストラップ検定を使用できます。
均等化オッズ:真偽を予測するブール分類器の場合、真陽性率と偽陽性率は敏感なサブグループについてほぼ同じか?例えば、若い成人よりも高齢者に対してより正確か?
機会の平等:均等化オッズに似ていますが、真陽性率のみをチェックします。
平均オッズ差:偽陽性率と真陽性率の差。
オッズ比:陽性結果率を陰性結果率で割ったもの。例えば、(男性が時間通りに請求書を支払う可能性)/(男性が時間通りに請求書を支払わない可能性)を女性のそれと比較。
不均衡な影響:敏感なサブグループの有利な予測率とそれに対する全体集団のそれの比率。
予測率の同等性:モデル精度は異なる敏感なサブグループについてほぼ同じか?精度は、精密度、F値、AUC、平均二乗誤差などで測定できます。
ジニ、テイル、アトキンソン指数も格差を測定するために使用されています。どの指標やテストを使用するかは、AI製品ライフサイクルのどの段階か、そして情報を利用する人々の理解度によっても異なります。例えば、データサイエンティストはテイル指数で満足するかもしれませんが、ビジネス関係者には複雑すぎて信頼を下げる可能性があります。
信頼性の主な属性
信頼できる AI の属性としてはさまざまなものが提案されていますが、中央銀行からグローバル システム インテグレーター、Microsoft、Google に至るまで、正確性、セキュリティ、説明可能性、説明責任が含まれるという点でコンセンサスが得られています。
精度と信頼性
精度はデータとモデルの両方に適用され、データ内では特徴量とターゲット変数の両方に適用されます。特徴量の場合、ヌル値率や分布の変化によって監視される場合があります。ターゲット変数の精度は常に懸念事項であり、特に人間が手動で生成する場合はなおさらです。モデルと同様に、人間にもバイアスがあります。例えば、画像にラベルを付ける場合(猫、犬、車など)、人間のエラー率は最低でも5%ですが、経験豊富な放射線科医でも約20%の確率で矛盾が生じます。
信頼性とは、モデルの精度が想定される条件下で、想定される期間にわたって一貫していることを指します。例えば、数日、1ヶ月、1年間、信頼性が維持されると想定されますか?信頼性の条件と期間について関係者に透明性を保つことで、信頼関係が築かれます。
安全性、セキュリティ、回復力
高リスクのAIシステムは、内部または外部の悪意ある攻撃者による悪意のある攻撃(例えば、悪意を持ってターゲット変数データを変更するなど)から保護する必要があります。また、そのような攻撃を継続的に監視し、可能な限り迅速に検知する必要があります。適切なセキュリティと監視のレベルは、もちろんリスクによって異なります。歯磨き粉のクロスセルを行うAIシステムは、クレジットカード詐欺を検知するAIシステムよりもリスクが低いため、セキュリティ要件が異なる可能性があります。
実例:優良な新規顧客を特定するモデル
回復力は、環境や利用状況の急激な変化にも適用されます。優良な新規顧客を特定しようとした企業が用いた変数の一つは、顧客の所有する車の台数でした。車の台数が多いほど、優良顧客である可能性が高くなります。ニューヨーク市では、複数の車を所有する人のほとんどが裕福であるため、このモデルは有効です。同社は南東部に進出し、同じモデルを現地の人々に適用しました。しかし、南東部の農村部では低所得者層が多くの車を所有する傾向があるため、モデルの精度は急速に低下しました。
同社は多額の損失を被り、事業拡大計画を延期しました。複数の車両という重要な変数の意味が変化していたにもかかわらず、それを迅速に検知できなかったのです。万一、損害が発生したり、バイアスが検出されたり、精度が許容範囲を下回ったりした場合、信頼できるAIシステムは迅速にそれを検知し、関係者に警告を発し、システムを停止、修復、または再トレーニングします。
説明可能性
説明可能性はデータとモデルの両方に適用され、信頼と同様に、見る人の視点によって左右されます。説明に値するAIシステムの構成要素は4つあり、それぞれを説明するべき関係者は4種類あります。
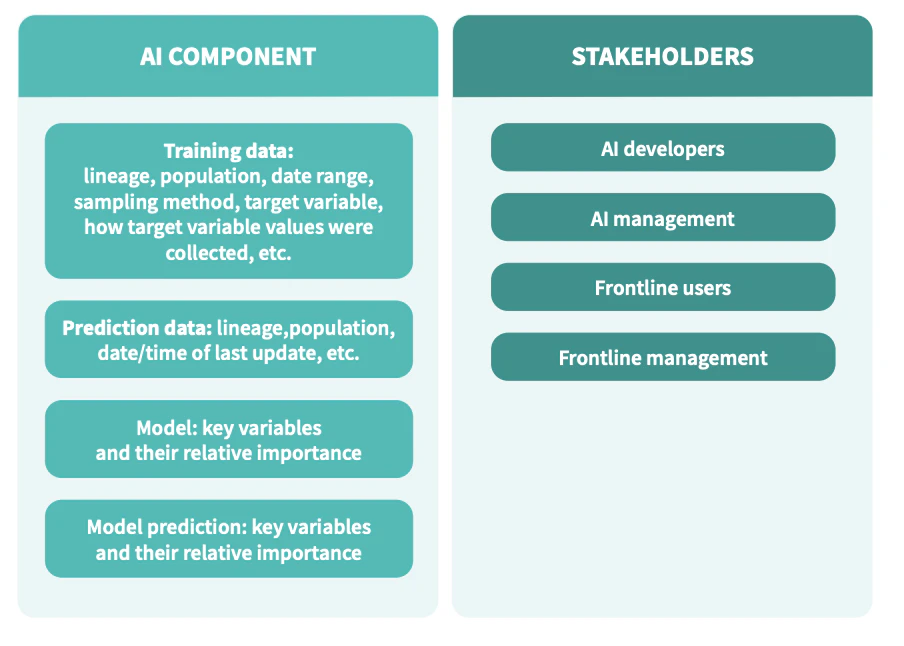
もちろん、データ実務家は、すべてのAIアプリに4つのAIシステム要素すべてを必要とするわけではありません。リスクは大きく異なる可能性があるためです。説明の提示方法も、熟練したエンドユーザーであっても、信頼を高める上で大きな違いを生む可能性があります。
説明責任
被害が発生した場合、誰が責任を負うのでしょうか?ユーザーやその他の関係者は、誰かが責任を負うと考えており、その人物は開発者ではなく、適切な管理職レベルであると考えています。モデルやアプリのドキュメントに責任者を明確に記載することで、信頼関係の構築に役立ちます。
結論
AIシステムは、予測不可能な方法で再学習し、適応する可能性があり、その速度と規模はリスクを増幅させます。信頼を築くには、正確性、説明可能性、そして説明責任を人間の価値観と整合させ、AIの導入を促進し、危害を管理することが重要です。
さらに進む:説明可能なAI基盤の構築
この包括的なページでは、説明可能なAI(XAI)戦略の実装方法、生成AIの時代において説明可能性がこれまで以上に重要である理由、そしてDataikuを活用した説明可能AIへの取り組みについてご紹介します。
→詳細はこちら