データ品質保証(QA)に関するポリシーを導入しなかった場合のリスクは、予防的あるいは事後的に対象した場合も広範に及ぶ可能性があります。たとえば、ステークホルダー向けの自動化されたレポートが誤りまたは破損していた場合、再作業に何時間も費やし、データの価値に対する信頼を失う可能性があります。また、ビジネスアプリケーションで使用されるMLモデルの場合、プロファイリングが不正確であったり、サービスが停止してしまった場合、顧客に重大な影響を与える可能性があります。入力データが有効であり且つ信頼できることを保証することで、ダウンストリームのプロセスとアプリケーションが問題なく実行されることを意味し、データアナリストとエンジニアは、データの再作業に悩まされれる時間を無くすことができます。
しかし、データサイエンスにおいて適切な方法でQAを行うことは、多くの場合、非常に時間がかかります。AIプロジェクトに関わる人々は、80%の時間をデータ準備作業に費やすという統計がよく引用されます。データが複数のソースから取得されると、重複が発生し、ラベルが誤っていることが多いため、データのエンドユースケースに合わせて正確にプロファイリングおよびクレンジングするには、通常、多くの細かい面倒な作業が必要となり、修正作業を何度も繰り返す必要が発生します。
データサイエンスにおけるQAを効率化するためのDataikuの機能
Dataikuは、データサイエンスやアナリティクスプロジェクトにおけるQAを容易にするため、さまざまな機能を提供しています。
1:主要なデータ特性をすばやく表示し、列の分布を事前にpreviewより確認することが可能

データセットのすべての列を一目で視覚的に確認し、潜在的な外れ値や、下流の分析に役立てるためにさらなる処理が必要な列を特定することができます。
2: 視覚的な品質バーを使用して、欠落値や無効な値を簡単に識別する

Dataikuは、データのパターンから推測される豊富なセマンティックな意味を持つデータを自動的に分類します。例えば、日付、メールアドレス、場所、尺度などがあります。品質バーは、割り当てられた意味に対して有効なサンプル内のレコードの割合を示します。これは、データを視覚的にプロファイリングし、潜在的に無効な値を識別する簡単な方法です。これらの意味に対する自動有効性チェックは、単一のカラムに対して設定することも、プロジェクト内のすべてのデータセットにわたる全カラムに対して設定可能です。
3: ファジーマッチングを使用して、テキスト値をスピーディに正規化する

人々が自由形式の値を入力するとき、最終的に単一の値に統合されるべきデータの異なる表現やラベルが存在することが多くあります (例:Registered Nurse vs. RN)。Dataikuを使用すると、ファジーマッチングに基づいたクラスターを作成し、カテゴリラベルを一括して自動的に標準化できます。これにより、手動作業を大幅に削減できます。
4: 検索と置換を使用して不要な文字を削除し、その他数十種類の文字列操作を実行
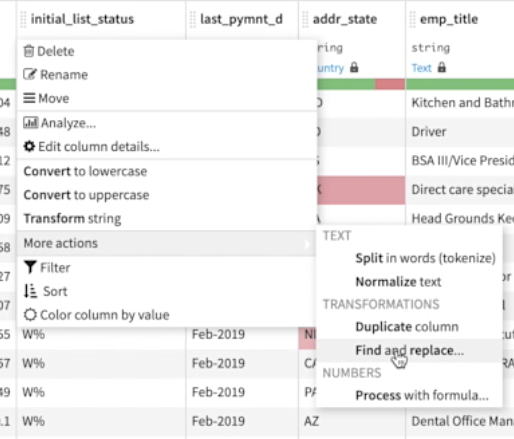
Dataikuには、90種類以上の使いやすいプロセッサが付属しています。便利なプロセッサの1つは検索と置換です。これにより、HTMLマークアップ、引用符などの文字、スペースをアンダースコアに変換して文字列をファイル名フレンドリーにするなど、不要な値をすばやく識別して置き換えることができます。コミットする前にすべての変更をプレビューして、期待通りの結果であるか確認できます。
5: 外れ値と重複を検出し、削除する

Dataikuの分析ポップアップメニューで、Prepareレシピ内の外れ値を処理するためのさまざまなオプションを自動的に識別します。Distinctビジュアルレシピを使用すると、完全なレコードの重複または特定のフィールドのみが重複している行を簡単に削除することができます。
これらは、DataikuがデータサイエンスのQAとデータクレンジングを簡単にすることができるほんの数例です。以下のリンクをクリックして、データ準備をより簡単にするための機能をご覧ください。
Dataikuでデータ準備をさらに向上
Dataikuを使用すると、データの接続、クレンジング、および整理を大幅に高速化できます。プラットフォーム内でのデータ準備に関する便利な機能と概要をこちらをご覧ください。
原文はこちら:QA in Data Science: How to Spend Less Time on Data Prep Tasks for Analytics and AI Projects