1.はじめに
これまでの記事(スクレイピング編,OpenCVでの画像処理編)で自作データセットの作成方法を紹介しました。
本記事では、作成したデータセットを用いて、転移学習を行い日本人と外国人を判断する機械学習モデルの作成方法を紹介したいと思います。
2.今回やりたいこと
機械学習モデルの作成に必要なデータセットを用意する ←前回までの内容
↓
----------ここから本記事でやること----------
↓
転移学習を利用して、機械学習モデルを作る。
↓
機械学習モデルを使って、日本人と外国人の写真を判断する。
3.転移学習とは
転移学習とは一言で表すと、短時間で機械学習モデルの性能を上げるために用いられるモデルの学習方法のことです。
機械学習モデルの性能(精度)は一般的には、機械学習モデルの層が深く、広ければ良くなります。
しかしながら、そのような層が深く、広い機械学習モデルを一から構築しようとすると、膨大な時間とデータが必要となります。
そこで、既存の性能の高い機械学習モデル(VGG16など)の全結合層以外の部分を特徴抽出の層として使用し、その後に全結合層の部分を自分で構築して学習させるのが転移学習です。
これにより、機械学習モデルを一から構築するのに比べ、転移学習では全結合層だけを学習するだけで良いため、短時間で性能の良い機械学習モデルを構築することが可能となります。
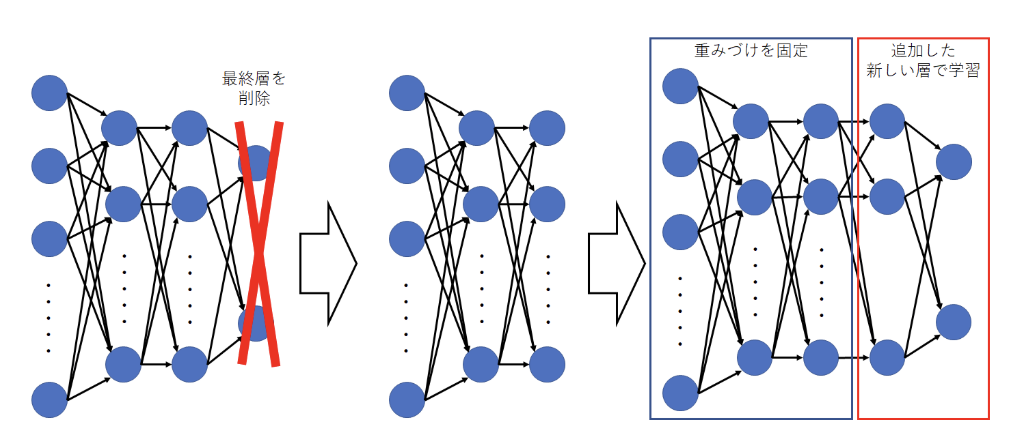
引用元 : 「転移学習とは?ディープラーニングで期待の「転移学習」はどうやる?」
4.ソースコード
以下に今回使用したソースコードをおきます。
from keras.layers import Dense, Dropout, Flatten, Activation
from keras.layers import Conv2D, MaxPooling2D, Input, BatchNormalization
from keras.models import Sequential, load_model, Model
from keras.applications.vgg16 import VGG16
from keras.optimizers import SGD
from keras.preprocessing import image
import numpy as np
import matplotlib.pyplot as plt
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
epochs = 10
# epoch毎のaccuracyとlossをグラフにプロットする
def show_graph(history):
# Setting Parameters
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
# 1) Accracy Plt
plt.plot(epochs, acc, 'bo', label='training acc')
plt.plot(epochs, val_acc, 'b', label='validation acc')
plt.title('Training and Validation acc')
plt.legend()
plt.figure()
# 2) Loss Plt
plt.plot(epochs, loss, 'bo', label='training loss')
plt.plot(epochs, val_loss, 'b', label='validation loss')
plt.title('Training and Validation loss')
plt.legend()
plt.show()
# データセットからデータを取得する
(X_train, y_train, X_test, y_test) = np.load('データセットのPATH')
X_train = np.array(X_train)
X_train = X_train.astype('float32')
X_train /= 255
y_train = np.array(y_train)
X_test = np.array(X_test)
X_test = X_test.astype('float32')
X_test /= 255
y_test = np.array(y_test)
datagen = image.ImageDataGenerator(
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2
)
datagen.fit(X_train)
input_tensor = Input(shape=(64, 64, 3))
# VGG16のデータを読み込む
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(BatchNormalization())
top_model.add(Dropout(0.5))
top_model.add(Dense(2, activation='softmax'))
# vgg16とtop_modelを連結する
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# 19層目までの重みをfor文を用いて固定する
for layer in model.layers[:19]:
layer.trainable = False
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer=SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
history = model.fit_generator(datagen.flow(X_train, y_train, batch_size=32),
steps_per_epoch=len(X_train)/32, epochs=epochs, validation_data=(X_test, y_test))
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
今回データセットから取得するデータは(64*64)のカラー画像データとそのラベルです。
X_train, X_testが画像データ、y_train, y_testがラベルとなっています。
X_trainの中身を見てみると、
print(X_train.shape)
print(X_train[0])
(1547, 64, 64, 3)
[[[ 36 40 50]
[ 40 46 59]
[ 57 64 82]
...
[114 120 124]
[161 155 152]
[141 118 109]]
...
[[203 146 115]
[210 154 123]
[182 128 95]
...
[249 250 248]
[251 243 241]
[228 212 213]]]
のようになっています。
つまりX_trainには1547個の(64*64)のカラー画像が格納されているということです。
また、X_trainに格納されている値は0~255の8ビット符号なし整数型です。
これを255で割って0~1の間に収まる数字にして学習コストを下げることをしています。
y_trainのデータも同様に確認すると、
print(y_train.shape)
print(y_train[0])
(1547, 2)
[0 1]
となっており、X_trainと同じ数だけのone-hot-vectorが格納されていることがわかります。
次にVGG16のモデルを読み込みます。
VGG16のモデルの読み込みについてはKerasのApplicationsのドキュメントに載っているのでそれを参考にします。
今回は引数を3つ設定しています。
include_topはネットワークの出力層側にある3つの全結合層を含むかどうかを表しています。
今回は転移学習をするので、VGG16の全結合層は必要ありません。そのためFalseにしています。
weightsはVGG16の重みを決めるもので、Noneであればランダムの、'imagenet'にすれば学習済みの重みが得られます。
input_tensorは入力画像の大きさを指定するものです。
top_modelはVGG16の後にくっつける全結合層の部分です。
VGG16とtop_modelはmodelというモデルに統合しています。
そして、今回はVGG16の重みはimagenetにおいて学習したものをそのまま利用したいので以下のコードを書いています。
# 19層目までの重みをfor文を用いて固定する
for layer in model.layers[:19]:
layer.trainable = False
5.Google Colaboratoryを使う
転移学習で機械学習モデルを構築すると言っても、使用しているパソコンのスペックが低かったり、データ数が多かったり、epoch数を多くすると、学習に時間がかかってしまいます。
そんな時は、Google Colabratoryを使って機械学習モデルを作りましょう。
Google ColabratoryはGoogleが提供しているjupyter notebook環境です。
このサービスを使う最大の利点というのは、GPUを使って高速に処理をできるという点にあります。
体感ではGPUの有無で処理時間に10倍程度差がつくと思います。
なので、以下にGoogle Colaboratoryで上に書いたソースコードを実行するのに必要な手順を紹介します。
まず最初にGoogle Colaboratoryを開いたら、適当に名前をつけて、次にGPUが使えるように設定を変えましょう。
GPUを使えるようにするには、左上のファイル名のすぐ下にある「編集→ノートブックの設定」ボタンをクリックします。
そうすると以下のような画面が出てくるので、そこで「GPU」を選択します。

これで、このノートブックではGPUが使えるようになります。
次に、以下のコードを打ち込んでnumpyのバージョンを変更します。
pip install numpy==1.16.1
このコードを書く理由としては、上のソースコードでデータセットを読み込むときに、エラーが発生するのを防ぐためです。
次に、ノートブック上にデータセットをアップロードします。
アップロードするにはGoogle Colaboratoryを連携させて、Google Driveにアップロードしたファイルを読み込みます。
連携させるには、以下のコードを打ち込みます。
from google.colab import drive
drive.mount('/content/gdrive')
コードを打ち込むとURLと認証コードを打ち込むエリアが出てきます。

リンクをクリックしてGoogle Driveにログインすると、認証のためのパスワードが出てくるのでそれをコピーして認証コードを打ち込むとGoogle Drive上のデータを使えるようになります。
ノートブック上のディレクトリ構成は(./gdrive/My Drive/)となっています。
そこに自分のGoogle Driveに保存したファイルが保存されています。
6.終わりに
今回は、自作データセットを用いて転移学習を行い機械学習モデルを作成しました。
機械学習は素人でも簡単にコードが書けてしまいますが、その分書いたコードに対する理解が薄くなってしまう可能性があるので、このように自分の書いたコードを振り返るのは大事だなーと思います。
次回は、今回作成した機械学習モデルを利用して、日本人と外国人の顔を判別するwebアプリケーションを作成しようと思います。
参考文献
・Keras Documentatino-Application
・Google Colabratoryの使い方
・Google Colaboratoryの無料GPU環境を使ってみた
・転移学習とは?ディープラーニングで期待の「転移学習」はどうやる?