1. はじめに
近年の機械学習ブームによりプログラミングスクールなどで機械学習について学ぶ人が増えています。
私もその一人だったのですが、プログラミングスクールでは、sklearnやスクールが提供しているデータセットを使用して機械学習を行うことが多いです。
そのため、そのデータセットを使用して制作物を作ると、少し物足りない感じがしたので、自作のデータセットを作ろうと考えました。
そこで今回は自作でデータセットを作りたい人のために今回はSeleniumを使って画像スクレイピングし、大量の画像データを取得する方法を紹介します。
2. 環境
OS : macOS Mojave ver. 10.14.6
言語 : Python 3.7.2
ブラウザ : GoogleChrome ver. 78.0.3904.97
3. 今回やりたいことの流れ
①自作したいデータセットの内容を考える。
今回は機械学習で日本人と外国人を判断しようと考えたので、日本人の画像と外国人の画像を取得する。
②画像検索したキーワードのリストを作成する。
③PythonでSeleniumを起動する。Yahoo画像検索のページに飛ぶ。
④キーワードリストからキーワードを画像検索ページ内の検索窓に自動で入力し、画像検索を行う。
⑤画像検索結果のページに遷移し、画像のサムネイルを複数枚取得する。
③〜⑤が今回解説する部分です。
4. Seleniumの起動から、画像検索のページに飛ぶまで
事前準備として、使用するブラウザのバージョンを確認し、そのバージョンに対応したwebdriverをダウンロードします。
GoogleChromeをブラウザとして使用する場合はこちらでバージョンを確認してください。
また、webdriverのダウンロード(GoogleChrome)はこちら。
それでは、まずpythonでseleniumを起動したいと思います。
from selenium import webdriver
import ssl
import os
ssl._create_default_https_context = ssl._create_unverified_context
url = 'https://search.yahoo.co.jp/image'
# ブラウザを指定して起動する
driver = webdriver.Chrome("webdriverを保存しているpathを指定")
# 指定したurlのページをブラウザ上で開く
driver.get(url)
# ここにpythonでの処理を書く
# ブラウザを閉じる
driver.close()
driver.quit()
これで、GoogleChromeが開き、yahoo画像検索のページが表示されたかと思います。
次に、driver.get(url)からdriver.quit()までの部分にpythonでの処理を書いていきたいと思います。
5. キーワードを自動で入力し、検索する
Seleniumではブラウザを操作して、クリックする、文字を入力するなどの処理を行うことができます。
ここでは、そのような処理部分を書いていきます。
Seleniumの処理部分はこちらのSeleniumクイックリファレンスを参考にしています。
まず、画像検索のキーワードを入力するために、検索窓を探します。
ブラウザで右クリックをすると、「ページのソースを表示」と出てくるので、それを押してページのHTMLのソースコードを確認します。
検索窓の要素を取得するために、要素のCSSセレクタを取得します。
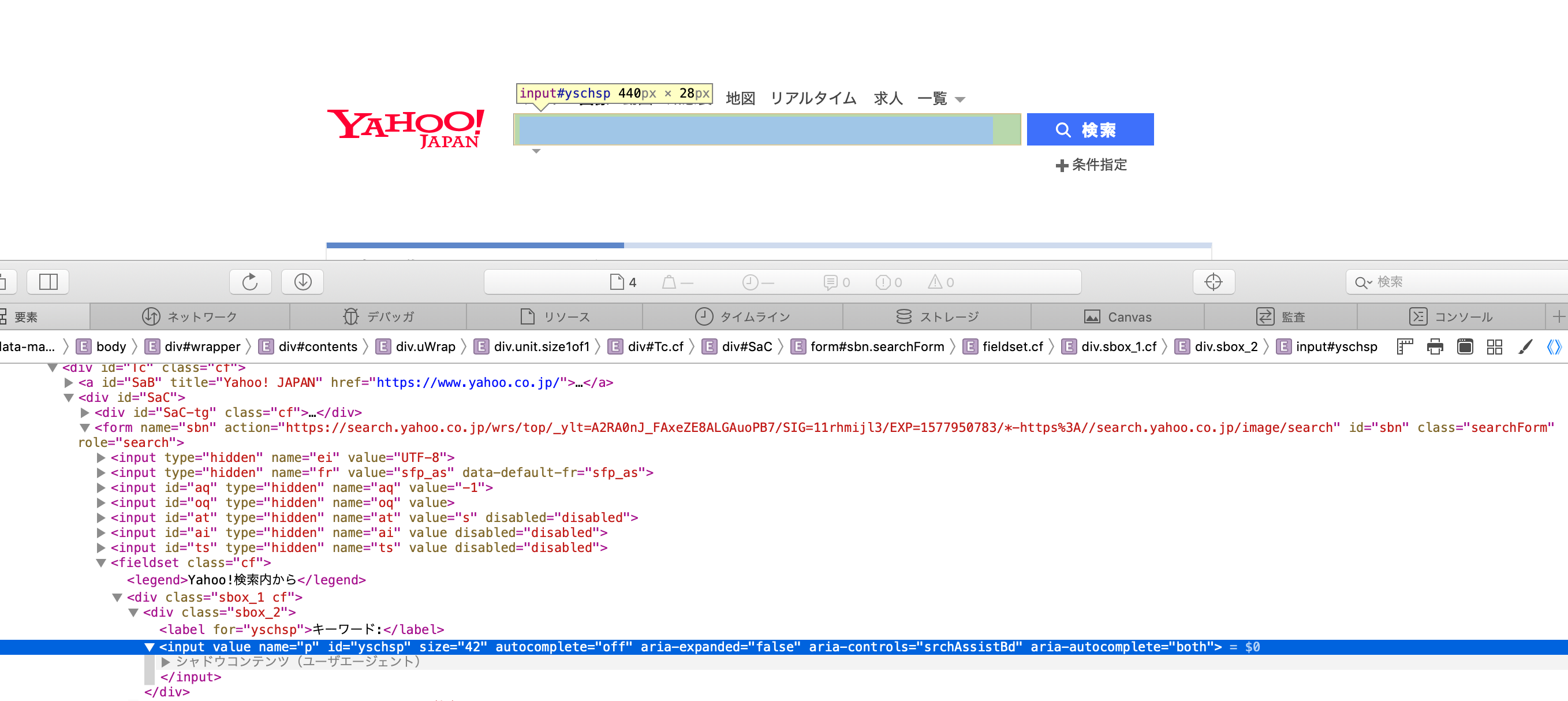
上の画像は検索窓の要素を選択している画面です。(ブラウザはsafari)
この時safariであれば右クリックしてコピー→セレクタのパス をクリックしてCSSセレクタを取得します。
Chromeの場合はcopy→ copy selectorでCSSセレクタを取得できます。
それでは、検索窓にキーワードを入力して検索するコードを書きたいと思います。
# 検索窓にキーワードを入れる
search_box = driver.find_element_by_css_selector("#yschsp")
search_box.send_keys('検索したいキーワードを入力')
# 検索ボタンをクリックする
click_search_button = driver.find_element_by_css_selector('#sbn > fieldset > div.sbox_1.cf > input').click()
driver.find_element_by_css_selector("CSS_selector")に先ほど取得したCSSセレクタを入れます。
それで取得した要素(検索窓)にテキスト入力するには
send_keys('string')で文字列を検索窓上に入力します。
検索ボタンも先ほどと同様にCSSセレクタを指定して要素を取得します。
そして.click()でSeleniumで検索ボタンをクリックします。
.click()を実行すると、実際にブラウザ上でクリックするのと同じように動作します。
6. 検索結果ページから画像を取得する
yahoo画像検索の検索結果表示画面はこのようになっているかと思います。
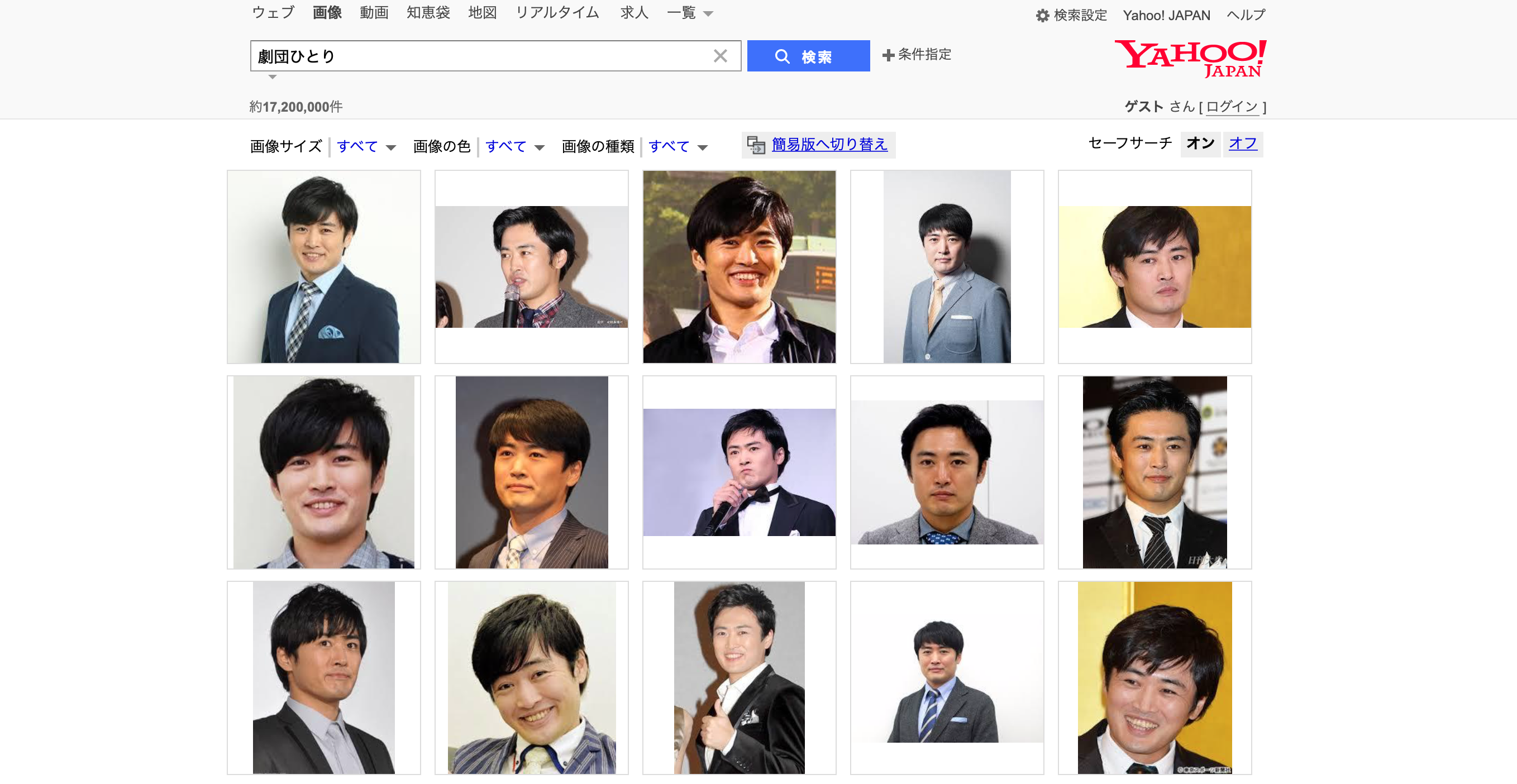
このページから、サムネイル画像を取得したいと思います。
サムネイル画像を取得するためには、サムネイル画像のsrcを取得する必要があるので、
それをスクレイピングで取得したいと思います。
検索結果ページのHTMLコードを見ると、pタグのclass='tb'の下にサムネイル画像を表示しているimgタグがあるので、それを取得したいと思います。
from bs4 import BeautifulSoup
img_url_list = []
# ブラウザ上で表示しているページのソースコードを取得
soup = BeautifulSoup(driver.page_source, "html5lib")
# ソースコードからpタグの中でclass='tb'のものを全て取得してimagesリストに格納
images = soup.find_all('p', attrs={'class', 'tb'})
# imagesリストの要素の中からimgタグのsrcをimg_urlの変数に代入、img_url_listに追加する
for image in images:
img_url = image.find('img').get('src')
img_url_list.append(img_url)
return img_url_list
コード内ではまずimagesという変数にリストを代入して、そのリストからimgタグを探しています。
これは、取得するimgタグをpタグのclass='tb'内にあるものに限定することで、
サムネイル画像以外の画像を取得しないようにするためです。
これにより、取得したimg_url_listより画像をローカルに保存していきます。
import requests
import os
os.chdir('画像保存先のpathを指定')
# yahoo画像検索の結果から先頭10枚の画像を指定したディレクトリに保存
for i in range(10):
img_url = img_url_list[i]
img = urllib.request.urlopen(img_url).read()
with open('img{}.jpg'.format(i), 'wb') as file:
file.write(img)
以上、紹介したものを順番に実装していけば大量の画像をスクレイピングで取得できるはずです。
7. おわりに
今回はSeleniumで画像スクレイピングをする方法について紹介しました。
次回はデータセットとして使用できるように、ラベル付けや画像処理の部分を書きたいと思います。
もし記事を読んで分からないところが多い、このように改善した方が良いなどがあればコメントをお願いします。