はじめに
大学院を卒業したら,AIの研究職に…
いかないので,何年後かに見ても思い出せるようにコードを置いておきます.
Kaggle記事
こちらは全コードを載せています.より実践的なものとしてKaggeleでのタスクをまとめてあります.
RNNはすごくわかりやすいKaggeleのNotebookを見つけたので,それを載せています.(自分でRNN解くのがめんどくさかった…とかじゃないよ…うん…)
- DNN
- Classification
- Regression
- RNN
- Time Series Forecast
- Classification
- CNN
- Classification
- Segmentation
※ RNNのClassificationはKaggeleで見つけられなかったので,心電図の不整脈種類分類タスクのURLを載せています.しかしChainerで書かれています…(私はChainerアンチ)まぁ参考程度に.実際に自分でタスクするならPytorchで書き直すことをお勧めします😀
※ SegmentationはTutorial的なコンペがなく,すぐまとめられそになかったので現段階(2023/02/11時点)では載せれてません.
DNN(Base)
基本的な部分はDNNで書きます.
CNN・RNN・Segmentationはそれぞれ変化がある部分だけ載せます.
必要なライブラリをimportします.
pipなりcondaなりで環境にインストールしておいてください.
これら2つはどっちかに統一してください.混同すると環境壊れるこもがあるらしいっす![]()
俺はpip派です![]()
import os
import cv2
import random
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import TensorDataset
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
#import timm
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
import pandas as pd
import seaborn as sn
# Validation
from torchvision import datasets
from torch.utils.data.dataset import Subset
# n分割交差検証
# テスト・学習をn分割してn回の平均精度を出す
# Validationは学習に分類されたものから何割かを持ってくる
from sklearn.model_selection import KFold
from sklearn.model_selection import StratifiedKFold
# モデルの保存
import pickle
# グラフのスタイルを指定
plt.style.use('seaborn-darkgrid')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
データセットの用意です.
今回は自前ではなく,IRISデータを使います.
Deepに入れるようにデータをTensorにしときます.
from sklearn.datasets import load_iris
iris = load_iris()
X_data = iris.data
y_data = iris.target
y_data = y_data.reshape(-1, 1)
OH_y_data = OneHotEncoder().fit_transform(y_data).toarray()
print(X_data.shape)
print(OH_y_data.shape)
X_tensor = torch.Tensor(X_data).to(device)
y_tensor = torch.Tensor(OH_y_data).to(device)
dataset = TensorDataset(X_tensor, y_tensor)
batch_size = 4
Train,Validation,Testの処理部分です.
def train_epoch(model, optimizer, criterion, dataloader, device):
train_loss = 0
model.train()
for i, (images, labels) in enumerate(dataloader):
#labels = labels.type(torch.LongTensor)
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
train_loss = train_loss / len(dataloader.dataset)
return train_loss
def validation(model, optimizer, criterion, dataloader, device):
model.eval()
val_loss=0
with torch.no_grad():
for i, (images, labels) in enumerate(dataloader):
#labels = labels.type(torch.LongTensor)
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
val_loss += loss.item()
val_loss = val_loss / len(dataloader.dataset)
return val_loss
def inference(model, optimizer, criterion, dataloader, device):
model.eval()
test_loss=0
with torch.no_grad():
for i, (images, labels) in enumerate(dataloader):
#labels = labels.type(torch.LongTensor)
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
test_loss += loss.item()
test_loss = test_loss / len(dataloader.dataset)
return test_loss
EarlyStoppingの実装です.
Patience回連続でValidationLossが更新されなければ,学習を打ち止め.最もValidationLossが下がったEpochのモデルを採用します.
class EarlyStopping:
def __init__(self, patience=10, verbose=False, path='checkpoint_model.pth'):
self.patience = patience
self.verbose = verbose
self.counter = 0
self.best_score = None
self.early_stop = False
self.val_loss_min = np.Inf
self.path = path
def __call__(self, val_loss, model):
score = -val_loss
if self.best_score is None:
self.best_score = score
self.checkpoint(val_loss, model)
elif score < self.best_score:
self.counter += 1
if self.verbose:
print(f'EarlyStopping counter: {self.counter} out of {self.patience}')
if self.counter >= self.patience:
self.early_stop = True
else: #ベストスコアを更新した場合
self.best_score = score
self.checkpoint(val_loss, model)
self.counter = 0
def checkpoint(self, val_loss, model):
if self.verbose:
print(f'Validation loss decreased ({self.val_loss_min:.6f} --> {val_loss:.6f}). Saving model ...')
torch.save(model.state_dict(), self.path)
self.val_loss_min = val_loss
RUN部分です.
Epoch分だけTrain・Validation・Testします.
EarlyStoppingで早く終了する場合もあります.
def run(num_epochs, optimizer, criterion, device, train_loader, val_loader, test_loader,model):
train_loss_list = []
test_loss_list = []
val_loss_list = []
earlystopping = EarlyStopping(verbose=True)
for epoch in range(num_epochs):
train_loss = train_epoch(model, optimizer, criterion, train_loader, device)
val_loss = validation(model, optimizer, criterion, val_loader, device)
test_loss = inference(model, optimizer, criterion, test_loader, device)
print(f'Epoch [{epoch+1}], train_Loss : {train_loss:.4f}, test_Loss : {test_loss:.4f}')
train_loss_list.append(train_loss)
test_loss_list.append(test_loss)
val_loss_list.append(val_loss)
earlystopping(val_loss_list[-1], model)
if earlystopping.early_stop:
print("Early Stopping!")
break
return train_loss_list, val_loss_list, test_loss_list
結果の混同行列です.
def graph(train_loss_list, val_loss_list, test_loss_list):
num_epochs=len(train_loss_list)
fig, ax = plt.subplots(figsize=(4, 3), dpi=100)
ax.plot(range(num_epochs), train_loss_list, c='b', label='train loss')
ax.plot(range(num_epochs), val_loss_list, c='r', label='test loss')
ax.plot(range(num_epochs), test_loss_list, c='m', label='val loss')
ax.set_xlabel('epoch', fontsize='10')
ax.set_ylabel('loss', fontsize='10')
ax.set_title('training and test loss', fontsize='10')
ax.grid()
ax.legend(fontsize='10')
plt.show()
def print_confusion_matrix(test_loader,model,cv_y_true,cv_y_pred):
model.eval()
y_true,y_pred = [],[]
with torch.no_grad():
for i, (images, labels) in enumerate(test_loader):
labels = labels.type(torch.LongTensor)
images, labels = images.to(device), labels.to(device)
outputs = model(images)
for nval in range(len(labels)):
print(f"{outputs[nval]}\t{labels[nval]}")
y_true.append(torch.argmax(labels[nval]))
y_pred.append(torch.argmax(outputs[nval]))
for leny in range(len(y_true)):
y_true[leny] = y_true[leny].item()
y_pred[leny] = y_pred[leny].item()
## CV ALL CONFUSION MATRIX
cv_y_true.append(y_true)
cv_y_pred.append(y_pred)
target_names = ['0', '1', '2']
cmx = confusion_matrix(y_true, y_pred)
df_cmx = pd.DataFrame(cmx, index=target_names, columns=target_names)
plt.figure(figsize = (6,3))
sn.heatmap(df_cmx, annot=True, annot_kws={"size": 18}, fmt="d", cmap='Blues')
plt.show()
print(classification_report(y_true, y_pred, target_names=target_names))
print("accuracy: ", accuracy_score(y_true, y_pred))
モデルです.
今回は全結合だけの非常にシンプルなモデルです.活性化関数にReLUを挟んでいます.
'''モデルの定義'''
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.fc1 = nn.Linear(4, 100)
self.fc2 = nn.Linear(100, 50)
self.fc3 = nn.Linear(50, 3)
self.lsf = nn.LogSoftmax(dim=1)
self.sf = nn.Softmax(dim=1)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
x = self.lsf(x)
return x
交差検証のための準備です.
# RUN
cv = StratifiedKFold(n_splits=5, random_state=0, shuffle=True)
cv_y_true,cv_y_pred = [],[]
メイン部分です.
上記で実装した関数を呼び出していきます.
for i,(train_index, test_index) in enumerate(cv.split(X_data,y_data)):
model = RNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(),lr=0.001)
#optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# train/test 分割
cv_train_dataset = Subset(dataset, train_index)
cv_test_dataset = Subset(dataset, test_index)
# validation作成
n_samples = len(cv_train_dataset) # train の大きさ
train_size = round(n_samples * 0.75) # train の1/4をバリデーションにする
subset1_indices = list(range(0,train_size))
subset2_indices = list(range(train_size,n_samples))
strain_dataset = Subset(cv_train_dataset, subset1_indices)
val_dataset = Subset(cv_train_dataset, subset2_indices)
train_loader = DataLoader(strain_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(cv_test_dataset, batch_size=batch_size, shuffle=False)
# run
print(f"***FOLD {i}")
train_loss_list, val_loss_list, test_loss_list = run(500, optimizer, criterion, device, train_loader, val_loader, test_loader,model)
model = pickle.load(open('check_point_model.sav', 'rb'))
# PLOT
graph(train_loss_list, val_loss_list, test_loss_list)
print_confusion_matrix(test_loader,model,cv_y_true,cv_y_pred)
print("-----------------\n")
cv_y_true = list(itertools.chain.from_iterable(cv_y_true))
cv_y_pred = list(itertools.chain.from_iterable(cv_y_pred))
# Deep
target_names = ['0', '1', '2']
cmx = confusion_matrix(cv_y_true, cv_y_pred)
df_cmx = pd.DataFrame(cmx, index=target_names, columns=target_names)
plt.figure(figsize = (6,3))
sn.heatmap(df_cmx, annot=True, annot_kws={"size": 18}, fmt="d", cmap='Blues')
plt.show()
print(classification_report(cv_y_true, cv_y_pred, target_names=target_names))
print("accuracy: ", accuracy_score(cv_y_true, cv_y_pred))
CNN
フォルダの配置
- data
- Cat
- Dog
import timm
DATADIR = "C:/Users/~~/data" # Change Own DataPATH
# 各ラベル
CATEGORIES = ["Cat", "Dog"]
# リサイズ後のサイズ
IMG_SIZE = 300
training_data = []
def create_training_data():
for class_num, category in enumerate(CATEGORIES):
path = os.path.join(DATADIR, category)
for image_name in os.listdir(path):
try:
# 画像読み込み
img_array = cv2.imread(os.path.join(path, image_name),)
# 画像のリサイズ
img_resize_array = cv2.resize(img_array, (IMG_SIZE, IMG_SIZE))
# 画像データ、ラベル情報を追加
training_data.append([img_resize_array, class_num])
except Exception as e:
pass
create_training_data()
random.shuffle(training_data) # データをシャッフル
X_data = [] # 画像データ
y_data = [] # ラベル情報
# データセット作成
for feature, label in training_data:
X_data.append(feature)
y_data.append(label)
# numpy配列に変換
X_data = np.array(X_data)
X_data = X_data.transpose(0,3,1,2)
y_data = np.array(y_data)
DataAugmentation用の関数です.
image_transform = transforms.RandomOrder([
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),
transforms.RandomPosterize(bits=4),
])
share_transform = transforms.RandomOrder([
transforms.RandomErasing(),
transforms.RandomHorizontalFlip(),
transforms.RandomResizedCrop(IMG_SIZE, scale=(0.8, 1.2)),
transforms.RandomAffine(degrees=[-10, 10],translate=(0.2, 0.2)),
])
def fix_seed(seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
Trainの時のみDataAugmentationを行います.
def train_epoch(model, optimizer, criterion, dataloader, device):
train_loss = 0
model.train()
for i, (images, labels) in enumerate(dataloader):
# DataAugmentation ------#
### FIX SEED
seed = random.randint(0, 2**32)
### IMAGE
images = images.to(torch.uint8)
fix_seed(seed)
images = share_transform(images)
images = image_transform(images)
images = images.to(torch.float32)
#------------------------#
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
outputs = torch.sigmoid(outputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
del images,labels,loss,outputs
train_loss = train_loss / len(dataloader.dataset)
return train_loss
モデルはTIMMから,ImageNetで事前学習されているモデルをファインチューニングして使います.
for i,(train_index, test_index) in enumerate(cv.split(X_data,y_data)):
# モデル指定
TIMM = timm.create_model('tf_efficientnetv2_s_in21ft1k', pretrained=True, num_classes=2)
model = TIMM.to(device)
###############################################################
# 重み変更
weights0 = 50.0
weights1 = 100.0
w0 = float(weights0)
w1 = float(weights1)
all_zero = [float(0.0) for i in range(2)]
all_zero[0] = w0
all_zero[1] = w1
weights = torch.tensor(all_zero)
# 同デバイスに載せる
weights = weights.to(device)
###############################################################
criterion = nn.CrossEntropyLoss(weight=weights)
optimizer = optim.Adam(model.parameters())
# train/test 分割
cv_train_dataset = Subset(dataset, train_index)
cv_test_dataset = Subset(dataset, test_index)
# ↑保存
"""
listname = 'train_index_'+str(i)+'.txt'
pickle.dump(train_index, open(listname, 'wb'))
listname = 'test_index_'+str(i)+'.txt'
pickle.dump(test_index, open(listname, 'wb'))
"""
# validation作成
n_samples = len(cv_train_dataset) # train の大きさ
train_size = round(n_samples * 0.75) # train の1/4をバリデーションにする
subset1_indices = list(range(0,train_size))
subset2_indices = list(range(train_size,n_samples))
strain_dataset = Subset(cv_train_dataset, subset1_indices)
val_dataset = Subset(cv_train_dataset, subset2_indices)
train_loader = DataLoader(strain_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(cv_test_dataset, batch_size=batch_size, shuffle=False)
# run
print(f"***FOLD {i}")
train_loss_list, val_loss_list, test_loss_list = run(300, optimizer, criterion, device, train_loader, val_loader, test_loader)
# PLOT
graph(train_loss_list, val_loss_list, test_loss_list)
print_confusion_matrix(test_loader,model)
"""
# モデルを保存
filename = 'timm_test_model_'+str(i)+'.sav'
pickle.dump(model, open(filename, 'wb'))
# train_lossの推移を保存
listname = 'train_loss_list_'+str(i)+'.txt'
pickle.dump(train_loss_list, open(listname, 'wb'))
# val_lossの推移を保存
listname = 'val_loss_list_'+str(i)+'.txt'
pickle.dump(val_loss_list, open(listname, 'wb'))
# test_lossの推移を保存
listname = 'test_loss_list_'+str(i)+'.txt'
pickle.dump(test_loss_list, open(listname, 'wb'))
"""
# 各実行の最後のLossを保存
fold_train_list.append(train_loss_list[-1])
fold_val_list.append(val_loss_list[-1])
fold_test_list.append(test_loss_list[-1])
print("-----------------\n")
交差検証全体の混同行列を出力します.
import itertools
## CV ALL
target_names = ['anomaly', 'nomaly']
cv_y_true = list(itertools.chain.from_iterable(cv_y_true))
cv_y_pred = list(itertools.chain.from_iterable(cv_y_pred))
cmx = confusion_matrix(cv_y_true, cv_y_pred)
df_cmx = pd.DataFrame(cmx, index=target_names, columns=target_names)
plt.figure(figsize = (6,3))
sn.heatmap(df_cmx, annot=True, annot_kws={"size": 18}, fmt="d", cmap='Blues')
plt.show()
print(classification_report(cv_y_true, cv_y_pred, target_names=target_names))
print("accuracy: ", accuracy_score(cv_y_true, cv_y_pred))
CNN-GradCAM
CNNの注目画素を可視化する手法です.
下記URLから"pytorch_grad_cam"をダウンロード.
https://github.com/jacobgil/pytorch-grad-cam/tree/master/pytorch_grad_cam
下記関数をTRAIN終了後に実行.
from pytorch_grad_cam import grad_cam
from pytorch_grad_cam.utils import image
def print_GradCAM(test_loader,model,cv,TEST_NAME_LIST):
model.eval()
for i, (images, labels) in enumerate(test_loader):
#labels = labels.type(torch.LongTensor)
#images, labels = images.to(device), labels.to(device)
target_layers = [model.conv_head] # Choice final Convolution Layer
cam = grad_cam.GradCAM(model = model, target_layers = target_layers, use_cuda = torch.cuda.is_available())
target_category = None
grayscale_cam = cam(input_tensor = images, targets = target_category)
grayscale_cam = grayscale_cam[0, :]
# plot用のイメージ
vis_image = images.cpu().numpy()
for n in range(len(labels)):
vis_image_plot = vis_image[n].transpose(1,2,0)
vis_image_plot = (vis_image_plot/ 255.).astype(np.float32)
visualization = image.show_cam_on_image(vis_image_plot, grayscale_cam, use_rgb = True)
visualization = cv2.bitwise_not(visualization)
cv2.imwrite("GRADCAM/" + TEST_NAME_LIST[i*batch_size + n] + ".png", visualization)
RNN
RNNの入力形式にデータを合わせてくれれば,Okです.
RNN・LSTM・GRUはそれぞれ"nn."を前につけるだけで実装完了です.(Pytorchならね
'''モデルの定義'''
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.LSTM(num_features, 1000, batch_first=True)
self.fc1 = nn.Linear(1000, 200)
self.fc2 = nn.Linear(200, 2)
self.sf = nn.Softmax(dim=1)
self.relu = nn.ReLU()
def forward(self, x):
x, hidden = self.rnn(x, None)
#x = self.fc1(x[0])
x = self.fc1(x[:,-1,:])
x = self.relu(x)
x = self.fc2(x)
x = self.sf(x)
return x
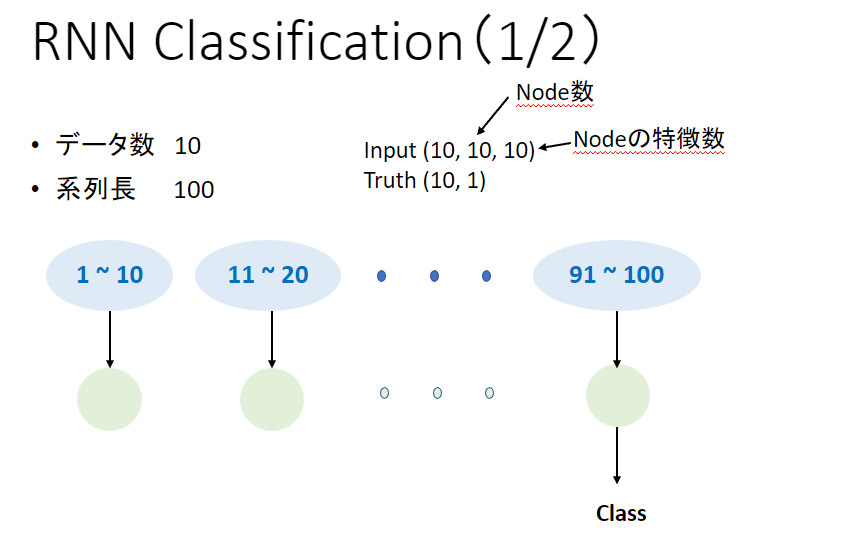
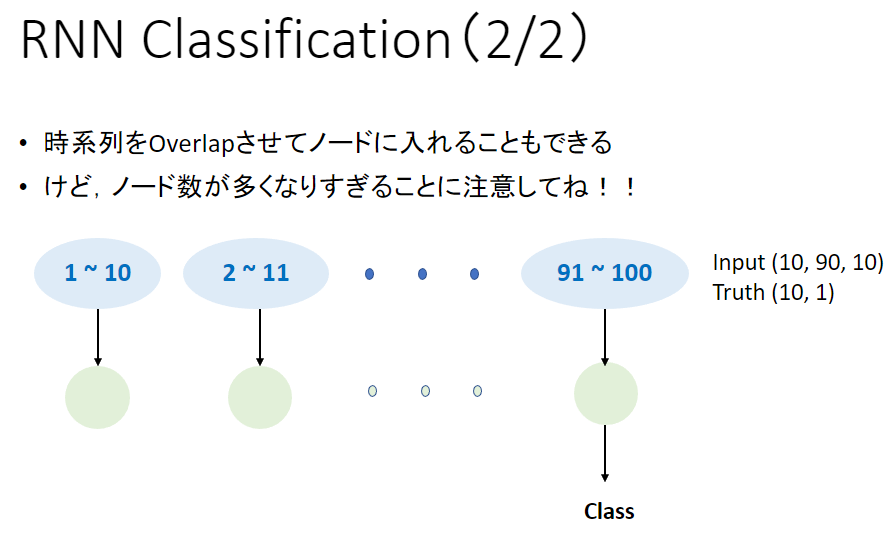
- RNN Classification
Segmentation
セグメンテーションは,Inputが画像,GTruthも画像,出力も画像です.
DataAugmentationは,IMAGEとGTruth両方に対して行います.GTruthは0,1の数値になっているので,色彩等をAugentationするとダメです.なので,GTruthにたいしては回転などの処理だけを行うようにしましょう.
def train_epoch(model, optimizer, criterion, dataloader, device):
train_loss = 0
model.train()
for i, (images, labels) in enumerate(dataloader):
# DataAugmentation ------#
### FIX SEED
seed = random.randint(0, 2**32)
### IMAGE
images = images.to(torch.uint8)
#fix_seed(seed)
images = share_transform(images)
images = image_transform(images)
images = images.to(torch.float32)
### LABEL
fix_seed(seed)
labels = share_transform(labels)
#------------------------#
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
outputs = torch.sigmoid(outputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
del images,labels,loss,outputs
train_loss = train_loss / len(dataloader.dataset)
return train_loss
画像を保存します.入力はそのまま,GTruthは(0,1)を(0,255)にしてから出力します.
出力は,(0,1)の範囲になっている筈なので,0.5以上の場合255,以下の場合0にします.
def save_image(image_number,pimg,plab,pout):
input_path = os.path.join(OUTPUT_DATADIR, "IMAGE")
corect_path = os.path.join(OUTPUT_DATADIR, "MASK")
output_path = os.path.join(OUTPUT_DATADIR, "OUTPUT")
# Original Image
pltimg = pimg.transpose(1,2,0)
cv2.imwrite(os.path.join(input_path, image_number),pltimg)
# Ground Truth
pltlab = plab.reshape(IMG_SIZE,IMG_SIZE)
pltlab = np.where(pltlab == 1, 255,0)
cv2.imwrite(os.path.join(corect_path, image_number),pltlab)
# Model Output
# Set a threshold(HyperParameter)
pltout = pout.reshape(IMG_SIZE,IMG_SIZE)
pltout = np.where(pltput > 0.5, 255, 0)
cv2.imwrite(os.path.join(output_path, image_number),pltout)
return pltlab,pltout
Segmentationの精度を出力する関数です.
def segmentation_score(plab_mask,plout_mask):
smooth=1
inputs = np.ravel(plab_mask)
targets = np.ravel(plout_mask)
i_and_t = inputs & targets
intersection = i_and_t.sum()
FP = inputs.sum() - intersection
FN = targets.sum() - intersection
recall = (intersection + smooth) / (intersection + FN + smooth)
precision = (intersection + smooth) / (intersection + FP + smooth)
dice = (2*precision*recall) / (precision+recall)
iou = (intersection + smooth) / (inputs.sum() + targets.sum() - intersection + smooth)
return recall,precision,dice,iou
def print_SCORE_IMAGE(test_loader,model,crossval,all_recall,all_precision,all_dice,all_iou):
model.eval()
recall_list = []
precision_list = []
dice_list = []
iou_list = []
with torch.no_grad():
for i, (images, labels) in enumerate(test_loader):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
pimg = images.to('cpu').detach().numpy().copy()
pimg = np.vectorize(int)(pimg)
plab = labels.to('cpu').detach().numpy().copy()
plab = np.vectorize(int)(plab)
pout = outputs.to('cpu').detach().numpy().copy()
for li in range(len(pimg)):
###### IMAGE
# image_numbe
image_number = str(crossval)+"_"+str(i)+"_"+str(li)+".png"
# save image
plab_mask,plout_mask = save_image(image_number,pimg[li],plab[li],pout[li])
###### SCORE
recall,precision,dice,iou = segmentation_score(plab_mask,plout_mask)
recall_list.append(recall)
precision_list.append(precision)
dice_list.append(dice)
iou_list.append(iou)
# PLOT
print(f"RECALL :{statistics.mean(recall_list)}")
print(f"PRECISION:{statistics.mean(precision_list)}")
print(f"DICE :{statistics.mean(dice_list)}")
print(f"IOU :{statistics.mean(iou_list)}")
## CV_ALL
all_recall.extend(recall_list)
all_precision.extend(precision_list)
all_dice.extend(dice_list)
all_iou.extend(iou_list)
メイン部分です.
# List for CV
all_recall,all_precision,all_dice,all_iou = [],[],[],[]
# FolderName for CV
ListForCV = ["1","2","3","4","5"]
# Input Data Path
INPUT_DATADIR = "C:/Data/" # Change Your DataDir
for i in range(1,6):
print(f"***FOLD_{i}")
#* CreateDataset
TRAIN_DATADIR1 = INPUT_DATADIR + ListForCV[0]
TRAIN_DATADIR2 = INPUT_DATADIR + ListForCV[1]
TRAIN_DATADIR3 = INPUT_DATADIR + ListForCV[2]
VAL_DATADIR = INPUT_DATADIR + ListForCV[3]
TEST_DATADIR = INPUT_DATADIR + ListForCV[4]
train_dataset = TrainDataForCV(TRAIN_DATADIR1,TRAIN_DATADIR2,TRAIN_DATADIR3)
val_dataset = DataForCV(VAL_DATADIR,0)
test_dataset = DataForCV(TEST_DATADIR,1)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
#* MODEL
model = UNet.UNet(n_channels=1, n_classes=1)
model = model.to(device)
#* Loss & Optimizer
# UNet3plus => Adam
# UTNet => SGD
criterion = nn.BCELoss()
#criterion = diceloss()
optimizer = optim.Adam(model.parameters(), lr=0.0001)
#optimizer = optim.SGD(model.parameters(), lr=0.0001, momentum=0.9)
#* run
train_loss_list, val_loss_list, test_loss_list = run(1, optimizer, criterion, device, train_loader, val_loader, test_loader,model)
model = pickle.load(open('check_point_model.sav', 'rb'))
pickle.dump(model, open('model1.sav', 'wb'))
#* PLOT
graph(train_loss_list, val_loss_list, test_loss_list)
print_SCORE_IMAGE(test_loader,model,i,all_recall,all_precision,all_dice,all_iou)
#* rotate list
pop = ListForCV.pop(0)
ListForCV.append(pop)
#break
## Plot CV Mean Score
"""
print("\n\n\n*** ALL_RESULT ***")
print(f"RECALL :{statistics.mean(all_recall)}")
print(f"PRECISION :{statistics.mean(all_precision)}")
print(f"DICE :{statistics.mean(all_dice)}")
print(f"IOU :{statistics.mean(all_iou)}")
"""