はじめに
DeepLearning では様々なデータを扱います.テーブルデータ,画像,3D,時系列,etc. 何を使うにしても必要となる技術についてまとめておきます.(自分の為も兼ねて)
1 DNNの基本
1.1 DeepLearning って??
例えば,よくある画像の分類について考えます.
🐶と😼の画像分類をしたいとき,学習データを用意して,それをDeepLearning で学習します.すると,この写真に写ってるのは🐶?😼?といった問題を解けるようなものが出来上がります.
これはつまり,関数(F)を作っているのです.
DeepLearning とは,F(写真)=🐶みたいなことができるということです.(簡単に言えばね)
具体的にどんなタスクがあるかをまとめてくれている記事があるので,気になる人は確認してください.
Deep Learningの各種タスクにおけるベンチデータセットとデータ数をまとめた
1.2 全結合層
名前の通り,次の値を決める際に1つ前の層全ての値を用いる手法です.DeepLearning の一番シンプルな形で,Linear層やDence層とも呼ばれます.
参考書を開くとまず出てくる構造ですね.あやとりみたい🧶

1.3 活性化関数
活性化関数とは,先ほど話したように1つ前から次の層に値を渡すときにひと手間加える関数です.
大きな値,特徴として強い部分を強調し,弱い部分は小さくします.必要な特徴を選んで強調することで,学習を活性化させる役割を担っています.
いくつか代表的な関数を載せておきます.

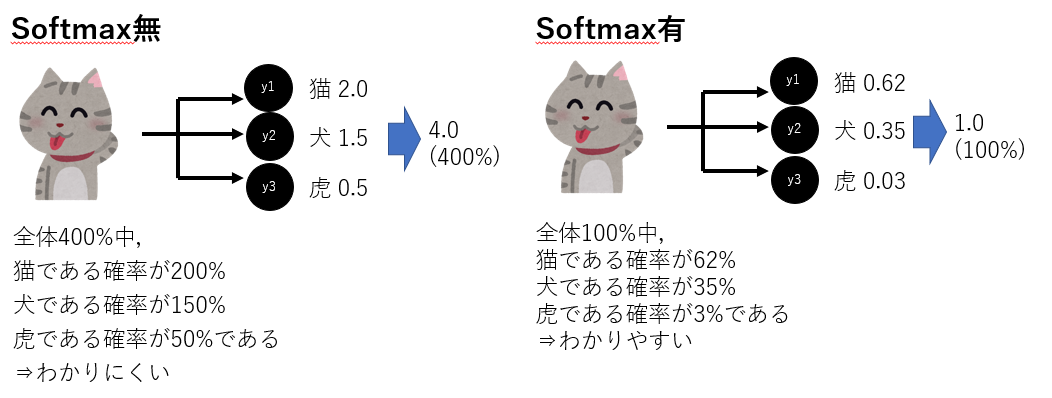
また,多クラス分類の出力にはSoftmax関数を用います.概要は下図の通りです.全体を1.0として,各値を確立値として出力します.
1.4 Loss関数
Loss関数(損失関数)とは,モデルの出力と正解の差を評価する関数です.モデルはこの値をできるだけ下げるように学習を進めます.Loss関数にも種類がたくさんあり,タスクや必要なスコアを鑑みて何を使うか決めましょう.自分で定義するのもありです.
また,重みを設定することで,クラス不均衡への対策も可能です.クラス分類に使われるCrossEntropyLossだと,pytorchの標準実装に重み引数が設定されています.
🐶と😼の分類をしたい時に,🐶は1000枚あるのに😼は10枚しかない!というようはことがよくあります.そんなときに重みを何も設定しないと,Deepちゃんは「ほとんど🐶やし,”全部🐶やろ”」と出力してきます.こういう時に重みを(🐶1,😼100)とかにしてあげるとデータ数の少ない😼に対しても,ある程度推測してくれます.これは,正解が😼の時の誤差の値を100倍にすることになります.すると,モデルはここの値を必死で下げようと動くわけです.どうにか😼を間違えないように学習してくれるわけですね.
100:1は極端ですが,絶対に間違えたくないクラスの重みを大きく設定するなど処理も可能です.別クラスのスコアは下がるので,トレードオフにはなりますが…
2 特徴分布
そもそもの話ですが,やろうとしているタスクがDeepLearning を用いて解決可能か否かを確かめる必要があります.🐶😼のような簡単な問題ならまぁできそうな気がしますが,研究でするようなタスクはそうはいきません.まず,機械からして分類可能かどうかを大まかに図る必要があります.
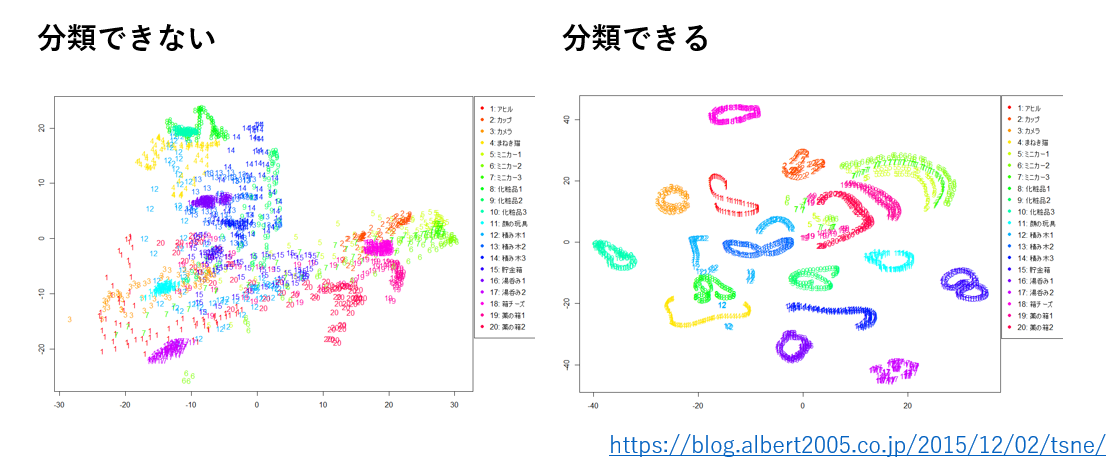
そのために低次元化を行うことがあります.DeepLearning で使用するようなデータは大抵大きな次元を持ったデータです.それらのデータ分布を見える化して確認しようと思ったときに,2次元や3次元まで特徴を圧縮する必要があります.手法は様々で,主成分分析・t-SNE・UMAP等があります.中でもUMAPはt-SNEより実行が高速で,より距離関係をはっきり表してくれます.
そのようにして得た特徴分布がクラス毎に全くまとまっていなければ,そのデータを用いても良い結果は得られないでしょう.データの前処理等を工夫する必要があります.逆にクラス毎にまとまっている,更に分布間が離れていると,それらのクラス間の特徴に差があるということなので,機械学習で良い結果を得られると予想されます.
データの事前分析は大事ですね.
3 Validation
学習データ・テストデータはわかりやすいと思いますが,DeepLearning を学習させる際には検証データ(Validation Data)が必要です.
DeepLearning には,過学習という現象があります.DeepLearning は何度も反復して学習することで,だんだん精度が上がっていくのですが,この時使っているのは学習データだけです.つまり,学習データに特化したモデルになっていくわけです.これをやりすぎると,学習データについてはカンペキ,テストデータについては全然なモデルが出来上がってしまいます.
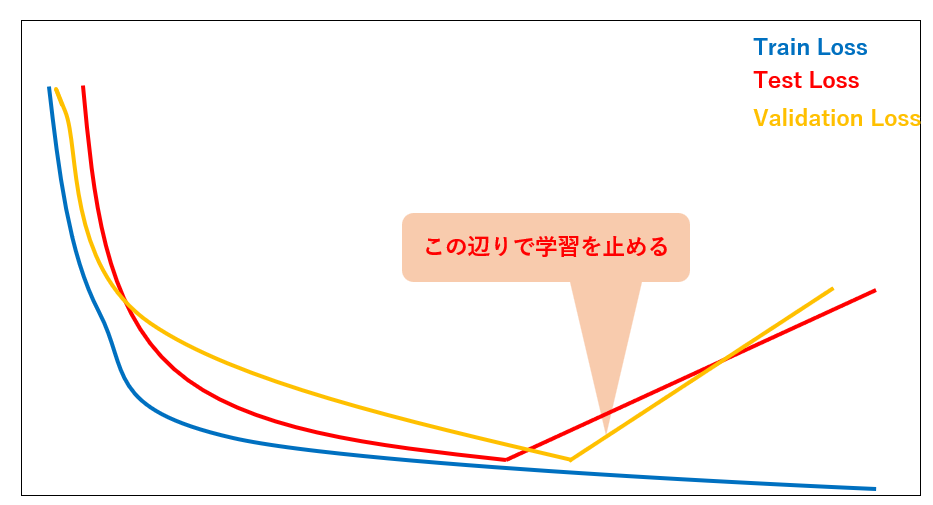
これを防ぐために登場するのがValidationDataです.学習データのうち,何%かをValidationDataとして,学習には使わず,疑似テストデータとして使用します.
学習を進めていく中で,都度ValidationDataをモデルに適用します.初めの方はValidationDataについてもLossが下がっていく(=精度が上がっていく)と思います.しかし,どこかでLossが上がる(精度が下がる)タイミングがあります.そこで学習を止めることで過学習を防げるのです👍
テストデータ見てやればいいじゃん.っていう人もいるかもしれませんが,それは良くありません![]()
テストデータはあくまでテストに使うものであり,学習時に参照することはしてはいけません.
4 交差検証
交差検証はモデル構造の精度を”評価”するための手法です.
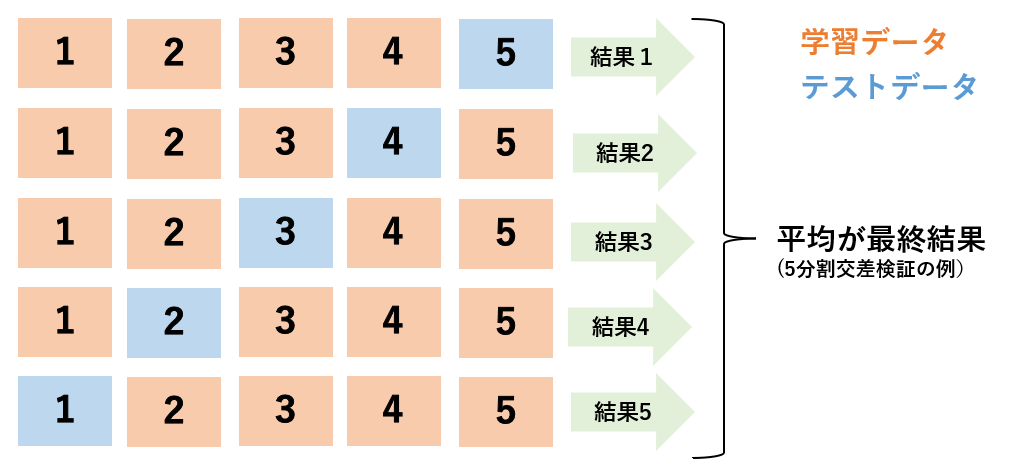
下記の順で処理を行います.
- データをk個に分割
- うち1つをテストデータ,のこりk-1個を学習データとする
- これをすべてのサブセットがテストデータになるように交換して繰り返す
- 全ての結果を平均を取る
データセットの分け方によってたまたま良い精度が出たり,悪い精度が出たりすることがあります.モデルの良し悪しを図るには,そういった運要素はない方がいいので,学習データを様々な組み合わせにすることで,精度を均す手法です.
また,Testは固定で,TrainとValidationを交差検証する手法もあります.その中でもっとも精度が良かったモデルを採用します.これは”評価”ではないですけどね.
5 アンサンブル学習
アンサンブル学習はKaggele等でよく使われる手法です.複数のモデルを作成し,それらの出力で多数決を取って,最終的な予測値とします.
この処理は今まで説明したものと比べて必須ではありませんが,精度を上げる手法として非常に有用です.
アンサンブル学習には,バギング・ブースティング・スタッキングがあります.
バギングとは,母集団から重複を許してランダムにデータを抽出.それらのサブセットで学習をし,複数のモデルでテストデータをモデルに通して,出力の多数決を取る手法です.

ブースティングとは,まず学習データで上手く分類できなかったものに対して重み付けを行い,再度学習させます.学習のLossが閾値を下回れば終了し,すべてのモデルを使用して,多数決を取る手法です.
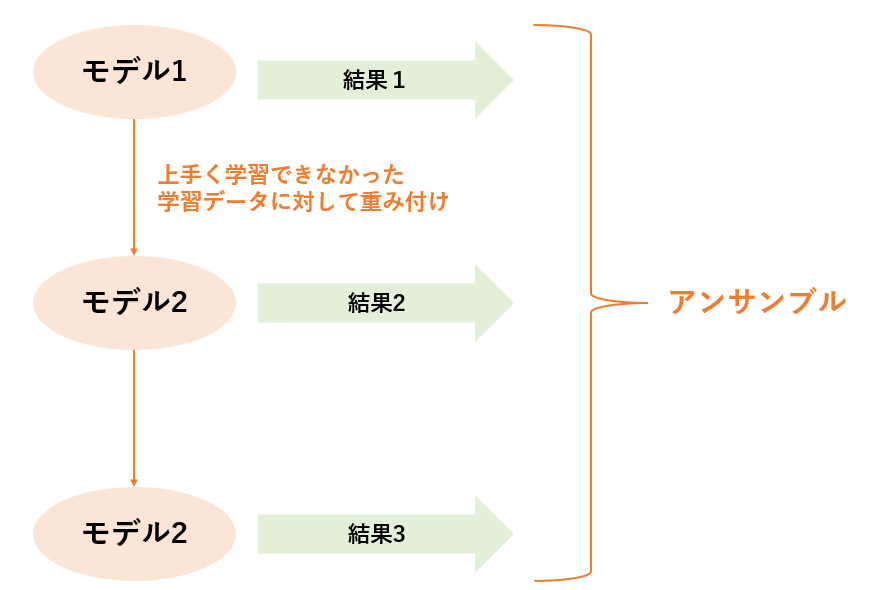
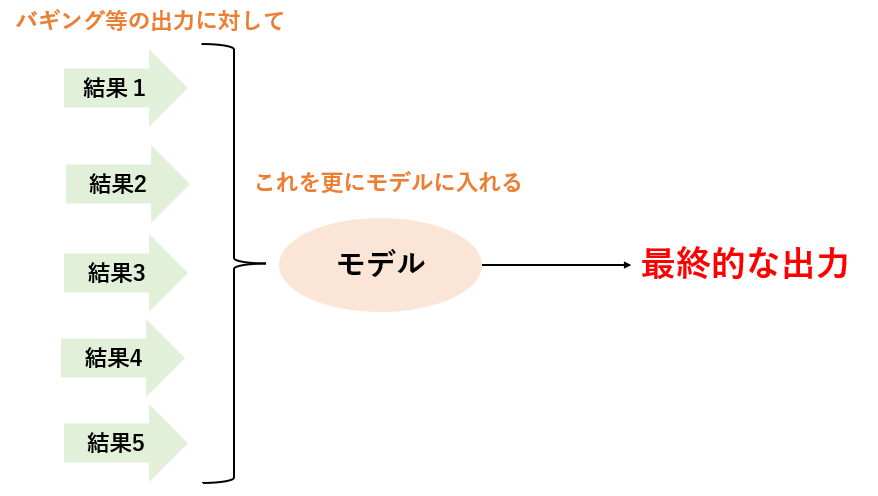
スタッキングとは,バギングのような複数のモデルの出力を特徴量と捉え,その特徴量を入力として,最終的な予測を出力するモデルを作成する手法です.
6 事前学習
事前学習とは,先にほかのデータで学習したモデルを使う手法です.ある程度知識を持ったモデルをつくっておくことで,自分のタスクにも流用できるということです.
しかし,あまりに違うデータを使うとむしろ邪魔になる場合もあるので注意です.
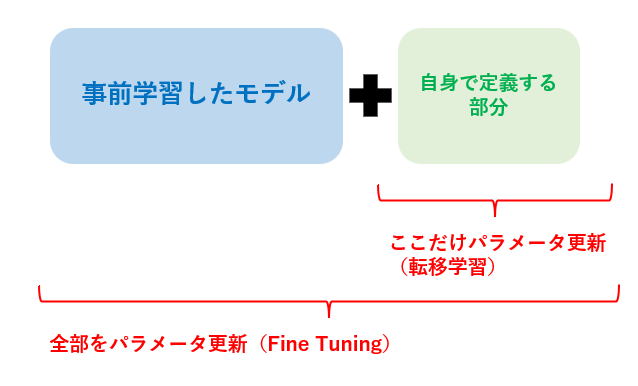
事前学習には,転移学習とファインチューニングがあります.
事前学習モデルを使う際には,自身のタスクに合わせてモデルを付け足します.
事前学習した部分は全く触らず,新しく定義した部分だけ自分のデータで学習を進めるのが転移学習です.
事前学習した部分も含めて(全てでなくても良い,事前学習したモデルの後半だけ更新可能にする等)パラメータを更新しながら自分のデータで学習を進めるのが,ファインチューニングです.
7 Data Augmentation
DataAugmentationは,データ数が少ないことや,データ不均衡へ対応するための処理です.
画像に対して行う処理について説明します.(他形式についてのDAは自分わからないんで…)
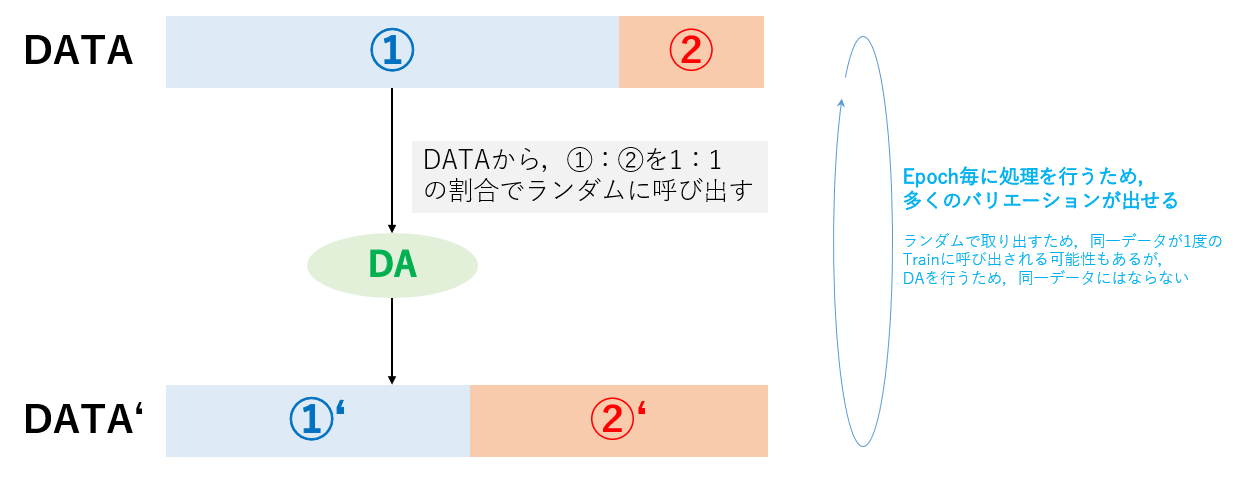
画像に対して,回転・拡張・反転・階調変換などの処理をランダムで行うことによって,データのバリエーションを増やします.
Pytorchでは,Transformeを使うことで,簡単に作成できます.
例を示します.
ImageTransformeが色についてのDA.ShareTransformが移動等のDAです.
もっと種類はありますが,タスクによっては反転してはいけなかったりするので,どういったDAの処理を行うかは事前に考えておかないといけません.
image_transform = transforms.RandomOrder([
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),
transforms.RandomPosterize(bits=4),
])
share_transform = transforms.RandomOrder([
transforms.RandomErasing(),
#transforms.RandomHorizontalFlip(),
transforms.RandomResizedCrop(IMG_SIZE, scale=(0.8, 1.2)),
transforms.RandomAffine(degrees=[-10, 10],translate=(0.2, 0.2)),
])
また,データ不均衡の為にもDAは使用できます.
下図のように,読み込む際に比率を設定しておくことで,データの不均衡を設定することができます.
8 Pytorchでの実装
DeepLearningコード(Pytorch)にて,Pytorchでの実装をまとめてあります.
また,より実践的なものとしてKaggeleでのタスクをまとめてありますので,確認してみてください.
さいごに
追記予定です.CNN編,RNN編,Transformer編も書きます.![]()