要件
- AWSでインフラ構築し運用しているプリケーションのデータを定期的にBigQueryに転送して、BigQuery上でデータ分析をやりたいというニーズがあり、RDSに保存しているデータを転送する機構を構築した。
- AWSを利用してるなら、その中でデータ分析もやったらいいじゃないかという意見もあると思うが、ビッグデータの蓄積や解析はBigQueryで実施した方がやりやすいということもあるようで、BigQueryへ転送するニーズが最近は結構ある模様。
- 今回はGCPが提供しているBigQeryへのデータ転送サービスDataTransferServiceを使って行う
構成図
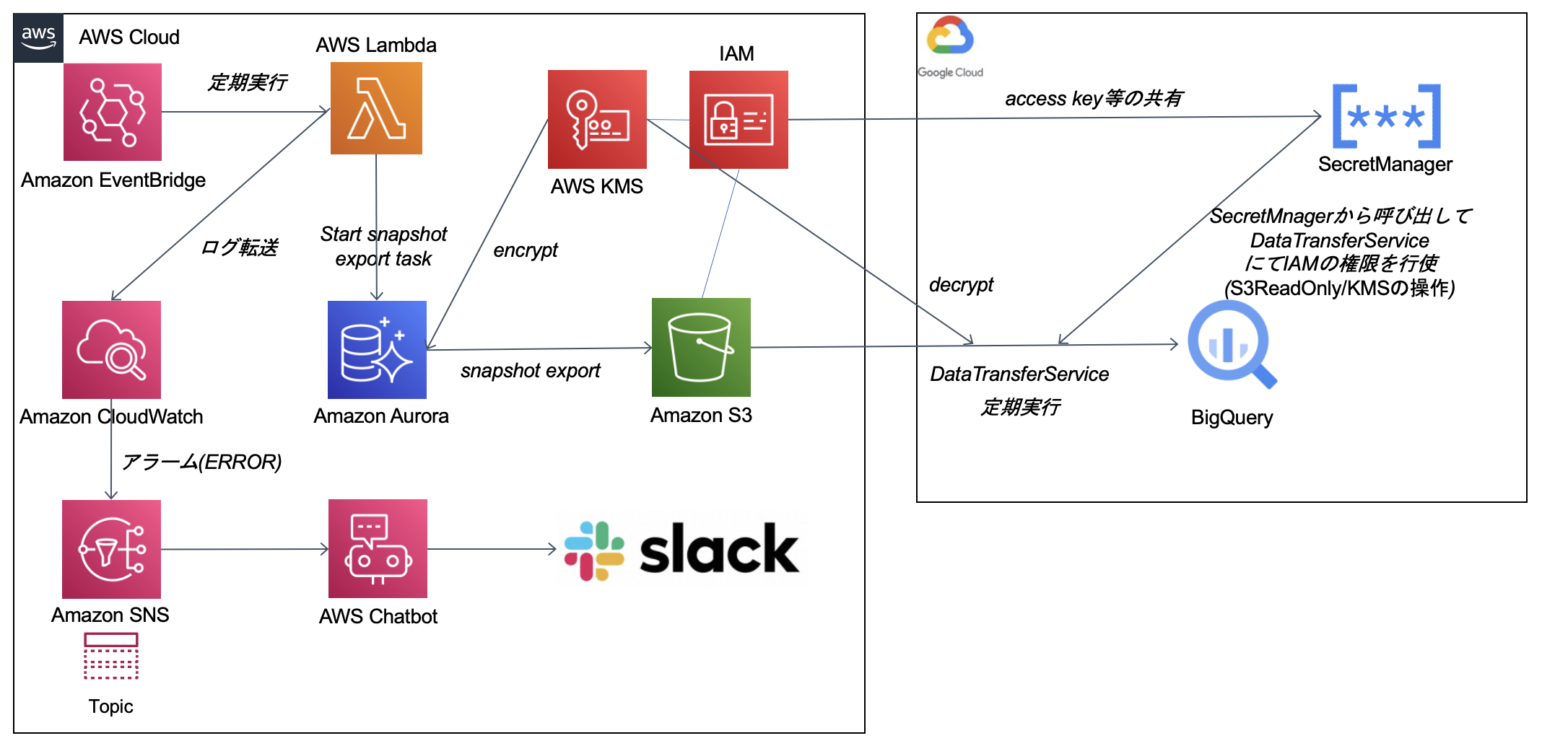
作成するアプリケーション概要
- RDSのデータを定期的にBigQueryへ転送することを実現するアプリケーション
- RDSの自動で取っているスナップショットデータをS3へ一日一回エクスポート(JST 0:00に実行)
- BigQuery側でDataTransferServiceを使いS3データをBigQueryへ一日一回取り込み(JST 2:00に実行)
- BigQueryでデータ分析
Lambda含めた関連リソースの構築はServerless Application Model(SAM)を使う
- Serverless Application Model(SAM)とはこちらを参考
https://docs.aws.amazon.com/ja_jp/serverless-application-model/latest/developerguide/what-is-sam.html - SAM CLIでデプロイするサーバーレスアプリケーションの形態を取る
- Lambda関数、IAM、KMS、S3バケット、定期実行の設定(UTC 15:00の設定)、エラーアラートの設定などを全て
template.yamlファイルにて定義/管理する - アプリケーションコードを更新するのと同じデプロイメントプロセスを通じて、AWSリソースを追加するためにテンプレートを更新することが可能。(基本はインフラ構築は全てコード管理)
まずはマネジメントコンソールで構築の手順を手動で試してみてうまくいくか確認
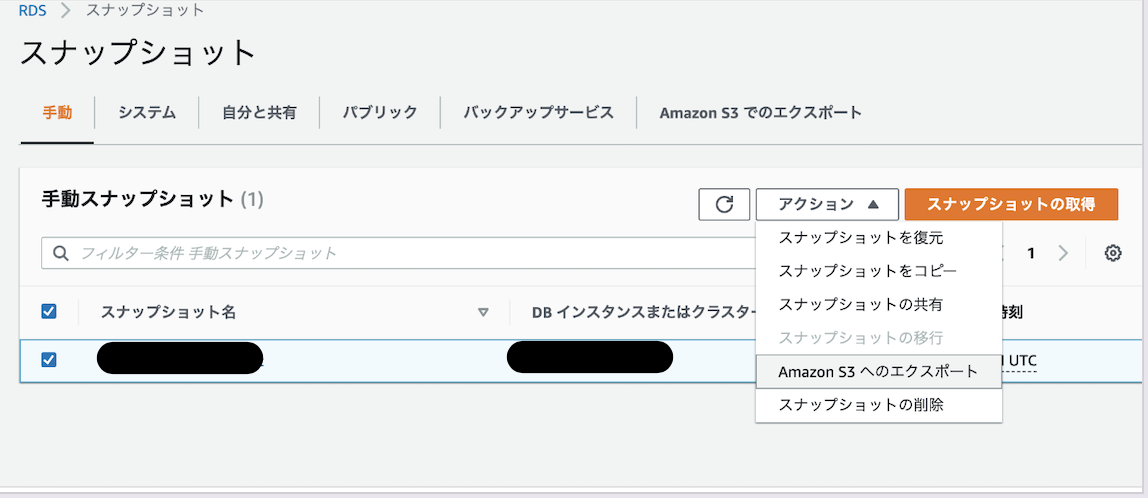
- RDSのインスタンスのスナップショット作成
- エクスポート先のS3バケットを生成
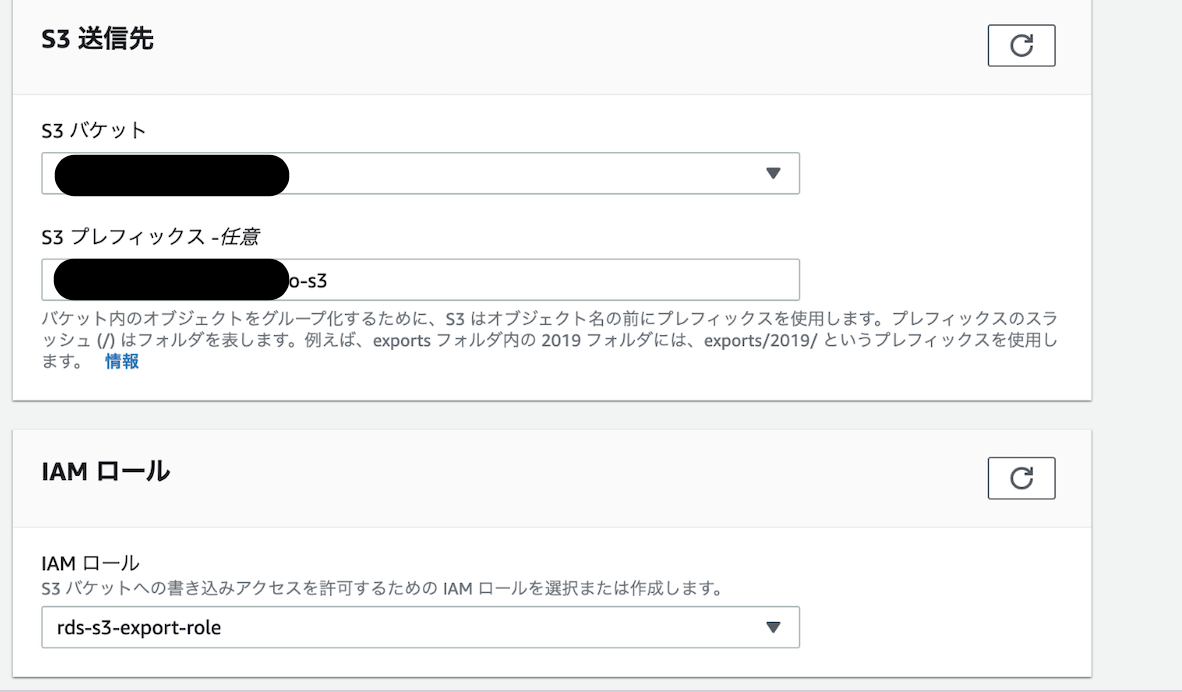
- スナップショットのデータをS3へのエクスポートするためのIAMロールの作成
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/USER_ExportSnapshot.html#USER_ExportSnapshot.Setup
$ aws iam create-policy --policy-name DdExportPolicy --policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DdExportPolicy",
"Effect": "Allow",
"Action": [
"s3:PutObject*",
"s3:ListBucket",
"s3:GetObject*",
"s3:DeleteObject*",
"s3:GetBucketLocation"
],
"Resource": [
"arn:aws:s3:::<バケット名>",
"arn:aws:s3:::<バケット名>/*"
]
}
]
}'
実行結果↓
{
"Policy": {
"PolicyName": "DdExportPolicy",
"PolicyId": "hogehoge",
"Arn": "arn:aws:iam::1111111111:policy/DdExportPolicy",
"Path": "/",
"DefaultVersionId": "v1",
"AttachmentCount": 0,
"PermissionsBoundaryUsageCount": 0,
"IsAttachable": true,
"CreateDate": "2022-05-27T06:40:26+00:00",
"UpdateDate": "2022-05-27T06:40:26+00:00"
}
}
ポリシーを作成したら、ポリシーの ARN を書き留めます。ポリシーを IAM ロールにアタッチする場合、後続のステップで ARN が必要です。
$ aws iam create-role --role-name rds-s3-export-role --assume-role-policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "export.rds.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}'
↓実行結果
{
"Role": {
"Path": "/",
"RoleName": "rds-s3-export-role",
"RoleId": "hugahuga",
"Arn": "arn:aws:iam::1111111111:role/rds-s3-export-role",
"CreateDate": "2022-05-27T06:41:26+00:00",
"AssumeRolePolicyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "export.rds.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
}
}
$ aws iam attach-role-policy --policy-arn your-policy-arn --role-name rds-s3-export-role
-
データの暗号化のためにkmsでキーを作成
-
コンソールで作成する方法(構築時はCFnで自動作成)
-
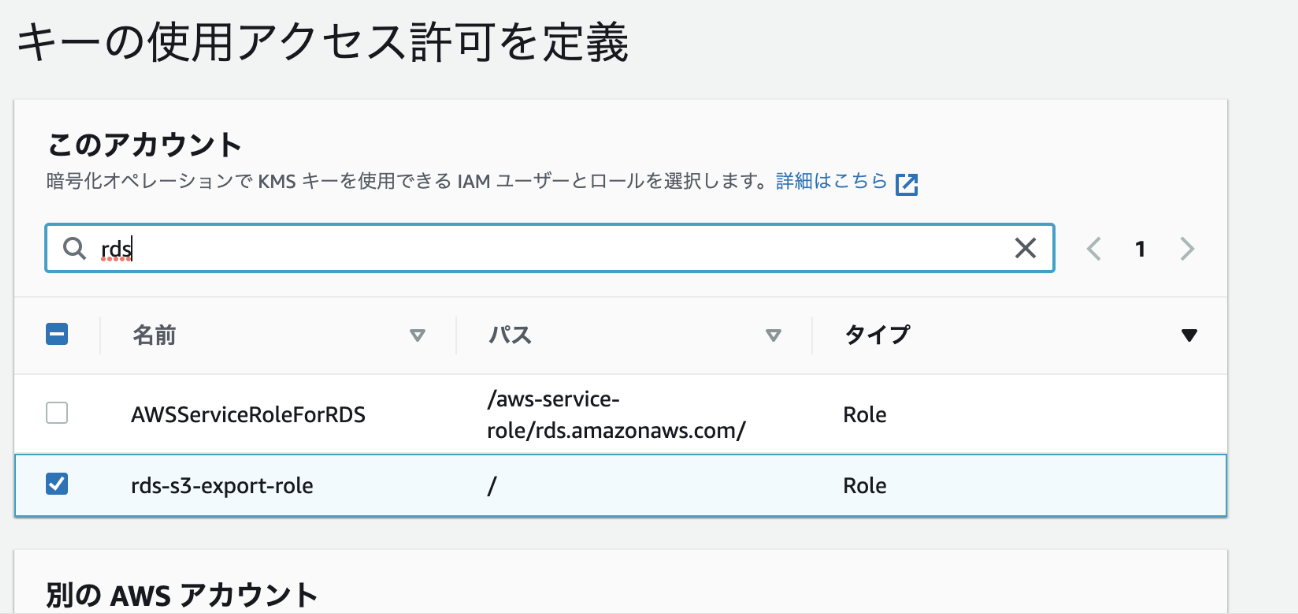
キーの管理アクセス許可は特に定義しない
-
キーの使用アクセス許可だけ設定する
-
-
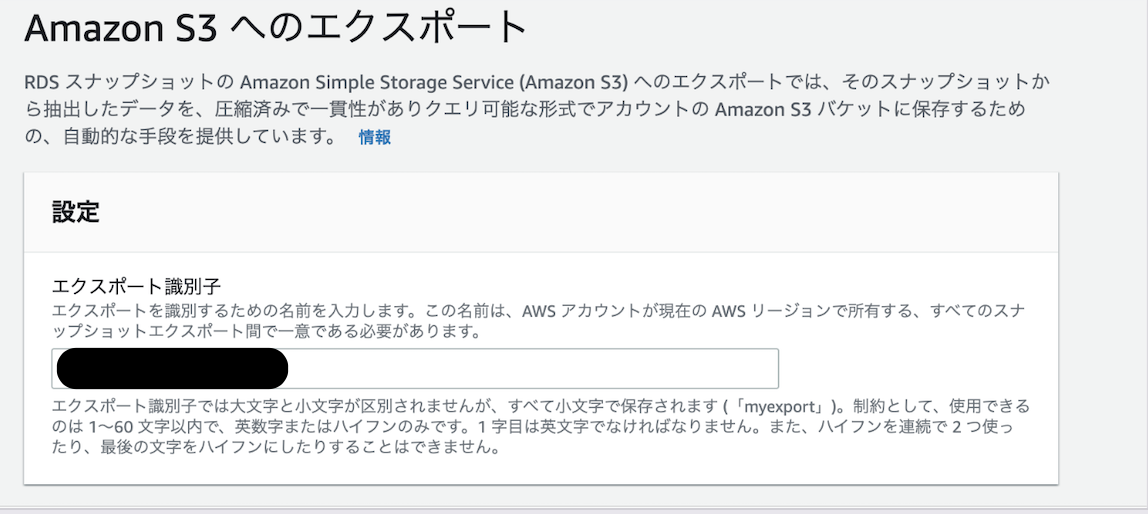
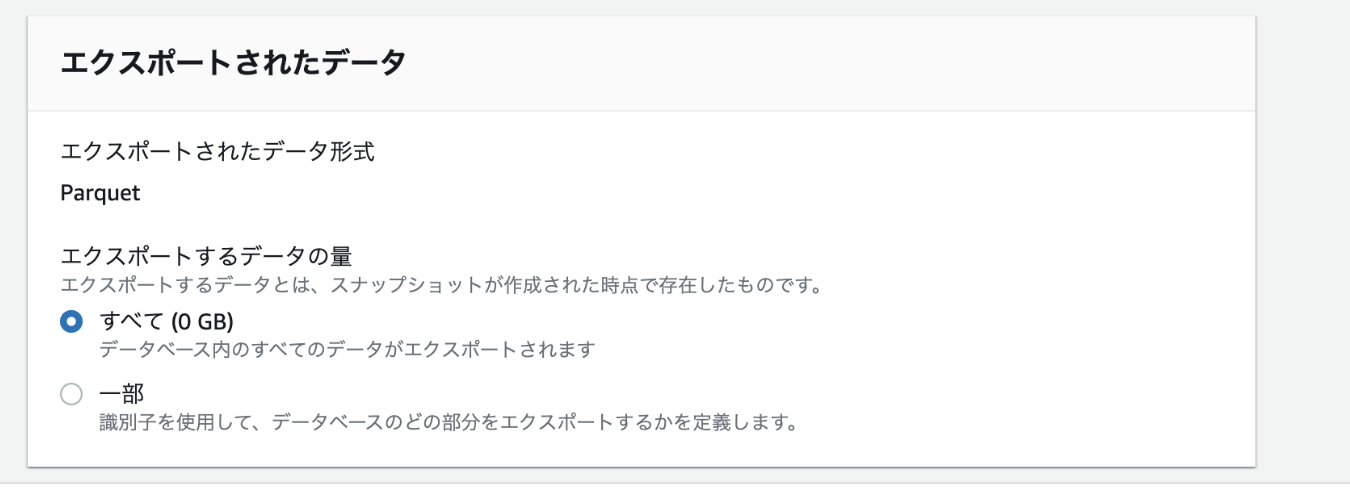
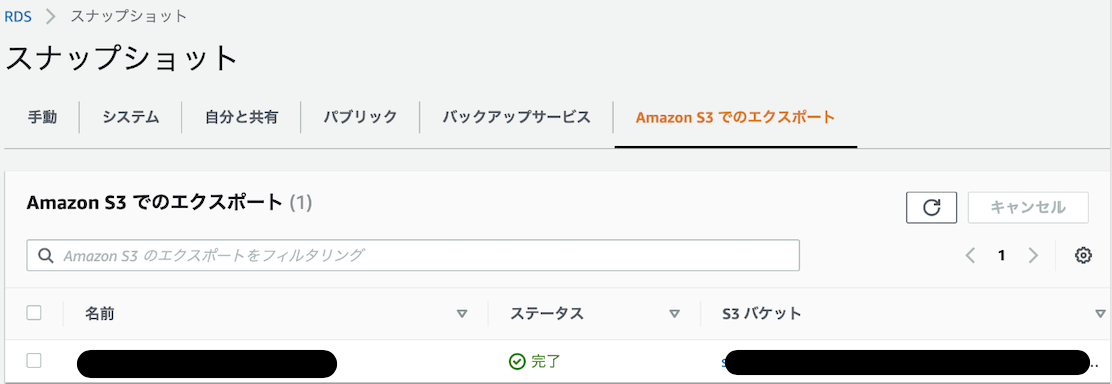
スナップショットをS3へPARQUET形式で転送

-
BigQuery側から取り込み
- BigQueryDataTransferServiceを使う
- GCPの権限、設定まわり
- BigQueryDataTransferService設定ユーザーへの権限設定
(bigquery.transfers.update、bigquery.transfers.get)
- BigQueryDataTransferService設定ユーザーへの権限設定
-
GCPからS3へのアクセス用のIAMの作成
- プログラムによるアクセスが可能なIAMユーザーの作成はコンソールから手動で行う
- 権限(policy)は以下
AmazonS3ReadOnlyAccess- kms:Decryptできるインラインポリシー
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowUseOfTheKey",
"Effect": "Allow",
"Action": "kms:Decrypt",
"Resource": "${kmsのarn}"
}
]
}
- GCP上でAPIの有効化
- この辺りの処理もコマンドラインツールで実施できるがとりあえずの手動対応

-
BigQuery Transfer Serviceの設定
- 先に転送先のデータセットとテーブルを作成しておく
-
- 先に転送先のデータセットとテーブルを作成しておく
-
GCPのBigqQueryのコンソールからDataTransferServiceの設定を作成する場合
- 参考: https://dev.classmethod.jp/articles/transfer-s3-to-bigquery-using-data-transfer-service/
- 転送を作成
- ソースタイプで「Amazon S3」を選択
- 転送設定に任意の名前をつける
- 事前に作成したIAMのアクセスキー等を登録して権限を付与
- 転送スケジュールを設定する
- 転送先BigQueryのデータセット名を選択する
- 転送先BigQueryのテーブル名と、転送元データソースの情報を入力する
- BigQueryデータ格納時のオプション設定をおこなう
- 必要に応じてメール通知機能を設定する
- 作成すると転送が開始されて結果が表示


手動でRDSからBigQueryへ転送できることが確認できたので、ここから先はインフラ構築を自動化しつつ、必要な構成を作成していく過程を記載する
実際のインフラ構築
事前準備
GCPのDataTransferServiceからAWSにアクセスするためのIAMユーザーを準備
- GCPからS3へのアクセス用のIAMユーザーの作成
- 権限(policy)は以下
AmazonS3ReadOnlyAccess-
kms:Decryptをポリシーで追加
GCP側の設定
- BigQueryでRDSデータを格納するためのデータセット、テーブル等の作成(コンソール上で先ほど作成している)
- 関連APIの有効化
- GCP cloud shellにログインして下記を実行して関連APIを有効化
$ gcloud services enable --project [PROJECT_ID] bigquerydatatransfer.googleapis.com
$ gcloud services enable --project [PROJECT_ID] bigquery.googleapis.com
$ gcloud services enable --project [PROJECT_ID] secretmanager.googleapis.com # AWSアクセスキーを管理するために必要
- AWSアクセスキーをGCP secret managerに登録
$ gcloud secrets create access_key_id
$ gcloud secrets create secret_access_key
$ printf "<access_key_idをコピペ>" | gcloud secrets versions add access_key_id --data-file=-
$ printf "<secret_access_keyをコピペ>" | gcloud secrets versions add secret_access_key --data-file=-
LambdaをServerless Application Model(SAM)で作成
-
Serverless Application Model(SAM)とはこちらを参考
https://docs.aws.amazon.com/ja_jp/serverless-application-model/latest/developerguide/what-is-sam.html -
Serverless Application Model Command Line Interface (SAM CLI) は、AWS CLI の拡張機能で、Lambda アプリケーションを構築・テストするための機能を追加したもの。
-
Dockerを使用して、LambdaにマッチしたAmazon Linux環境で機能を実行。
参考:
- SAM CLI - Install the SAM CLI
- https://devblog.thebase.in/entry/sam-hands-on
- Docker - Install Docker community edition
- Python 3 installed
- ローカルにSAM CLIをインストール
https://docs.aws.amazon.com/ja_jp/serverless-application-model/latest/developerguide/serverless-sam-cli-install-mac.html
$ brew tap aws/tap
$ brew install aws-sam-cli
$ sam --version
- sam initはSAMを作成するための最初の準備ファイルを生成するコマンド
- 初期構築コマンドをリポジトリ内で実行する
- 対話型で選ぶ選択肢は以下の通り
- LambdaはZIPファイルではなくimageでデプロイ
$ sam init
You can preselect a particular runtime or package type when using the `sam init` experience.
Call `sam init --help` to learn more.
Which template source would you like to use?
1 - AWS Quick Start Templates
2 - Custom Template Location
Choice: 1
Choose an AWS Quick Start application template
1 - Hello World Example
2 - Multi-step workflow
3 - Serverless API
4 - Scheduled task
5 - Standalone function
6 - Data processing
7 - Infrastructure event management
8 - Machine Learning
Template: 1
Use the most popular runtime and package type? (Python and zip) [y/N]: N
Which runtime would you like to use?
1 - dotnet5.0
2 - dotnetcore3.1
3 - go1.x
4 - java11
5 - java8.al2
6 - java8
7 - nodejs14.x
8 - nodejs12.x
9 - python3.9
10 - python3.8
11 - python3.7
12 - python3.6
13 - ruby2.7
Runtime: 9
What package type would you like to use?
1 - Zip
2 - Image
Package type: 2
Based on your selections, the only dependency manager available is pip.
We will proceed copying the template using pip.
Project name [sam-app]:
Cloning from https://github.com/aws/aws-sam-cli-app-templates (process may take a moment)
-----------------------
Generating application:
-----------------------
Name: sam-app
Base Image: amazon/python3.9-base
Architectures: x86_64
Dependency Manager: pip
Output Directory: .
Next steps can be found in the README file at ./sam-app/README.md
Commands you can use next
=========================
[*] Create pipeline: cd sam-app && sam pipeline init --bootstrap
[*] Test Function in the Cloud: sam sync --stack-name {stack-name} --watch
Lambdaの実装
- 自動で定期生成しているRDSのスナップショットをS3にエクスポートする定期処理をLambdaでpythonにて実装
import boto3
import os
import datetime
rds = boto3.client('rds')
s3 = boto3.resource('s3')
client = boto3.client('kms')
def lambda_handler(event, context):
export_task_prefix = f"export-id-{os.environ['ENV']}-"
db_cluster_identifier = os.environ['DB_CLUSTER_IDENTIFIER'] # エクスポート対象のDBクラスターの識別子を環境変数で呼び出し
export_snapshot(export_task_prefix, db_cluster_identifier)
def export_snapshot(export_task_prefix, db_cluster_identifier):
snapshots = rds.describe_db_cluster_snapshots(
DBClusterIdentifier=db_cluster_identifier)['DBClusterSnapshots'] # 該当のクラスターで自動で取っているスナップショットのデータを全て取得
snapshots = sorted(
snapshots, key=lambda x: x['SnapshotCreateTime'], reverse=True) # 自動で取っているスナップショットのデータをcreated_atで並べ替えて一番最新を常に取得
snapshot = snapshots[0]
new_export_task_id = export_task_prefix + \
f"{datetime.date.today()}".replace('-', '') # GCPのDataTransferServiceで設定する転送元のtask_idの設定と合わせる
response = rds.start_export_task(
ExportTaskIdentifier=new_export_task_id,
SourceArn=snapshot['DBClusterSnapshotArn'],
S3BucketName=os.environ['S3_EXPORT_BUCKET_NAME'],
IamRoleArn=os.environ['S3_EXPORT_IAM_ROLE_ARN'],
KmsKeyId=os.environ['KMS_KEY_ID']
) # スナップショットをS3へエクスポート
return(response)
Docker
- Lambdaの実行環境をDockerで用意する
- 本番にもこのimageをそのまま利用する
FROM public.ecr.aws/lambda/python:3.9
COPY app.py requirements.txt ./
# Command can be overwritten by providing a different command in the template directly.
CMD ["app.lambda_handler"]
AWS CloudFormation(参考コード)
- samのデプロイコマンド打った際に実行するCloudFormationを作成していく
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: >
python3.9
SAM Template for RdsSnapshotToS3ExportLambdaApp
Globals:
Function:
Timeout: 3
Parameters:
ENV:
Type: String
Default: stg
PREFIX:
Description: Service Name.
Type: String
Resources:
RdsSnapshotToS3ExportKey:
Type: 'AWS::KMS::Key'
Properties:
Description: Export to S3 from RDS snapshot
EnableKeyRotation: true
PendingWindowInDays: 20
KeyPolicy:
Version: 2012-10-17
Id: key-policy
Statement:
- Sid: Enable IAM User Permissions
Effect: Allow
Principal:
AWS: !Sub "arn:aws:iam::${AWS::AccountId}:root"
Action: 'kms:*'
Resource: '*'
- Sid: Allow use of the key
Effect: Allow
Principal:
AWS:
- !GetAtt RdsSnapshotExportToS3FunctionExecutionRole.Arn
Action:
- "kms:Encrypt"
- "kms:Decrypt"
- "kms:ReEncrypt*"
- "kms:GenerateDataKey*"
- "kms:DescribeKey"
Resource: '*'
- Sid: Allow attachment of persistent resources
Effect: Allow
Principal:
AWS:
- !GetAtt RdsSnapshotExportToS3FunctionExecutionRole.Arn
Action:
- "kms:CreateGrant"
- "kms:ListGrants"
- "kms:RevokeGrant"
Resource: '*'
Condition:
Bool:
kms:GrantIsForAWSResource: true
KmsAliasName:
Type: 'AWS::KMS::Alias'
Properties:
AliasName: !Sub "alias/${ENV}-RdsSnapshotToS3Export"
TargetKeyId: !Ref RdsSnapshotToS3ExportKey
LimitedBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub "${PREFIX}-${ENV}-bucket-name"
BucketEncryption:
ServerSideEncryptionConfiguration:
- ServerSideEncryptionByDefault:
SSEAlgorithm: AES256
AccessControl: Private
PublicAccessBlockConfiguration:
BlockPublicAcls: True
BlockPublicPolicy: True
IgnorePublicAcls: True
RestrictPublicBuckets: True
RdsSnapshotExportToS3FunctionExecutionRole:
Type: AWS::IAM::Role
Properties:
RoleName: !Sub "${ENV}-RdsSnapshotExportToS3FunctionExecutionRole"
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service:
- lambda.amazonaws.com
- export.rds.amazonaws.com
Action: sts:AssumeRole
Policies:
- PolicyName: !Sub "${ENV}-RdsSnapshotExportToS3FunctionExecutionPolicy"
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- logs:CreateLogGroup
- logs:CreateLogStream
- logs:PutLogEvents
Resource:
- 'Fn::Join':
- ':'
-
- 'arn:aws:logs'
- Ref: 'AWS::Region'
- Ref: 'AWS::AccountId'
- 'log-group:/aws/lambda/*:*:*'
- Effect: "Allow"
Action:
- iam:PassRole
- rds:StartExportTask
- rds:DescribeDBClusterSnapshots
- rds:CreateDBClusterSnapshot
Resource: "*"
- Effect: Allow
Action:
- s3:PutObject*
- s3:ListBucket
- s3:GetObject*
- s3:DeleteObject*
- s3:GetBucketLocation
Resource:
- !GetAtt LimitedBucket.Arn
- !Join [ "", [ !GetAtt LimitedBucket.Arn, "/*" ] ]
RdsSnapshotExportToS3Function:
Type: AWS::Serverless::Function
Properties:
FunctionName: !Sub "${ENV}-RDS-snapshot-export-to-S3-app"
PackageType: Image
Architectures:
- x86_64
Timeout: 900
Role: !GetAtt RdsSnapshotExportToS3FunctionExecutionRole.Arn
Environment:
Variables:
S3_EXPORT_BUCKET_NAME: !Sub "${PREFIX}-${ENV}-bucket-name"
DB_CLUSTER_IDENTIFIER: !Sub "${PREFIX}-${ENV}-cluster"
KMS_KEY_ID: !GetAtt RdsSnapshotToS3ExportKey.KeyId
S3_EXPORT_IAM_ROLE_ARN: !GetAtt RdsSnapshotExportToS3FunctionExecutionRole.Arn
ENV: !Sub "${ENV}"
Metadata:
Dockerfile: Dockerfile
DockerContext: .
DockerTag: python3.9-v1
RdsSnapshotExportToS3FunctionLogGroup:
Type: AWS::Logs::LogGroup
Properties:
LogGroupName: !Sub /aws/lambda/${RdsSnapshotExportToS3Function}
LambdaScheduleEvent:
Type: AWS::Events::Rule
Properties:
Description: ’schedule event for RdsSnapshotExportToS3Function’
ScheduleExpression: 'cron(0 15 * * ? *)'
State: ENABLED
Targets:
- Arn: !GetAtt RdsSnapshotExportToS3Function.Arn
Id: ScheduleEvent1Target
LambdaInvokePermission:
Type: AWS::Lambda::Permission
Properties:
Action: lambda:InvokeFunction
FunctionName: !Ref RdsSnapshotExportToS3Function
Principal: events.amazonaws.com
SourceArn: !GetAtt LambdaScheduleEvent.Arn
ChatBotRole:
Type: AWS::IAM::Role
Properties:
RoleName: !Sub "${PREFIX}-${ENV}-ChatBotRole"
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service:
- chatbot.amazonaws.com
Action: sts:AssumeRole
ManagedPolicyArns:
- arn:aws:iam::aws:policy/AmazonSNSFullAccess
- arn:aws:iam::aws:policy/CloudWatchFullAccess
LambdaErrorAlertTopic:
Type: AWS::SNS::Topic
Properties:
TopicName: !Sub "${PREFIX}-${ENV}-LambdaErrorAlertTopic"
TopicPolicy:
Type: AWS::SNS::TopicPolicy
Properties:
PolicyDocument:
Statement:
- Effect: "Allow"
Principal:
Service:
- "events.amazonaws.com"
- "cloudwatch.amazonaws.com"
Action: "sns:Publish"
Resource: "*"
Topics:
- !Ref LambdaErrorAlertTopic
LambdaErrorMetricFilter:
Type: AWS::Logs::MetricFilter
Properties:
LogGroupName: !Ref RdsSnapshotExportToS3FunctionLogGroup
FilterPattern: "?ERROR ?CRITICAL"
MetricTransformations:
- MetricValue: "1"
DefaultValue: "0"
MetricName: !Sub /aws/lambda/${RdsSnapshotExportToS3Function}/error-Notification
MetricNamespace: !Sub /aws/lambda/${RdsSnapshotExportToS3Function}/error-Notification
LambdaErrorAlarm:
Type: AWS::CloudWatch::Alarm
Properties:
AlarmName: !Sub "${PREFIX}-${ENV}-LambdaErrorAlert"
AlarmActions:
- !Ref LambdaErrorAlertTopic
Namespace: !Sub /aws/lambda/${RdsSnapshotExportToS3Function}/error-Notification
MetricName: !Sub /aws/lambda/${RdsSnapshotExportToS3Function}/error-Notification
ComparisonOperator: GreaterThanOrEqualToThreshold
EvaluationPeriods: 1
Period: 60
Statistic: Sum
Threshold: 1
TreatMissingData: notBreaching
Outputs:
RdsSnapshotExportToS3Function:
Description: "Lambda Function ARN"
Value: !GetAtt RdsSnapshotExportToS3Function.Arn
アプリケーションを初めてビルドしてデプロイする時のコマンド
- sam buildコマンドでimageがビルドされる
- sam deploy --guidedコマンドを打つと
- buildしたimageを元にデプロイが始まる
- 対話型でcloud formationのテンプレにパラメータなどを渡せる
- その他必要な変数を入力していく
- buildされたimageをpushする
- cloudformationを実行して関連リソースを作成
- S3にはpushされたECRのimageの参照が記録されたtemplateファイルのみが格納される
- ZIP形式でのアップロードの時のようにLambdaのソースコードがS3にアップロードされることはない
sam build
sam deploy --guided
2回目以降のデプロイコマンド
- 1回目のデプロイ時に対話型で設定したパラメータは
samconfig.tomlファイルに記録される
$ bash deploy.sh <環境名(staging or production)>
- シェルスクリプトの内容は以下
#!/bin/bash
sam build
echo y | sam deploy --config-env $1
アラート用のチャットボットについて
- 今回は既に別のチャットボットに紐付け済みのslackチャンネルにアラートを流したかったので、CFnのテンプレからはリソースの作成は外してある。
- 手動で既存のチャットボットに新規で作ったトピックを紐づける処理をマネジメントコンソールから実施
BigQuery側のDataTransferServiceの設定
-
target_tables.txtにBigQueryに転送するRDSのTable名全てをリストで記載
-
シェルスクリプト上で呼び出しテーブルごとにループしてDataTransferServiceのリソースを作成していく
-
GCP cloud shellにログインして、リポジトリのソースコードをクローン
-
下記コマンドを実行してDBのテーブルの数だけTransferの設定を作成
- 既に存在しているテーブルの転送設定はスキップする
- テーブルの追加時もリストには全て記載して実行する
- transferの定期実行する時間帯は一律2:00(UTC 17:00)に設定
- データは日々全テータを最新版に常に上書きする設定(https://googleapis.dev/python/bigquery/latest/generated/google.cloud.bigquery.job.WriteDisposition.html)
-
bqコマンド参考
$ bash deploy_bigquery.sh <database_name> <app_name> <env(stg or prod)> <prefix>
#!/bin/bash
database_name="$1"
app_name="$2"
env="$3"
prefix="$4"
access_key_id=`gcloud secrets versions access 1 --secret="access_key_id"`
secret_access_key=`gcloud secrets versions access 1 --secret="secret_access_key"`
for target_table in `cat target_tables.txt`
do
bq ls --transfer_config --transfer_location=us | grep "${database_name}-${target_table}-transfer"
if [ $? = 0 ]; then # 既に同一データベースの同一テーブルの転送設定があれば設定の作成をスキップする
echo "${database_name}-${target_table}-transferの設定は既に存在するためスキップします"
continue
fi
bq mk --transfer_config --data_source=amazon_s3 \
--display_name=${database_name}-${target_table}-transfer \
--target_dataset=${app_name}_${env}_rds_data \
--schedule='every day 03:00' \
--params='{
"destination_table_name_template":"'${target_table}'",
"data_path":"s3://'${prefix}'-'${env}'-cluster-snapshot-limited-access/export-id-'${env}'-{run_time|\"%Y%m%d\"}/'${database_name}'/'${database_name}'.'${target_table}'/1/*.parquet",
"access_key_id":"'${access_key_id}'",
"secret_access_key":"'${secret_access_key}'",
"file_format":"PARQUET",
"write_disposition": "WRITE_TRUNCATE"
}'
if [ $? = 1 ]; then # transfer作成に失敗した場合
echo "${database_name}-${target_table}-transferの作成に失敗しました"
continue
fi
echo "${database_name}-${target_table}-transferの作成に成功しました"
done
- 実行スケジュールを更新したい場合
時間のところをUTC時間で設定すると+9時間したJST時間で実行される
bq update --transfer_config --schedule='every day 17:00' <transfer-id>
これでDataTransferServiceの設定が作成され、定期的なデータ取り込みが行われる。
※注意点:
- S3に保存されるスナップショットデータのpathについては変更されることもあるので、base_prefix部分以降はワイルドカードで飲み込めるようにしておいた方が良いのだが、以下の方法でワイルカード指定しても取得できなかったため、明示的にディレクトリを指定する形に已む無くしている。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/aurora-export-snapshot.html#aurora-export-snapshot.FileNames
特定のテーブルのエクスポートされたデータは、base_prefix/files の形式で保存されます。そのベースプレフィックスは次のとおりです。
export_identifier/database_name/schema_name.table_name/
ファイルを名付ける方法には、次の 2 つの規則があります。現在の規則は次のとおりです。
partition_index/part-00000-random_uuid.format-based_extension
以前の規則は次のとおりです。
part-partition_index-random_uuid.format-based_extension
ファイルの命名規則は変更されることがあります。したがって、ターゲットテーブルを読み込むときは、テーブルのベースプレフィックス内のすべてを読み込むことをお勧めします。
- GCPのワイルドカードの使い方
https://cloud.google.com/bigquery/docs/s3-transfer-intro?hl=ja
まとめ
いかがでしょうか?地味に全部設定すると結構大変でした。設定以後は自動で回るので基本的には大丈夫なはずです。
DataTransferServiceにpub/subを設定して、Transferに失敗した時にスラックへ通知する処理が抜けていますが、これから対応していくので、対応したら追記します。
よろしくお願いいたします。