はじめに
人工知能を学んでいる大学院生です.Qiitaへの投稿もWebアプリの開発もほぼ初心者ですが,痒いところに手が届くように解説していこうと思います!どうぞよろしくお願いします.
最終的に出来上がった自己満アプリはこちら('ω').
動作環境
本記事における動作環境です.
- Windows 10 Pro
- python 3.6.1
- chainer 3.5.0
- cupy 2.5.0
※ 詳しい動作環境は,githubでご覧ください.
- Conditional DCGAN:https://github.com/Dai7Igarashi/conditionalDCGAN
- WebApp:https://github.com/Dai7Igarashi/cDCGAN-WebApp
概要
第1回目となる今回は「Conditional DCGANの解説」をしていきたいと思います.
Webアプリの作り方は(その2)に回します.
Conditional GAN("DC"ではない)の考え方自体は2014年に登場しているので今さら感がありますが,学習していないラベルに対してどのような出力が得られるのか,気になったので実験しました.
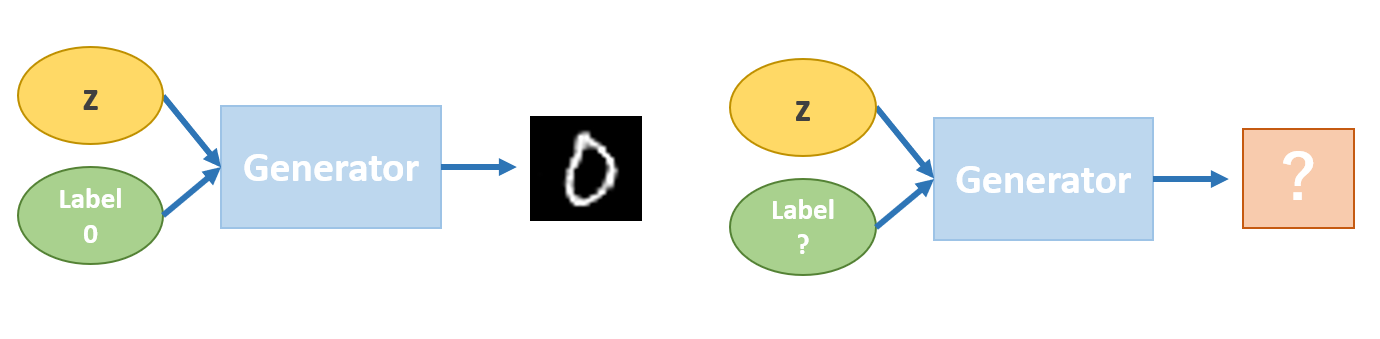
Conditional GANの論文
Conditional Generative Adversarial Nets
GANs
さきほど**"DCではない"**という記述をしましたが,GANとは「Generative Adversarial Network」の略で,日本語では敵対的生成ネットワークなどと呼ばれます.これに対してDCGANとは「Deep Convolutional Generative Adversarial Network」の略です.Convolutionと聞いてピンときた方もいると思いますが,GANでは全結合層だった部分を畳み込み層に変更したものがDCGANです.GANおよび派生手法をまとめてGANsと呼ぶことにします.
GANsに関してはこちらの記事が大変わかりやすいです.
今さら聞けないGAN(1) (シリーズもの)
https://qiita.com/triwave33/items/1890ccc71fab6cbca87e
GANsについての日本語記事は多数あるので,ここでは
- 基本的なGANの仕組み
- Conditional DCGANの構造
をざっくりと説明したいと思います.
基本的なGANの仕組み
GANは生成モデルと呼ばれます.生成というからには何かを生み出す訳ですが,一体何を入力して何が生成されるのでしょうか...
GANやDCGANなど,一般的にはノイズz(乱数)から"本物"データっぽい"偽物"データを生成します.
(pix2pixみたいにノイズではなく画像を入れてやるのもあるみたい)
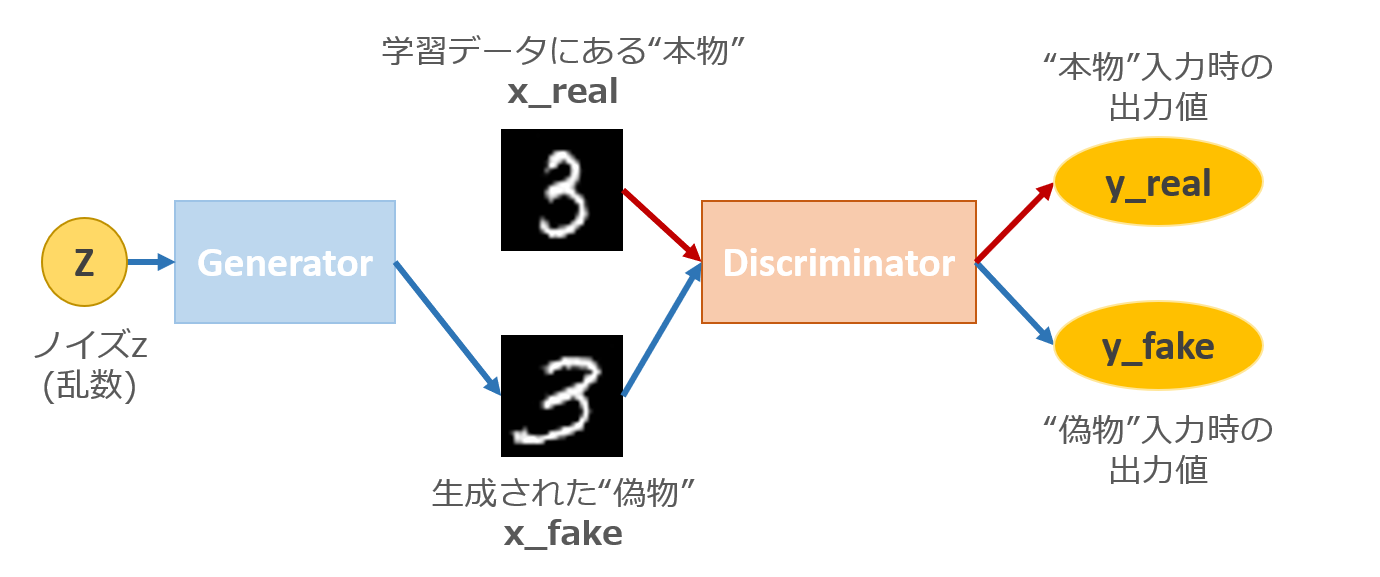
上図で言えば,学習データにある本物データに似た偽物データを生成するように**Generator(生成器)とDiscriminator(識別器)**を学習させます."似せる"にあたり,本物と偽物の差を縮めるわけですが,GANの論文では以下のように誤差関数を設定しています.
\min_{G}\max_{D}V(D,G) = \mathbb{E}_{x\sim p_{data}}(x)[\log D(x)] + \mathbb{E}_{z\sim p_z}(z)[\log (1-D(G(Z)))]
ざっくり説明すると,Discriminator側は本物に対して本物(出力1)を,偽物に対して偽物(出力0)を出力させたい.Generator側は,自身が生成した偽物をDiscriminatorに入力したときのDiscriminatorの出力を本物(出力1)にさせたいわけです.
上図で説明すると,Discriminator側は y_real → 1 ∧ y_fake → 0,Generator側は y_fake → 1になるように誤差を縮めれば良いわけです.
そうすると,Discriminator側としては上式の第1項で本物データxが入力されたときの値は大きく,第2項で偽物データが入力されたときの値も大きくなってDに関しては最大化できます.一方でGenerator側は第2項の値を小さくするのでGに関しては最小化できます.
プログラムでは以下のように記述しています.
# 学習ループ(167行目以降)
## Discriminatorの誤差関数
# 本物画像に対して本物(1)を出力させたい
# 本物を本物と判定するほどL1は小さくなる
L1 = F.sum(F.softplus(-y_real)) / b_size
# 偽物画像に対して偽物(0)を出力させたい
# 偽物を偽物と判定するほどL2は小さくなる
L2 = F.sum(F.softplus(y_fake)) / b_size
dis_loss = L1 + L2
## Generatorの誤差関数
# 偽物画像を入力した時のDiscriminatorの出力を本物(1)に近づける
# 偽物で本物と判定するほどlossは小さくなる
gen_loss = F.sum(F.softplus(-y_fake)) / b_size
chainerのドキュメントによると,softplus関数の定義は
f(x) = \frac{1}{\beta}\log (1+\exp(\beta x))
で,今回はデフォルト値 $\beta = 1.0$ なのでグラフは以下のようになります.
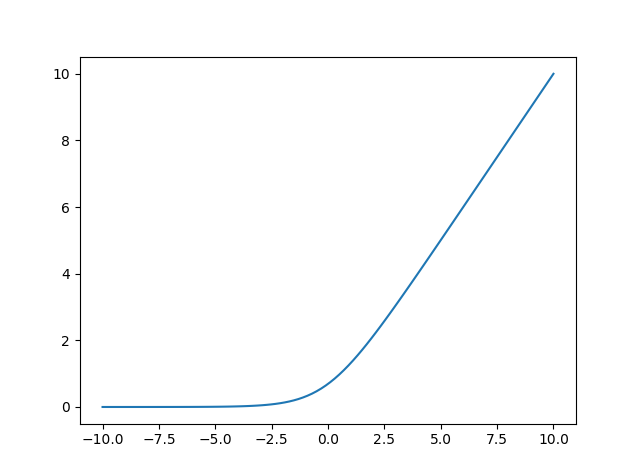
# coding: UTF-8
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-10,10,100)
y = np.log((1 + np.exp(x)))
plt.plot(x,y)
plt.show()
このグラフから,Generatorの誤差はy_fakeが1に近づくほど0に縮まります.一方のDiscriminatorは,y_realが正の大きな値をとるほどL1が小さく,y_fakeが0に近づくほどL2が小さくなり,全体の誤差L1+L2が縮まります.(気づいたんですがDiscriminatorの方はネットワークの最終出力が恒等関数(sigmoidとかじゃない)ので,出力範囲は[0,1]とは限らないですね...)
モデルのパラメータとかは以下を参考にしました.
Conditional DCGANの構造
さて,基本的なGANの仕組みがわかったところで,GANの問題(って言うと語弊あるけど)は何でしょうか?
それは生成時に目的のデータを生成しにくいということです.
MNISTで考えるとわかりやすいです.画像の生成プロセスにおいて,乱数から学習画像を再現するように学習していましたが,どの乱数がどの画像を生成するかまでは明示的に記述していませんでした.つまり,0の画像を生成するような乱数群があるにはあるんだけど,どの乱数が0を生成するかわからない状況になっています.
(プログラム的にはx_fakeとx_realはミニバッチで入れている.これをバッチサイズ1で入れたらある乱数と学習データが1対1対応になる.するとある乱数に対して毎回異なる学習データが与えられて,学習が上手くいかない気がする... .余力があれば実験してみたい.)
そこで**Condition(条件)**をつけてやります.
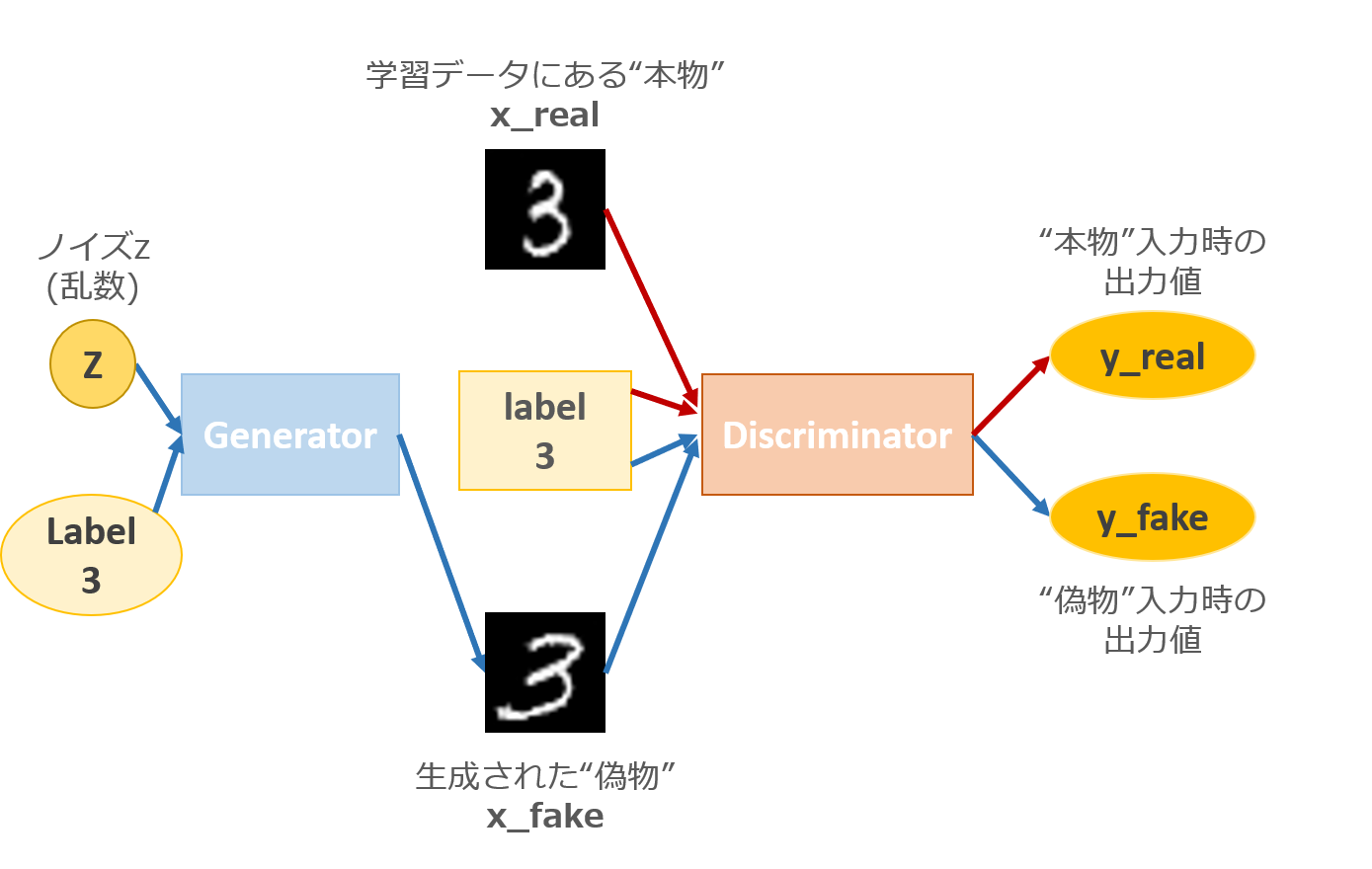
上図では,明示的に3の数字を生成するような条件を付与しています.今回は x_real(MNISTデータ)に付与されているラベル0~9を条件として与えます.こうすることで,生成時に指定したラベルをもつクラスのMNIST画像を生成することができるようになります.
こうすることで,どの乱数がどのクラスの画像を生成するかということを考える必要がなくなります.直感的にはラベルによって0を生成する乱数空間, 1を生成する乱数空間...というようにクラスごとの空間自体を切り離すことができると考えられます.なので,同一乱数であってもラベルさえ違えば違うクラスの画像が生成できます.
ここで,DCGANにおいてはDiscriminatorへのラベルの入れ方が問題になってきます.
入れ方に関しては以下に詳しく書いてあります.
http://yusuke-ujitoko.hatenablog.com/entry/2017/10/24/203133
今回は上記サイトのパターンA:Discriminatorの入力層へラベルを入力する方法をとります.Discriminatorの入力はx_real(またはx_fake)と同一次元のデータでなければなりません.なので,1ch(gray)×28×28の画像を10クラス分用意して,指定クラスの画素地を全て1,それ以外を全て0にしてラベルとします.プログラムでは下記のようにしています.
# 88行目以降
# バッチ内の各文字に対応したラベルを入力
# 画像と同じ形のラベルに変形する. ラベルの画像は全て画素値1, それ以外のクラスは0にする.
one_hot = xp.ones((x.data.shape[0],10,28,28)) * label
one_hot = chainer.Variable(xp.asarray(one_hot, dtype=xp.float32))
# バッチ内のある一つの(1,28,28)の画像に対して(10,28,28)のラベル画像を与えるのでaxis=1.
x = F.concat((x, one_hot), axis=1)
Conditional DCGANのラベルを色々いじってみる
いよいよ本題です.なんのためのアプリだったのか.そうです,直感的操作でいろいろなラベルパターンを試すためです.
ちなみに今回は,ノイズzの次元を100,データサイズ60,000枚,batchサイズ50,epoch数100で学習させた学習済みのGeneratorを使用して画像を生成します.詳しくはこちらを参照.
アプリの使い方
まず簡単にアプリの使い方から.アプリを立ち上げると以下のような画面が出ると思います.

スライドバー上の青枠で囲まれた「ラベル」は指定するラベルを表しています.その横の数字はラベルの値で,0~1まで0.001刻みで指定できます.例えば乱数から1の画像を生成したかったら,ラベル1のスライドバーを動かして1に設定します.それ以外は0にしてください.すると(高確率で)1っぽい画像が生成されるはずです!
実験
実験というほどの実験ではありませんが,何パターンか試してみたいと思います.
毎回乱数が異なるので,4試行ずつ行ってみたいと思います.
(1)全て0

(2)全て1

(試行ごとにコロコロ変わりますね...)
今回の学習済みモデルに関しては,
- 全て0だと丸い形が生成されやすい.
- 全て1だと1っぽい画像が生成されやすい.あるいは直線成分を持つ画像が生成されやすい.
という傾向が見られました.あくまで主観ですが.
このことから,今回の場合だと「ラベル全部0の場合の特徴空間」と「ラベル全部1の場合の特徴空間」は丸成分 <---> 直線成分で分かれているのではないかと考えられます.すると,「ラベル全部0.5」ではその中間の丸と直線が半々くらいの画像が生成されるの可能性が考えられます.
(3)全て0.5
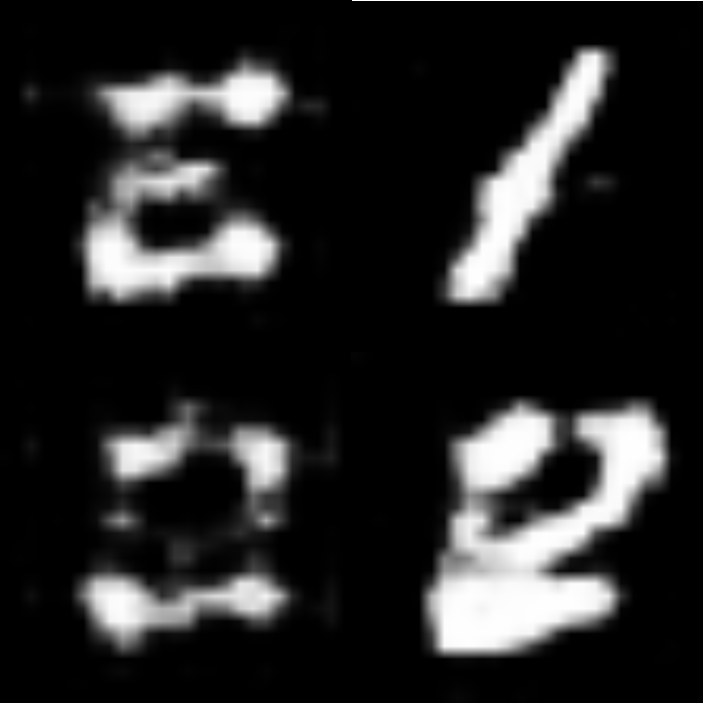
確かに,ラベル全部0.5においては丸と直線が半々くらいで生成されました.(丸と直線という異なる特徴同士の中間画像なので,画像がぐちゃぐちゃになっている気がします)
そこで次は丸と直線の代表ともいえる0と1の中間画像を生成してみたいと思います.
(4)ラベル0と1を1ずつ

(5)ラベル0と1を0.5ずつ

全体的に丸の方が出やすいのかなという感じです.
まとめ
今回はConditional DCGANのラベルを色々いじってみました.学習時に指定していないラベルを指定した場合にどのような画像が生成されるかを観察し,特徴空間の分布の様子を考えてみました.
丸っぽい <---> 直線っぽい数字を考えたとき,0 - 8 - 6,9 - 3 - 2 - 5 --- 4 - 7 - 1 かなと個人的には思っていて,丸と直線で線引きするとしたら5と4の間だと思っています.すると,全てのラベルを1にした場合の方が丸成分もつ数字を多く含むので,丸っぽい画像が生成されやすいかなと思ったのですが,結果は予想とは逆でした.
理由については良くわかりませんが,各数字の直線と曲線の割合を算出したら,もしかしたら直線成分の方が多い可能性が考えられます.Conditional GANのラベル操作に関してどれだけ言及する価値があるかは正直わかりませんが,アプリで直感的な操作が出来るのは面白かったです!
次回はアプリ開発の流れについて書きたいと思います!!