はじめに
こんにちは、NTTテクノクロスでAWSの開発エンジニアをやらせていただいています。だはです。
元教員として、初心者目線から色々な記事を書かせていただいています。
ちなみに今回はNTTテクノクロスアドベントカレンダーシリーズ1の4日目となります。
今回は社内の勉強会を通して学んだことをアウトプットしていこうと思います。
ある書籍のハンズオンを実施し、その一部をCloudFormationでテンプレート化しています。
私が調べた範囲では「データレイクのIaC (Infrastructure as Code)」にダイレクトにヒットする記事がなかったので、今後同様のニーズがあった方の手助けになると幸いです。
目次
1.概要
2.アーキテクチャの中身
3.コード
4.学んだこと
5.あとがき
1.概要
前書きでも紹介した通り、この記事は「AWSではじめるデータレイク」の内容において、各種ハンズオンを実施して書いたものです。

本記事を書くに至った流れとしては、
- 社内の研修で、データレイクについて学ぶ機会があった
- 研修の内容は、書籍を参考にデータレイクアーキテクチャを作成して理解を深めるものであった
- 研修ではマネコンをポチポチしていたので、理解を深めるためにCloudFormationでIaC化してみることにした
- 本来はググりながら作るつもりだったが、あまり欲しい記事が無かった
- 手作業で探りながら作ったので、記事にすることとした
データレイクとは何か、という議論はもっと詳しい方が語り尽くされていると思いますので、そちらを参考にしてください。
2.アーキテクチャの中身
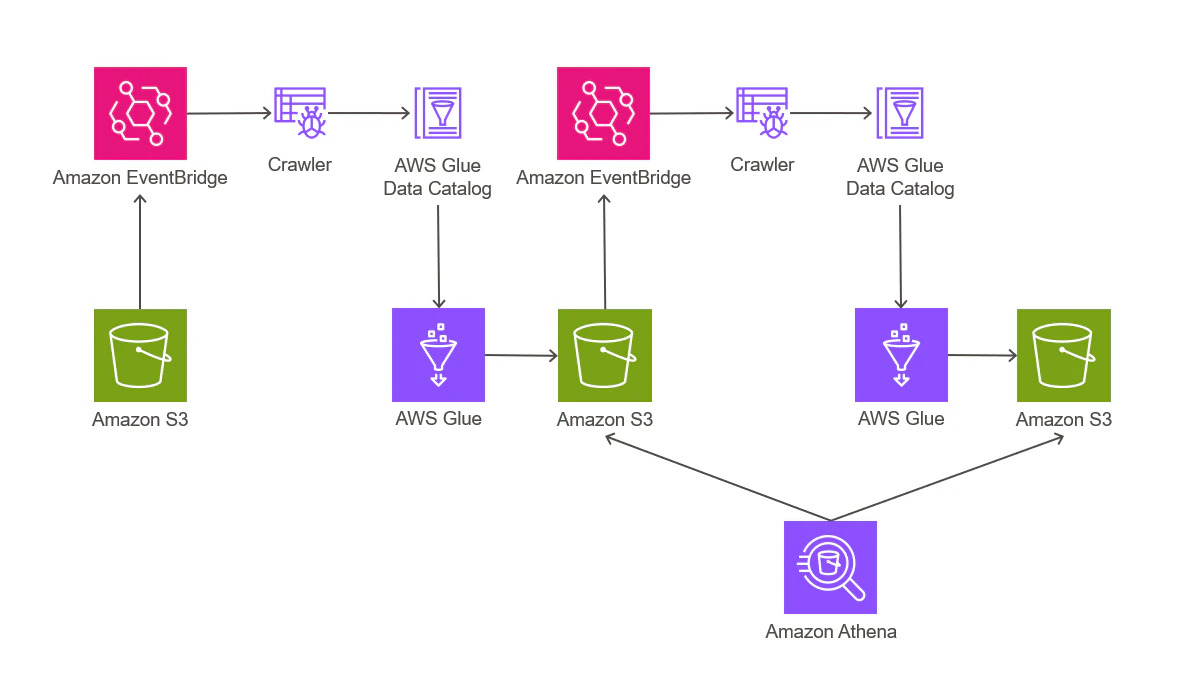
以下に処理の流れを載せます。
- S3バケットにcsvファイルを保存(ここは手動)
-----ここから自動----- - S3バケットにPutObjectされたことが、EventBridgeを通してGlueのTriggerに通知される
- GlueのTriggerがWorkflowを動かし、CrawlerとJobを動作させる
- CrawlerとJobは、1で保存されたデータに関して、個人情報をマスキングし、
- 4で加工後のファイルをS3バケットに保存する
- 5の保存に際して、S3バケットにPutObjectされたことが、再度EventBridgeを通して別のGlueのTriggerに通知される
- GlueのTriggerがWorkflowを動かし、CrawlerとJobを動作させる
- 5で保存されたデータに関して、日付ごとにフォルダを分け、
- 8で加工後のファイルをS3バケットに保存する。
-----ここまで自動----- - 必要に応じて、AthenaやQuickSightでデータを閲覧
3.コード
今回のコード
AWSTemplateFormatVersion: 2010-09-09
Description: CFn template for DataLake Architecture
Parameters:
#作成者名をリソースの接尾辞に設定
UserName:
Description: Resource Name Suffix Using Making User Name
Type: String
Default: test
#Output1Jobのスクリプト名を誘導してあげる
Output1ScriptName:
Description: Output1 Script Name in S3Bucket
Type: String
Default: Output1_Job.py
#Output2Jobのスクリプト名を誘導してあげる
Output2ScriptName:
Description: Output2 Script Name in S3Bucket
Type: String
Default: Output2_Job.py
Resources:
##----------以下S3リソース群----------
#-----以下インプット用のS3バケット-----
InputBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub input-bucket-hogehoge-${UserName}
LifecycleConfiguration:
Rules:
- Id: 1years-delete
Status: Enabled
ExpirationInDays: 365
NotificationConfiguration:
EventBridgeConfiguration:
EventBridgeEnabled: true
Tags:
- Key: Name
Value: !Ref UserName
#-----以上インプット用のS3バケット-----
#-----以下1次アウトプット用のS3バケット-----
Output1Bucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub output1-bucket-hogehoge-${UserName}
LifecycleConfiguration:
Rules:
- Id: 1years-delete
Status: Enabled
ExpirationInDays: 365
NotificationConfiguration:
EventBridgeConfiguration:
EventBridgeEnabled: true
Tags:
- Key: Name
Value: !Ref UserName
#-----以上1次アウトプット用のS3バケット-----
#-----以下2次アウトプット用のS3バケット-----
Output2Bucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub output2-bucket-hogehoge-${UserName}
LifecycleConfiguration:
Rules:
- Id: 1years-delete
Status: Enabled
ExpirationInDays: 365
NotificationConfiguration:
EventBridgeConfiguration:
EventBridgeEnabled: true
Tags:
- Key: Name
Value: !Ref UserName
#-----以上2次アウトプット用のS3バケット-----
##----------以上S3リソース群----------
##----------以下Glueリソース群----------
#-----以下Output1用のWorkflow-----
Output1Workflow:
Type: AWS::Glue::Workflow
Properties:
Name: !Sub Input-to-Output1-Workflow-${UserName}
Description: Glue workflow triggered by S3 PutObject Event for Output1
#-----以上Output1用のWorkflow-----
#-----以下Output2用のWorkflow-----
Output2Workflow:
Type: AWS::Glue::Workflow
Properties:
Name: !Sub Output1-to-Output2-Workflow-${UserName}
Description: Glue workflow triggered by S3 PutObject Event for Output2
#-----以上Output2用のWorkflow-----
#-----以下Output1用のJobTrigger1-----
Output1JobTrigger1:
Type: AWS::Glue::Trigger
Properties:
Name: !Sub Input-to-Output1-Job-Trigger-1-${UserName}
Description: Glue trigger which is listening on S3 PutObject events
Type: EVENT
EventBatchingCondition:
BatchSize: 1
Actions:
- CrawlerName: !Ref InputGlueCrawler
WorkflowName: !Ref Output1Workflow
Tags:
Key: Name
Value: !Ref UserName
#-----以上Output1用のJobTrigger1-----
#-----以下Output1用のJobTrigger2-----
Output1JobTrigger2:
Type: AWS::Glue::Trigger
Properties:
Name: !Sub Input-to-Output1-Job-Trigger-2-${UserName}
Description: Glue trigger which is listening on Glue Crawler events
Type: CONDITIONAL
Predicate:
Conditions:
- LogicalOperator: EQUALS
CrawlerName: !Ref InputGlueCrawler
CrawlState: SUCCEEDED
Logical: AND
StartOnCreation: True
Actions:
- JobName: !Ref Output1GlueJob
WorkflowName: !Ref Output1Workflow
Tags:
Key: Name
Value: !Ref UserName
#-----以上Output1用のJobTrigger2-----
#-----以下Output2用のJobTrigger1-----
Output2JobTrigger1:
Type: AWS::Glue::Trigger
Properties:
Name: !Sub Output1-to-Output2-Job-Trigger-1-${UserName}
Description: Glue trigger which is listening on S3 PutObject events
Type: EVENT
EventBatchingCondition:
BatchSize: 1
Actions:
- CrawlerName: !Ref Output1GlueCrawler
WorkflowName: !Ref Output2Workflow
Tags:
Key: Name
Value: !Ref UserName
#-----以上Output2用のJobTrigger1-----
#-----以下Output2用のJobTrigger2-----
Output2JobTrigger2:
Type: AWS::Glue::Trigger
Properties:
Name: !Sub Output1-to-Output2-Job-Trigger-2-${UserName}
Description: Glue trigger which is listening on Glue Crawler events
Type: CONDITIONAL
Predicate:
Conditions:
- CrawlerName: !Ref Output1GlueCrawler
CrawlState: SUCCEEDED
LogicalOperator: EQUALS
Logical: AND
StartOnCreation: True
Actions:
- JobName: !Ref Output2GlueJob
WorkflowName: !Ref Output2Workflow
Tags:
Key: Name
Value: !Ref UserName
#-----以上Output2用のJobTrigger2-----
#-----以下インプット用のGlueDatabase-----
InputDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Description: Input Data
Name: !Sub input-database-${UserName}
#-----以上インプット用のGlueDatabase-----
#-----以下1次アウトプット用のGlueDatabase-----
Output1Database:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Description: First Output Data Done Compression and Conversion
Name: !Sub output1-database-${UserName}
#-----以上1次アウトプット用のGlueDatabase-----
#-----以下2次アウトプット用のGlueDatabase-----
Output2Database:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Description: Second Output Doing Masking and Making Partition
Name: !Sub output2-database-${UserName}
#-----以上2次アウトプット用のGlueDatabase-----
#-----以下GlueClassifier-----
DataLakeArchitectureClassifier:
Type: AWS::Glue::Classifier
Properties:
CsvClassifier:
AllowSingleColumn: False
ContainsHeader: UNKNOWN
Delimiter: "\t"
DisableValueTrimming: True
Name: !Sub datalake-architecture-classifier-${UserName}
QuoteSymbol: '"'
#-----以上GlueClassifier-----
#-----以下インプット用のGlueCrawler-----
InputGlueCrawler:
Type: AWS::Glue::Crawler
Properties:
Classifiers:
- !Sub datalake-architecture-classifier-${UserName}
DatabaseName: !Ref InputDatabase
Description: Input Data
Name: !Sub Input-Crawler-${UserName}
Role: !Sub service-role/${IAMRoleForGlue}
TablePrefix: Input-Crawled-
Targets:
S3Targets:
- Path: !Ref InputBucket
DependsOn: IAMRoleForGlue
#-----以上インプット用のGlueCrawler-----
#-----以下1次アウトプット用のGlueCrawler-----
Output1GlueCrawler:
Type: AWS::Glue::Crawler
Properties:
Classifiers:
- !Sub datalake-architecture-classifier-${UserName}
DatabaseName: !Ref Output1Database
Description: First Output Doing Compression and Conversion
Name: !Sub Output1-Crawler-${UserName}
Role: !Sub service-role/${IAMRoleForGlue}
TablePrefix: Output1-Crawled-
Targets:
S3Targets:
- Path: !Ref Output1Bucket
DependsOn: IAMRoleForGlue
#-----以上1次アウトプット用のGlueCrawler-----
#-----以下2次アウトプット用のGlueCrawler-----
Output2GlueCrawler:
Type: AWS::Glue::Crawler
Properties:
Classifiers:
- !Sub datalake-architecture-classifier-${UserName}
DatabaseName: !Ref Output2Database
Description: Second Output Doing Masking and Making Partition
Name: !Sub Output2-Crawler-${UserName}
Role: !Sub service-role/${IAMRoleForGlue}
TablePrefix: Output2-Crawled-
Targets:
S3Targets:
- Path: !Ref Output2Bucket
DependsOn: IAMRoleForGlue
#-----以上2次アウトプット用のGlueCrawler-----
#-----以下1次アウトプット用のGlueJob-----
Output1GlueJob:
Type: AWS::Glue::Job
Properties:
Command:
Name: glueetl
ScriptLocation: !Sub "s3://script-bucket-hogehoge-${UserName}/${Output1ScriptName}"
Description: First Output Doing Compression and Conversion
GlueVersion: "4.0"
Name: !Sub Output1-GlueJob-${UserName}
#NotificationProperty: NotificationProperty
Role: !GetAtt IAMRoleForGlue.Arn
Tags:
Key: Name
Value: !Ref UserName
#-----以上1次アウトプット用のGlueJob-----
#-----以下2次アウトプット用のGlueJob-----
Output2GlueJob:
Type: AWS::Glue::Job
Properties:
Command:
Name: glueetl
ScriptLocation: !Sub "s3://script-bucket-hogehoge-${UserName}/${Output2ScriptName}"
Description: Second Output Doing Masking and Making Partition
GlueVersion: "4.0"
Name: !Sub Output2-GlueJob-${UserName}
#NotificationProperty: NotificationProperty
Role: !GetAtt IAMRoleForGlue.Arn
Tags:
Key: Name
Value: !Ref UserName
#-----以上2次アウトプット用のGlueJob-----
##----------以上Glueリソース群----------
#-----以下Athena-----
AthenaWorkgroup:
Type: AWS::Athena::WorkGroup
Properties:
Description: Used for DataLake Architecture
Name: !Sub WorkGroup-${UserName}
State: ENABLED
Tags:
- Key: Name
Value: !Ref UserName
#-----以上Athena-----
#-----以下Glue用のIAMRole-----
IAMRoleForGlue:
Type: AWS::IAM::Role
Properties:
Path: /service-role/
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: "Allow"
Principal:
Service:
- "glue.amazonaws.com"
Action:
- "sts:AssumeRole"
Description: Used for Glue
ManagedPolicyArns:
- arn:aws:iam::aws:policy/AmazonS3FullAccess
- arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole
Policies:
- PolicyName: !Sub Glue-ServiceRole-kms-Policy-${UserName}
PolicyDocument:
Version: 2012-10-17
Statement:
- Sid: KmsDecrypt
Effect: Allow
Action:
- "kms:Decrypt"
Resource: "*"
RoleName: !Sub AWSGlueServiceRole-${UserName}
Tags:
- Key: Name
Value: !Ref UserName
#-----以上Glue用のIAMRole-----
#-----以下EventBridge用のIAMRole-----
EventBridgeToGlueExecutionRole:
Type: AWS::IAM::Role
Properties:
RoleName: !Sub EventBridgeToGlueExecutionRole-${AWS::StackName}
Description: It has permissions to invoke the NotifyEvent API for an AWS Glue workflow.
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service:
- events.amazonaws.com
Action:
- sts:AssumeRole
GlueNotifyEventPolicy:
DependsOn:
- Output1Workflow
- Output2Workflow
Type: AWS::IAM::Policy
Properties:
PolicyName: !Sub GlueNotifyEventPolicy-${AWS::StackName}
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: "Allow"
Action:
- glue:notifyEvent
Resource: !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:workflow*
Roles:
- !Ref EventBridgeToGlueExecutionRole
#-----以上EventBridge用のIAMRole-----
#-----以下Output1用のEventBridge-----
Output1EventBridgeRule:
DependsOn:
- Output1Workflow
Type: AWS::Events::Rule
Properties:
Name: !Sub s3_file_upload_trigger_rule_Input-${AWS::StackName}
EventPattern:
detail-type:
- "Object Created"
source:
- "aws.s3"
detail:
bucket:
name:
- !Ref InputBucket
Targets:
- Arn: !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:workflow/${Output1Workflow}
Id: S3InputToOutput1Workflow
RoleArn: !GetAtt EventBridgeToGlueExecutionRole.Arn
#-----以上Output1用のEventBridge-----
#-----以下Output2用のEventBridge-----
Output2EventBridgeRule:
DependsOn:
- Output2Workflow
Type: AWS::Events::Rule
Properties:
Name: !Sub s3_file_upload_trigger_rule_Output1-${AWS::StackName}
EventPattern:
detail-type:
- "Object Created"
source:
- "aws.s3"
detail:
bucket:
name:
- !Ref Output1Bucket
Targets:
- Arn: !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:workflow/${Output2Workflow}
Id: S3Output1ToOutput2Workflow
RoleArn: !GetAtt EventBridgeToGlueExecutionRole.Arn
4.学んだこと
今回のハンズオンとその記事作成で学んだことは、以下の3点です。
- 1つ1つのリソースについて、リソースやパラメータを見直すことができた
私はCloudFormationのテンプレートを書く際、必ずリソースごとにリファレンスを見るようにしています。
例えばS3バケットであれば、"AWS::S3::Bucket"と検索すれば出てくるはずです。
これを見ると、普段意識して設定することのなかったパラメータも参照することができます。マネコンではなんとなく設定していた部分を明示的に"true"または"false"で判断することになるので、(思考リソースを割くけれども)勉強になるポイントです。
ついでに、EventBridgeのような「サービスとサービスの間に挟まっているサービス」なんかも、ここで可視化されます。IaCの場合は、はっきり設定しないと動いてくれない、というのが逆に勉強になります。
このサービス有無やパラメータ値の判断に応じて、更に関連するパラメータを検討したり、俯瞰的に機能を取捨選択したりできるので、各種リソースへの理解を深める機会になりました。
S3バケットの例で挙げるならば、バージョニング設定なんかは奥が深いと思いました。
CodePipelineのソースにするならばバージョニング設定が必須だし、このバージョニングを"true"にするだけだとオブジェクトが溜まっていくのでライフサイクルを考えなきゃいけないし、試験と違って顧客から期間を明示されないパターンもありえるし...(etc
ただマネコンをポチポチして作成するだけだったS3バケットでも、意識することが増えたのは大きな学びかと思いました。
- 厳密な定義を意識するようになった
IaCあるあるではあると思いますが、適当な書き方をしていると色々な書き方を色々なところで弾かれます。例えば、
→Parameterの名前を英語にしたら、変なスペルをVSCodeに怒られる
→存在しないTypeを宣言したら、VSCodeに怒られる
→何かしらパラメータの設定が足りてなくて、CloudFormationに怒られる
→いざテンプレートをデプロイしてみたら、S3バケットの名前が長過ぎてCloudFormationに怒られる
...なんて経験、数えきれないほどありました。マネコンって優秀だったんだなあ。
逆にAWSを触る裏側では、「こんな設定をいじることもできる」「ここは裏でこういう設定をされている」という勉強にもなりました。
今後は先回りして、「このリソースが関わるときはここまで考えておいた方がいいな」という教訓になっています。
- ある種のリバースエンジニアリング的なことを実践することができた
正直私はコーディングが得意ではないので、今回苦労したのは(書いてないけど)「PythonでGlueのJobを定義しなきゃいけない」という場面でした。
リファレンスとVSCodeを眺めること数時間、結局自分で書くことを諦めたことを覚えています。
日を改めてマネコン操作をしてみたところ、(そういえば)Pythonコードを自動生成してくれていたことに気づきました。
そこでコードをコピペして、多少改変することで完成に持っていくことができました。
目の前の作業に詰まったら切り口を変えてみる、というのは有効な手段であることを学びました。
エンジニアとして働いてまだ1年経っていない時期でしたが、良い学習になったと感じています。
5.あとがき
今回は、ある書籍を参考にデータレイクアーキテクチャを作成し、成果物をテンプレート化してみました。
マネージメントコンソールでチマチマクリックするのはミスの原因にもなりかねないので、リソース作成を定型化できたのは嬉しいかな、と思っています。
以上NTTテクノクロスアドベントカレンダーの4日目、だはがお送りしました。
弊社に興味を持っていただけた方は、こちらをご覧ください。
明日は@watanyさんの記事「DuckDBでcloudtrail みる」になります。どうぞお楽しみに!Merry Christmas!