- 製造業出身のデータサイエンティストがお送りする記事
- 今回はSHAPを用いて機械学習(回帰モデル)の予測結果を解釈してみました。
はじめに
前回、機械学習の予測モデルをscikit-learnを活用して実装してみました。また、構築したモデルは評価指標を用いてモデルを評価します。
しかし、評価指標だけでモデルの良し悪しを判断するのは危険であり、構築したモデルが実態と乖離している場合があります。つまり、汎化能力が低いモデルである可能性があるということです。
汎化能力を高める方法は多々ありますが、製造現場では構築したモデルの解釈性を求められることが多いです。実際は、回帰モデル系であれば各説明変数の回帰係数の正負や標準偏回帰係数で変数間の影響度を見て固有技術と合致しているかを見極めたりします。また、決定木系のモデルであれば変数重要度を見て判断をします。
しかし、決定木系のモデル(RandomForest、GBDT、等)は各変数が目的変数へ与える影響の正負を判断することができません。また、SVRではカーネルをlinear以外を選択すると回帰係数も変数重要度も算出することができません(※scikit-learnのライブラリーに限った話です)。
そこで、今回は上記のような課題を解決する手段の一つとして、SHAPを用いて、予測した値に対して、「各変数がどのような影響を与えたのか?」を可視化する技術を整理しました。
SHAPとは

理論的な詳細は今回は省略します。
SHAPの実装
今回はUCI Machine Learning Repositoryで公開されているボストン住宅の価格データを用いて予測モデルを構築します。
| 項目 | 概要 |
|---|---|
| データセット | ・boston house-price |
| サンプル数 | ・506個 |
| カラム数 | ・14個 |
pythonのコードは下記の通りです。
# 必要なライブラリーのインポート
import pandas as pd
import numpy as np
import shap
from sklearn.datasets import load_boston
# データセットの読込み
boston = load_boston()
# データフレームの作成
# 説明変数の格納
df = pd.DataFrame(boston.data, columns = boston.feature_names)
# 目的変数の追加
df['MEDV'] = boston.target
# データの中身を確認
df.head()
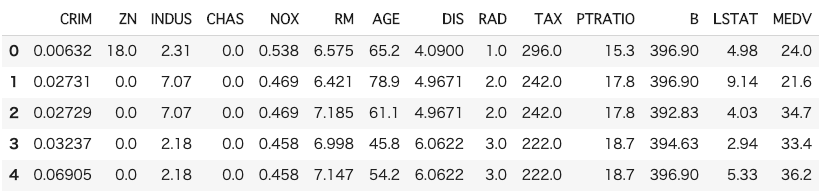
各カラム名の説明は省略します。
・説明変数:13個
・目的変数:1個(MEDV)
次に、予測モデルを構築します。今回は、RandomForest回帰を活用します。
# ライブラリーのインポート
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
# 学習データと評価データを作成
x_train, x_test, y_train, y_test = train_test_split(df.iloc[:, 0:13], df.iloc[:, 13],
test_size=0.2, random_state=1)
# モデルの学習
RF = RandomForestRegressor()
RF.fit(x_train, y_train)
SHAPで結果を解釈する
最初に、SHAPの説明木の作成とSHAP値を算出します。
今回は、Tree系モデルのため、shap.TreeExplainerを使用します。
SVRなどに適用する場合はshap.KernelExplainerに書き換えが必要です。
explainer = shap.TreeExplainer(RF)
shap_values = explainer.shap_values(X=x_train)
次に変数重要度を算出してみます。
shap.summary_plot(shap_values, x_train, plot_type="bar")
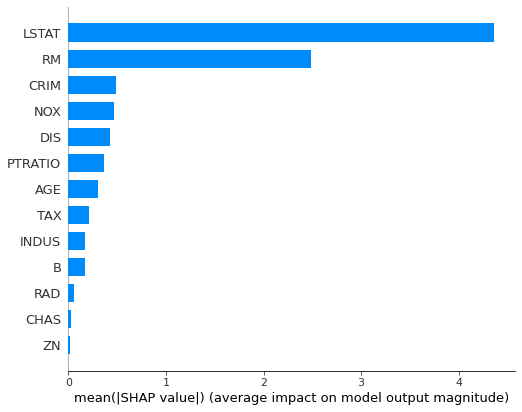
ここで、RandonForestであれば、scikit-learnでも変数重要度を算出することができるので、算出してみようと思います。
import matplotlib.pyplot as plt
%matplotlib inline
features = df.columns
importances = RF.feature_importances_
indices = np.argsort(importances)
plt.figure(figsize=(6,6))
plt.barh(range(len(indices)), importances[indices], color='b', align='center')
plt.yticks(range(len(indices)), features[indices])
plt.show()
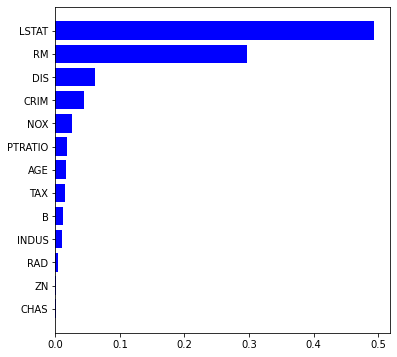
結果は全く一緒ではないですが、LSTAT、RMが重要な部分は似ておりますね。算出式が異なるので結果が異なるのは当たり前ですが。
次に、SHAP value とFeature value の関係性を確認します。
shap.summary_plot(shap_values, x_train)
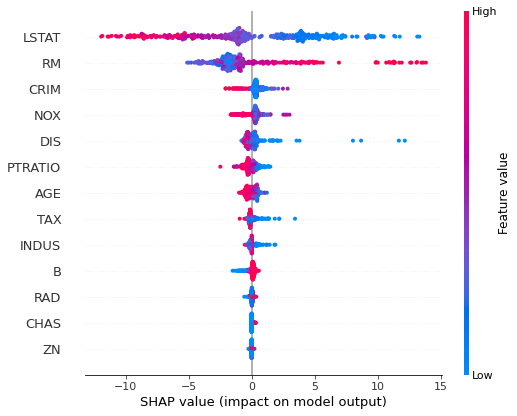
結果の見方は、横軸がSHAP値を表しており、縦軸が変数重要度を表しております。赤が正の値、青が負の値を示しております。
次に一つの入力結果に対する予測結果の解釈を確認します。
shap.initjs()
shap.force_plot(explainer.expected_value, shap_values[0,:], x_train.iloc[0,:])

この図はRandomForest回帰の予測結果24.98を計算する際の各変数の寄与を表しております。目的変数の結果を正の方向へ動かすのに寄与した変数が赤で示しており、負の方向へ動かすのに寄与したの変数が青で示されております。
最後に全てのデータを用いて可視化してみます。
shap.force_plot(base_value=explainer.expected_value, shap_values=shap_values, features=x_train)
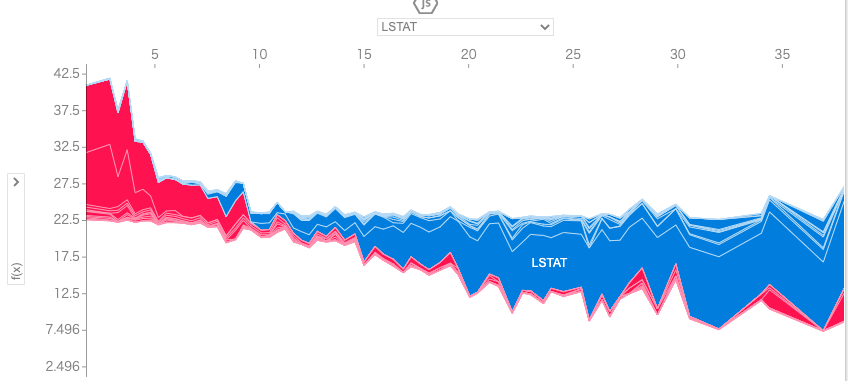
上記の結果を見るとLSTAT(給与の低い職業に従事する人口の割合)が高くなるほど、住宅価格が低くなることが読み取れます。
さいごに
最後まで読んで頂き、ありがとうございました。
今回は予測モデルの結果を解釈する手法としてSHAPを実装してみました。
製造業では上司、現場へ説明する際に解釈が求められます。ブラックボックスモデルでなぜか良い結果が出ましたでは、納得してもらえないことが多いかと思います。しかし、SHAPを活用することでその問題も解決することができます。
訂正要望がありましたら、ご連絡頂けますと幸いです。