- 製造業出身のデータサイエンティストがお送りする記事
- 今回は普段使っているscikit-learn の機能(モデル評価)について整理してみました。
はじめに
普段からscikit-learn を使用しているのですが、規模が大き過ぎて必要な部分は毎回ググリなら実装しておりますので、勉強も兼ねて整理してみました。
前回、scikit-learnの機能(モデル構築)を整理しておりますので、ご参考にして頂けますと幸いです。
モデル評価
モデル評価において下記3点について調査しました。
- 評価関数
- 交差検証
- パラメータチューニング
評価関数
評価関数は、モデルを評価するための指標を計算してくれる関数です。
後半でご説明します、交差検証やパラメータチューンニングにおいても評価関数は使用します。
Classifier(分類器)の代表的な評価関数(混同行列)
Classifier で使用する代表的な評価関数を整理します。その際、下記の予測値と実測値の評価マトリックスを使用して評価することが多いので最初に整理します。
| 予測値 | |||
|---|---|---|---|
| Positive | Negative | ||
| 実測値 | Positive | True Positive (TP) |
False Negative (FN) |
| Negative | False Positive (FP) |
True Negative (TN) |
代表的な混同行列系の評価関数を下記に整理します。
| モジュール | 概要 |
|---|---|
| accuracy | 正解率(全サンプルのうち、予測値と実測値が等しいものの割合) (TP+TN)/(TP+FP+FP+TN) |
| precision | 適合率(Positiveと予測したもののうち、実測値がPositiveであったものの割合) TP/(TP+FP) |
| recall | 再現率(実測値がPositiveであったもののうち、Positiveと予測したものの割合) TP/(TP+FN) |
| f1_score | F1スコア(適合率と再現率の調和平均 (2∗precision∗recall)/(precision+recall) |
| fbeta_score | F1スコアにおいて、再現率にβ倍の重みを付与したもの |
| classification_report | 正解率(accuracy)、適合率(precision)、再現率(recall)、F1スコア(f1_score)を同時に表示 |
Classifier(分類器)の代表的な評価関数(混同行列以外)
混同行列以外の評価関数を下記に整理します。
| モジュール | 概要 |
|---|---|
| auc | Area under the curveの略。ROC曲線の下側の面積を意味する |
| hinge_loss | ヒンジ損失。正解であっても、境界面付近の場合は損失を与える |
| log_loss | 交差エントロピー誤差 |
Classifier(分類器)の代表的な評価プロット
代表的な評価プロットを下記に整理します。
| モジュール | 概要 |
|---|---|
| plot_confision_matrix | 混合行列を表示 |
| plot_roc | ROC曲線をプロット |
| plot_precision_recall | 適合率と再現率をプロット |
| plot_learning_curve | サンプル数の増加に対して精度がどのように変化するのかをプロット |
Regressor(回帰器)の代表的な評価関数
Regressor(回帰器)で使用する評価関数を下記に整理します。
| モジュール | 概要 |
|---|---|
| r2_score | 決定係数 |
| mean_squared_error | 平均二乗誤差(MSE) |
| mean_squared_log_error | 平均二乗対数誤差(MSLE) |
| mean_absolute_error | 平均絶対誤差(MAE) |
| explainede_variance_score | モデルで説明可能な分散 |
Regressor(回帰器)の代表的な評価プロット
代表的な評価プロットを下記に整理します。
| モジュール | 概要 |
|---|---|
| ErrorPlot | 実測値と回帰直線との乖離をプロット |
| ResidualsPlot | 予測値に対する残差をプロット |
| AlphaPlot | L1, L2正則化の重みαを変えた際の誤差をプロット |
Culster(クラスタリング器)の代表的な評価関数
Culster(クラスタリング器)で使用する評価関数を下記に整理します。
| モジュール | 概要 |
|---|---|
| silhouette | シルエット係数 正解ラベル不要 クラスタのコンパクトさを計算し,完全な場合で1となる |
| calinski_harabasz_score | クラスタ内の分散がクラスタ間の分散よりも大きいほど高い評価 正解ラベル不要 |
| adjuested_mutual_info_score | 調整済み相互情報量 正解ラベルが必要 |
| homogeneity | ひとつのクラスタが含むラベルが同じほど高い評価 正解ラベルが必要 |
| completeness | ひとつのラベルが含むクラスタが同じほど高い評価 正解ラベルが必要 |
| v-measure | homogeneity とcompleteness との調和平均 正解ラベルが必要 |
Culster(クラスタリング器)の代表的な評価プロット
代表的な評価プロットを下記に整理します。
| モジュール | 概要 |
|---|---|
| plot_silhouette | シルエット係数をプロット |
| plot_elbow_curve | クラスタ数とクラスタ内誤差平方和の関係をプロット クラスタ数を決める際に使用 |
交差検証
交差検証とは、一つの学習データ(train)と検証データ(valid)の組合せだけでモデルを評価すると過学習している可能性もあるため、複数回の組合せパターンで検証を行い、モデルの汎化性能を高める事を交差検証と呼びます。
交差検証を進めていく上で必要な要素は下記3点です。
- 評価指標
- 交差検証イテレータ
- 交差検証関数
上記については、各々説明していきます。
交差検証イテレータ
複数回の検証をするためのイテレータです。学習データ(train)と検証データ(valid)の分割方法が異なるイテレータが用意されております。
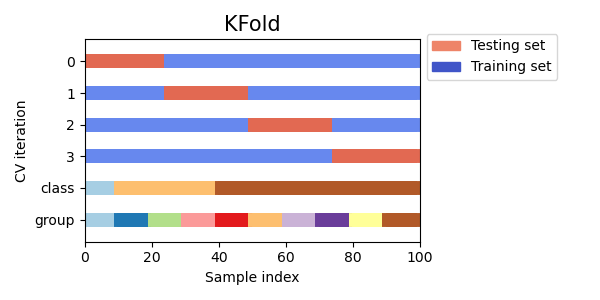
K Fold
最もメジャーな交差検証イテレータです。手順は下記です。
- データセットをランダムにK個に分割します。
- K-1個を学習データ、1個を検証データとして検証をK回繰り返します。
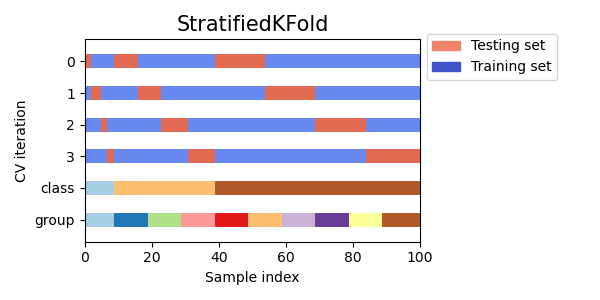
Stratified K Fold
K Foldにおいて、データ分割時に層化を行います。層化を行うことで、全Foldでラベルの割合が同じになるようにすることができます。
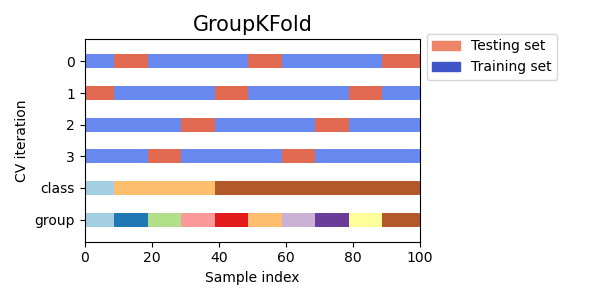
Group K Fold
一つのグループが複数のFoldに跨がらないようにします。例えば、購買データとかで一人あたり複数のレコードがある場合、一人の購買データのログを一つのFoldだけに割り当てるようにして検証時にデータリークが発生しないようにします。
Leave One Out/ Leave P Out
Leave One Outは、1サンプルだけを検証データとする評価をサンプル数nだけ繰り返します。
Leave P Outは、P個のサンプルを検証データとする評価をn/p回繰り返します。
ただし、Leave One OutはFold数nのKFoldと同等、Leave P OutはFold数n/pのKFoldと同等なため、KFoldで代用可能らしいです。
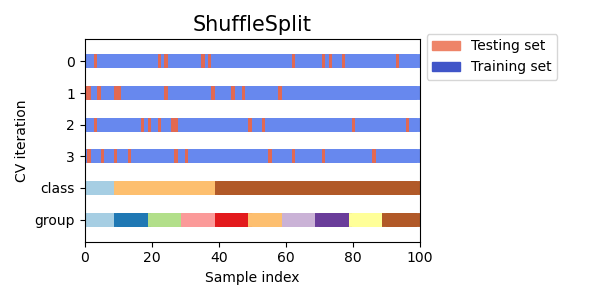
Shuffle Split
イテレーションのたびに学習データと検証データをシャッフルします。KFoldと異なり、一つのサンプルが複数回検証に使用される可能性があります。
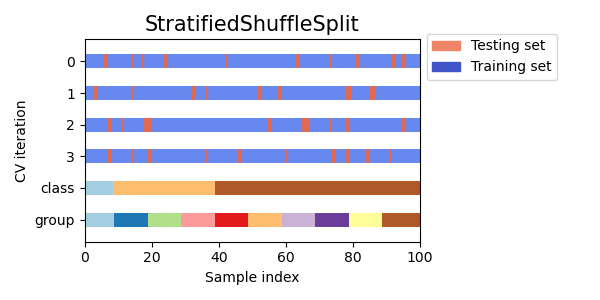
Stratified Shuffle Split
Shuffle Splitの各イテレーションで学習データと検証データの層化を行います。
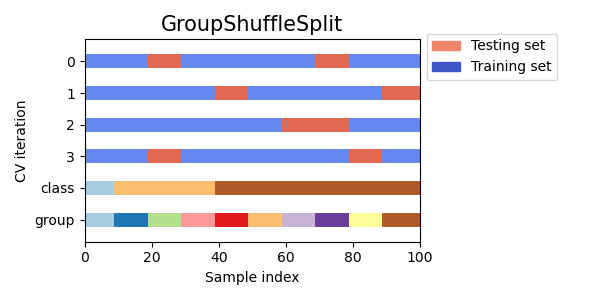
Group Shuffle Split
Shuffle Splitの各イテレーションで、学習データと検証データに同じグループが登場しないようにします。
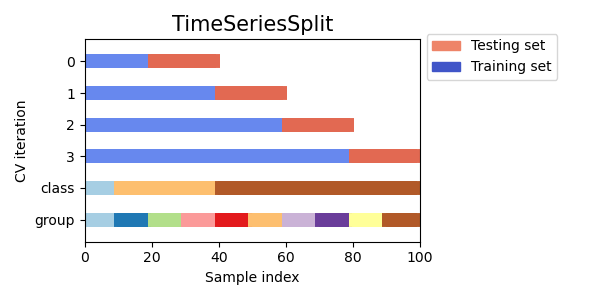
Time Series Split
時系列データ用の交差検証イテレータです。学習期間終了日の翌データを検証データとし、イテレーション毎に学習期間を増やしていきます。
交差検証関数
交差検証を行う関数は下記3つに分類されます。
| 評価数 | |||
|---|---|---|---|
| 単一指標 | 複数指標 | ||
| 返り値 | 指標 | cross_val_score | cross_validate |
| 指標+予測値 | cross_val_predict |
パラメータチューニング
ハイパーパラメータを探索する方法は下記3方法があります。
| モジュール | 方法 | 概要 |
|---|---|---|
| GridSearchCV | グリッドサーチ | パラメータ候補を網羅的に探索 |
| RandomizedSearchCV | ランダムサーチ | パラメータをランダムに探索 |
| LogisticRegressionCV | Estimator固有のサーチ | ロジスティック回帰に特化した探索 |
| LassoCV | Estimator固有のサーチ | Lasso回帰に特化した探索 |
| RidgeCV | Estimator固有のサーチ | Ridge回帰に特化した探索 |
さいごに
最後まで読んで頂き、ありがとうございました。
今回はモデル評価に焦点を当てて整理しました。
訂正要望がありましたら、ご連絡頂けますと幸いです。