- 製造業出身のデータサイエンティストがお送りする記事
- 今回は普段使っているscikit-learn の機能(モデル構築)について整理してみました。自分用のメモです。
はじめに
普段からscikit-learn を使用しているのですが、規模が大き過ぎて必要な部分は毎回ググリなら実装しておりますので、勉強も兼ねて整理してみました。
モデル構築
モデル構築において下記3点について調査しました。
- estimator(学習器)
- meta-estimator(メタ学習器)
- transformer(変換器)
estimator(学習器)
estimator は、データを受け取って何かを予測するために使用するクラスです。
基本的に使うメソッドは下記2点です。
- fit メソッド
- predict メソッド
また、estimator は、主に下記3つのタスクに分類されます。
- classifier(分類器)
- regressor(回帰器)
- culster(クラスタリング器)
また、具体的なestimator はscikit-learn がチートシートを作ってくれておりますので、これを参照して選択するのが良いと思います。
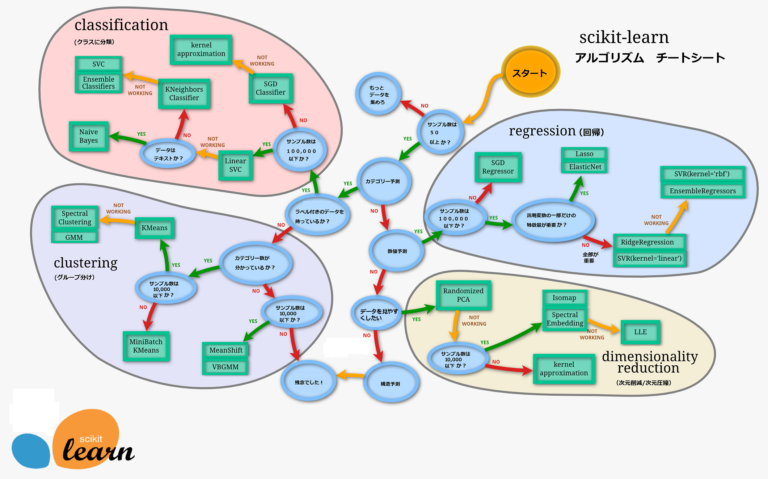
estimator を持つモジュール一覧
細かい内容までは全て整理しておりませんが、estimator を持つモジュールを下記に整理してみました。
| 分類 | 概要 | モジュール名 |
|---|---|---|
| 教師あり学習 | 判別分析 | discriminant_analysis |
| ランダムフォレスト等のアンサンブル学習 | ensemble | |
| ガウス過程 | gaussian_proces | |
| 単調回帰 | isotonic | |
| カーネル近似 | kernel_approximation | |
| カーネルリッジ回帰 | kernel_ridge | |
| 一般化線形モデル | linear_model | |
| ナイーブベイズ分類器 | naive_bayes | |
| 近傍法 | neighbors | |
| ニューラルネットワーク | neural_network | |
| サポートベクターマシーン | svm | |
| 決定木 | tree | |
| 半教師あり学習 | semi_supervised | |
| 教師なし学習 | クラスタリング | cluster |
| 混合ガウス分布 | mixture |
estimator のメソッドと継承先のクラス
代表的な3つのestimator が実装しているメソッドと継承先のクラスを下記に整理しております。
| クラス | classifier | regressor | cluster |
|---|---|---|---|
| 用途 | 分類 | 回帰 | クラスタリング |
| メソッド | fit predict scoer |
fit predict scoer |
fit predict |
meta-estimator(メタ学習器)
meta-estimator は、estimator をパラメータとして取るestimator です。
estimator に対して、新たな振る舞いを追加したり、複数のestimator を束ねたりすることができます。
代表的なmeta-estimator は下記4つです。
- アンサンブル学習器
- マルチクラス・マルチラベル学習器
- マルチアウトプット学習器
- キャリブレーション学習器
アンサンブル学習器
複数のestimator を束ねて一つのestimator を作成します。
具体的なモジュールを下記に記載します。
| モジュール | 概要 |
|---|---|
| AdaBoostClassifier AdaBoostRegressor |
弱学習器の重みを損失関数の最適化により求めます |
| BaggingClassifier BaggingRegressor |
弱学習器の重みを等価として扱います |
| GradientBoostingClassifier GradientBoostingRegressor |
勾配ブースティング法による弱学習器の重みを確率的勾配降下法で求めます |
マルチクラス・マルチラベル学習器
二値分類のestimator をマルチクラス・マルチラベルの分類に適用させます。
具体的なモジュールを下記に記載します。
| モジュール | 概要 |
|---|---|
| OneVsRestClassifier | ある特定のクラスに入るか、他のK−1 個のクラスのどれかに入るかの2クラス分類問題を解く分類器をK 個利用する |
| OneVsOneClassifier | ある特定のクラスに入るか、また別の特定のクラスに入るかの2クラス分類問題を解く分類器をK(K−1)/2 個利用する |
| OutputCodeClassifier | 様々な組合せでクラスを2グループに分割し、各組合せ毎に2値分類を行い、その結果を集計して所属クラスを決定する |
| ClassifierChain | マルチラベル専用 |
マルチアウトプット学習器
単一目的変数を取るestimator を複数の目的変数を取るestimator に変換します。
具体的なモジュールを下記に記載します。
| モジュール | 概要 |
|---|---|
| MulitiOutputClassifier MulitiOutputRegressor |
目的変数の次元だけestimator を作り、それらの予測値を並べる |
キャリブレーション学習器
クラスへの所属確率を返さないclassifier を返すように変換します。
ROC 曲線を書く時などに重宝します。
具体的なモジュールを下記に記載します。
| モジュール | 概要 |
|---|---|
| CalibrationClassifierCV | クラスへの所属確率を返すようなestimator を生成します |
以上、4つを整理しましたが後半の2個(マルチアウトプット学習器、キャリブレーション学習器)は使ったことありませんでした。
transformer(変換器)
データに変換を施すためのオブジェクトです。主に前処理として使用します。
代表的なtransformer は下記です。
- 次元削除
- スケーリング
- カテゴリコーディング
- 特徴量選択
- 特徴量抽出
次元削減
行列の分解によって特徴量を圧縮します。
sklearn.decomposition に存在する具体的なモジュールを下記に記載します。
| モジュール | 概要 |
|---|---|
| PCA | 主成分分析 |
| IncrementalPCA | 逐次処理が可能な主成分分析 |
| KernelPCA | カーネル関数を利用した主成分分析 |
| SparsePCA | 出力が疎行列になる主成分分析 |
| NMF | 非負値行列因子分解 |
| TruncatedSVD | 特異値分解 |
| LatentDirichletAllocation | LDA(潜在的ディリクレ配分法) |
高次元空間内に多様体やグラフ表現を発見することで次元を削減します。
sklearn.manifold に存在する具体的なモジュールを下記に記載します。
| モジュール | 概要 |
|---|---|
| TSNE | t-SNE |
| LocallyLinearEmbedding | 局所的な測地線上の距離を保存するように次元縮約 |
| MDS | 多次元尺度構成法 |
| Isomap | Isomap |
| SpectralEmbedding | 点群全体のグラフ表現を縮約 |
高次元から低次元への写像の行列の値をランダムに選んでも距離構造が失われる確率が低いという知見に元に圧縮します。
sklearn.random_projection に存在する具体的なモジュールを下記に記載します。
| モジュール | 概要 |
|---|---|
| GaussianRandomProjection | 写像行列の値をガウス分布に基づいて決定します |
| SpareseRandomProjection | 写像行列の値をランダムな疎行列とします |
スケーリング
データのスケール変換。
sklearn.preprocessing に存在する具体的なモジュールを下記に記載します。
| モジュール | 概要 |
|---|---|
| StandardScaler | 標準化 |
| MinMaxScaler | 最小値:0、最大値:1になるように変換 |
| RobustScaler | 指定した分位数の範囲内のデータだけから計算した統計量で標準化 |
| Nomalizer | ベクトルの長さが1になるように正規化 |
カテゴリコーディング
カテゴリ値を数値に変換します。
具体的なモジュールを下記に記載します。
| モジュール | 概要 |
|---|---|
| LabelEncoder | カテゴリ値に整数値を割り当てる |
| get_dummies | カテゴリ値をダミー変数に変換 |
| OneHotEncoder | カテゴリ値をOneHot表現に変換 |
| TargetEncoder | カテゴリ値をそのカテゴリを持つサンプルが正解ラベルを含む確率に変換 |
特徴量選択
特徴量を特定の基準に則って選択します。
具体的なモジュールを下記に記載します。
| モジュール | 概要 |
|---|---|
| SelectKBest | 目的変数との関係性が高い特徴量を上位k個選択 |
| SelectPercentile | 目的変数との関係性が高い特徴量を上位k%選択 |
| RFE | モデル推定→重要度算出→重要度の低い特徴量を排除という操作を再起t形に繰り返し、指定した個数の特徴量だけを選択する |
| RFECV | 交差検証によって汎化性能を高めたRFE |
| SelectFromModel | モデル推定によって特徴量を選択する |
特徴量と目的変数との関係性を算出する指標。
具体的なモジュールを下記に記載します。
| モジュール | 概要 |
|---|---|
| khi2 | 特徴量と目的変数の独立性の検定を行う |
| f_classif f_regression |
目的変数を水準とする分散分析を行う |
| mutual_info_classif mutual_info_regression |
特徴量と目的変数の相互情報量を算出する |
特徴量抽出
画像やテキスト等の非構造データから特徴量を抽出します。
具体的なモジュールを下記に記載します。
| モジュール | 概要 |
|---|---|
| CountVectorizer | 文書を単語の出現数のベクトルに変換します |
| TfidfVectorizer | 文書をTF-IDF ベクトルに変換します |
| HashingVectorizer | 文書をハッシュベクトルに変換します |
| extract_pathches_2d | 画像をバッチに変換します |
さいごに
最後まで読んで頂き、ありがとうございました。
続きは時間がありましたら整理してみようと思います。
とりあえず、知らない機能がたくさんあったので実際に使ってみようと思います。
訂正要望がありましたら、ご連絡頂けますと幸いです。