- 製造業出身のデータサイエンティストがお送りする記事
- 今回は普段の業務で頻繁に遭遇する欠損値の処理方法について整理してみました。
はじめに
欠損値の発生メカニズムについて下記に整理します。詳細は割愛しますが、3つに分類できます。
- MCAR(Missing Completely At Random)
- ある値の欠損する確率がデータと全く関係なく、完全にランダムに欠損している事を指します
- つまり、欠損値が完全にランダムに生じているようなケースです。
- MAR(Missing At Random)
- ある値が欠損する確率が観測されたデータで条件付けるとランダムになる事を指します
- MNAR(Missing Not At Random)
- ある値が欠損する確率が欠損データ自体に依存している事を指します
欠損値があった場合はまず、なぜ欠損値が発生しているのかをきちっと見極めてから欠損値処理を行うことが重要です。
欠損値の処理方法について
今回はタイタニック号のデータを対象に様々な欠損値補完方法を試してみたいと思います。
まずはデータを取得してタイタニック号のデータを見てみます。
# ライブラリーのインポート
import pandas as pd
import numpy as np
import random as rnd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.ensemble import GradientBoostingRegressor
import warnings
warnings.simplefilter('ignore')
# データの読み込み(タイタニックデータ)
df = pd.read_csv('../data/train.csv')
df.head()
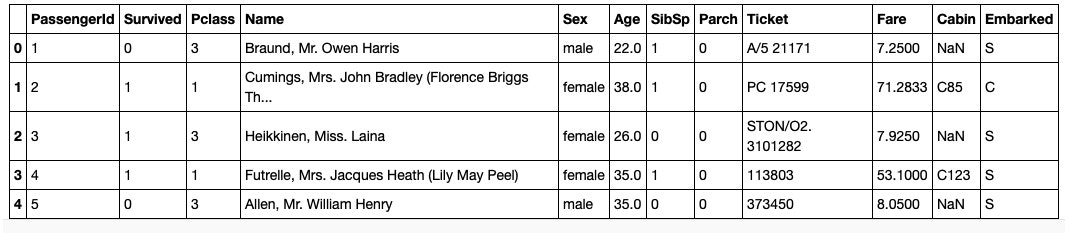
次にデータの基本情報を確認します。
# データの基本情報を確認
df.info()

Age, Cabin, Embarkedに欠損値があることが分かりますね。
上記だと欠損値が何個あるのか分からないため、再度欠損値について確認してみます。
# 欠損値の確認
df.isnull().sum()

今回は、欠損値の処理方法について確認するため、不要なカラムを削除して欠損値処理が確認しやすいようにカラム数を削減します。
# 性別の数値変換
df.loc[(df['Sex'] == 'male'), 'Sex'] = 0
df.loc[(df['Sex'] == 'female'), 'Sex'] = 1
# 不要なカラムの削除
df = df.drop(['Name',
'Cabin',
'Ticket',
'SibSp',
'Parch',
'Embarked',
'Fare'],
axis=1)
df.head(10)
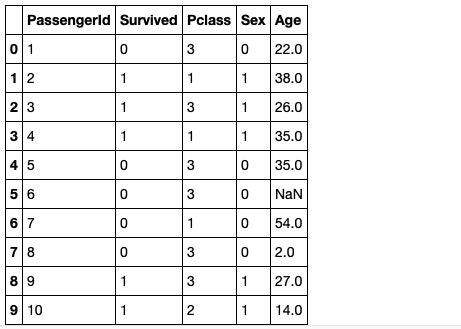
6行目のAgeがNaNで欠損していることが分かりますね。
以下で様々な欠損値処理方法を試してみたいと思います。
リストワイズ法
欠損値のサンプルを削除してしまう方法です。
df_listwise = df.dropna()
df_listwise.head(10)
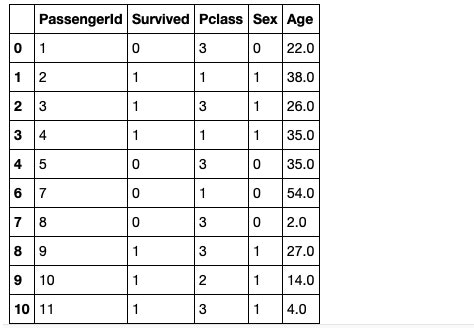
先ほど存在していた6行目の欠損サンプルが削除されております。
単一代入法
次は欠損値部分に一つの値を代入する方法について試してみます。
平均値補完
平均値で欠損値を補完します。
mean = df.mean()
df_mean = df.fillna(mean)
df_mean.head(10)
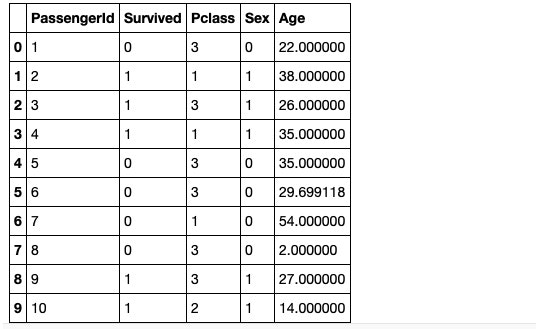
6行目のAgeが29.699118で補完されております。これがAgeの平均値であり、全ての欠損値を平均値で補完しております。
中央値補完
次は中央値で欠損値を補完します。
median = df.median()
df_median = df.fillna(median)
df_median.head(10)
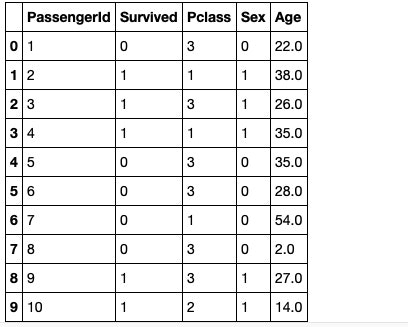
6行目のAgeが28.0で補完されております。これがAgeの中央値であり、全ての欠損値を中央値で補完しております。
回帰代入法(GBDT)
次は欠損値があるカラム(今回はAge)を目的変数として、回帰モデルを構築して欠損値を補完する方法です。
df_master = df.dropna()
df_miss = df[df.isnull().any(axis=1)]
model = GradientBoostingRegressor().fit(df_master.drop(["Age","Survived"], axis=1), df_master["Age"])
df_miss["Age"] = model.predict(df_miss.drop(["Age","Survived"], axis=1))
df_GBDT = pd.concat([df_master, df_miss]).sort_index()
df_GBDT.head(10)
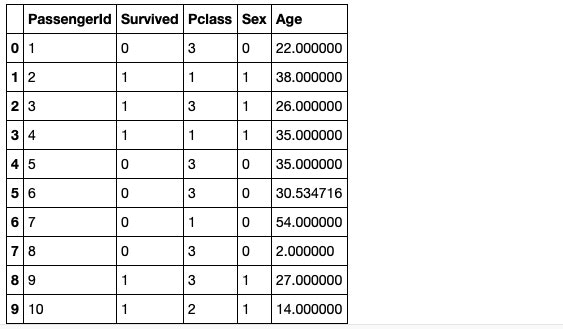
6行目のAgeが30.534716で補完されております。これはAgeを目的変数とし、説明変数に「Passengerld, Pclass, Sex」を使用してGBDTで回帰モデルを構築した上で6行目のAgeを予測した結果で欠損値を補完しております。
IterativeImputerによる代入法
ここからは、ライブラリーを使用した欠損値補完方法について整理します。最初は、多変量データセットへの代入に使用する方法です。
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
imp = IterativeImputer(max_iter=10, random_state=1)
df_IterativeImputer = pd.DataFrame(imp.fit_transform(df))
df_IterativeImputer.columns = df.columns
df_IterativeImputer.head(10)
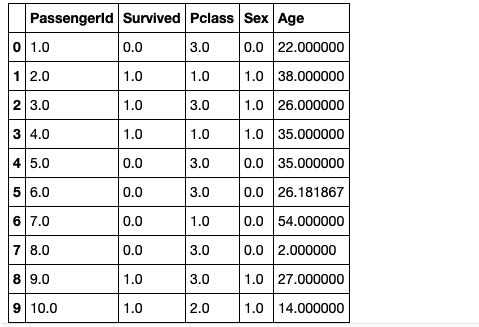
6行目のAgeが26.181867で補完されております。細かい補完ロジックについては今回は省略します。
KNNImputerによる代入法(K近傍法)
次はK近傍法による欠損値の補完方法です。
from missingpy import KNNImputer
imp = KNNImputer(n_neighbors=2, weights='uniform')
df_KNN = pd.DataFrame(imp.fit_transform(df))
df_KNN.columns = df.columns
df_KNN.head(10)
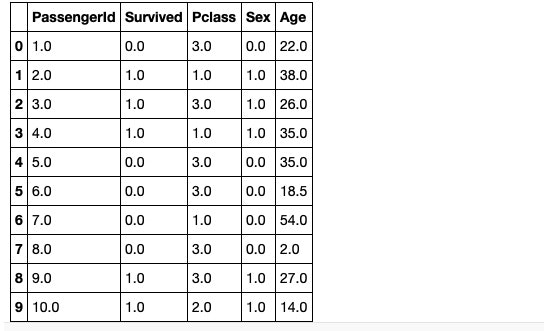
6行目のAgeが18.5で補完されております。細かい補完ロジックについては今回は省略しますが、K近傍法を活用した欠損値補完を行っております。
MissForestによる代入法(ランダムフォレスト)
最後はランダムフォレストを活用した欠損値補完方法です。
from missingpy import MissForest
imp = MissForest(max_iter=10)
df_MF = pd.DataFrame(imp.fit_transform(df))
df_MF.columns = df.columns
df_MF.head(10)
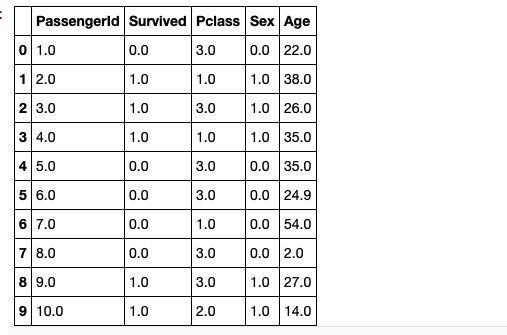
6行目のAgeが24.9で補完されております。細かい補完ロジックについては今回は省略しますが、ランダムフォレストを活用した欠損値補完を行っております。
さいごに
最後まで読んで頂き、ありがとうございました。
欠損値の処理方法について一部ですが整理してみました。欠損値補完方法によって結果が全然違いました。実際の業務で欠損値を扱う際は、発生メカニズムを確認し、その上で適切な方法で欠損値処理を行うようにしようと思います。
訂正要望がありましたら、ご連絡頂けますと幸いです。