はじめに
最近、『tensorflowで学ぶ機械学習・ニューラルネットワーク』という本を見ながらTensorflowの勉強をしています。本の中で偽のデータを使って線形回帰をしていたのですが「それじゃつまらない!!」と思い、生のデータを使って線形回帰をしました。この記事ではデータの集め方とどのようにしてやったのかを書きました。まだ中学3年で難しい数学がわからないので、その式がどのように働いているかを自分なりに解釈しました。また、まだ初心者ですので間違いなどがあったらコメントでお願いします!!初投稿です!
データ集め
気象庁の過去のデータを見ることができるサイトがあったのでこれを利用しようと考えました。その中の項目に蒸気圧というのがありWikipediaによると「温度を上げると蒸気圧が上がり、蒸気の分圧より大きくなる。」と書いてありました。なので蒸気圧と温度は線形回帰に使えるデータではないかと思いこれを使うことにしました。
1:まず最初に地点を横浜、項目を日平均気温と日平均蒸気圧、期間を2018年の4月1日から2019年の4月1日に設定しま す。
2:csvファイルをダウンロードしたらExcelでデータを取りやすくするためにタイトルと日付を削除します。そして名前を"data_yokohama.csv"として保存します。
3:必要なライブラリ(tensorflow, numpy, matplotlib, csv)をインポートします
4:次にコードでcsvからデータを読み込む処理を書きます。
vapor_sub = []
temperature_sub = []
def load_data(f): # csvからデータを読み込む関数を作成
reader = csv.reader(f)
for i, row in enumerate(reader):
if row[0] == "" or row[1] == "": # もしその行に何も入ってない場合は飛ばす
continue
else:
vapor_sub.append(np.float32(row[0]))
temperature_sub.append(np.float32(row[1]))
with open("data_yokohama.csv", "r") as f:
load_data(f)
row[0]に蒸気圧、row[1]に気温が入ってるのでそれぞれvapor_sub(蒸気圧のリスト)、temperature_sub(気温のリスト)に追加します。
5:次に取得した値を少数第二位で四捨五入し、型をndarrayにします。
vapor = np.round(np.array(vapor_sub), decimals=1)
temperature = np.round(np.array(temperature_sub), decimals=1)
これでデータ集めは終わりました!
線形回帰
まず最初に学習率と訓練回数を定義します。
learning_rate = 0.001
train_epochs = 100
次に学習する際訓練データを当てはめていくプレースホルダーを気温をX、蒸気圧をYと定義します。
変数としてパラメーターをw、バイアスをbと定義します。
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
b = tf.Variable(0., tf.float32)
w = tf.Variable(0., tf.float32)
そして次にモデル、コスト、計算グラフを定義します。
def model(X, w, b):
return X * w + b
y_model = model(X, w, b)
cost = tf.reduce_mean(tf.square(Y - y_model))
train_op = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
ここからは少し自分的な解釈になってしまうのですが、ここで何をしているかを説明しようと思います。
まずモデルですが蒸気圧と気温は比例関係ということがなんとなくわかっています。つまり二つの関係を表すには一次関数が最も適切であり、X * w + bとすることで学習した結果が切片b傾きwの関係になるように定義しているのです。
次にコストですがtf.squareというのは()内を二乗する関数で、tf.reduce_meanというの()内のリストの平均を求める関数です。Yというのは取得した本当のデータであり正解であり、y_modelというのはその時点での予測した値です。その差を求めることでその時点での予想と実際のデータがどのぐらい離れているか、つまり誤差を求めています。そしてその誤差をwやbの値を調節することで最小にすることで実際の値に予想が近づき最終的に予想できるようになるのです。
なぜ誤差を二乗しているのかというと二乗することでy = X ** 2の式ができ二次関数になります。二次関数で嬉しいことは勾配法が適用できます。勾配法というのは誤差を小さくしていく方法です。詳しく説明すると微分という方法を使うことでその点における接線の傾きを求めることができます。誤差が最も小さい時というのは二次関数における頂点になります。頂点の接戦の傾きは0になり、頂点に近づくにつれ傾きが小さくなります。なので点を動かして接戦の傾きが小さくなる方に動かすことで頂点を求めることができるのです。またなぜtf.reduce_meanで平均を求める必要があるのかというのは一つ一つの値を取り出して学習することはできるのですが、平均を使うことで全てのデータをまとめて学習することができるので時間を短縮することができるのです。
そして学習率というのはwやbを更新する時一度に大きく更新してしまうと最小の位置を通り越したりしてしまい正確にできないのです。小さく更新することでより正確な値を求めることができます。次のgifは学習を可視化したものです。
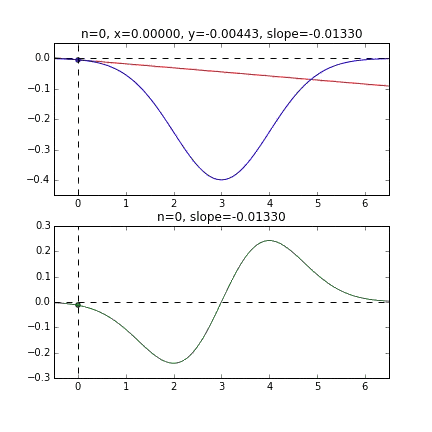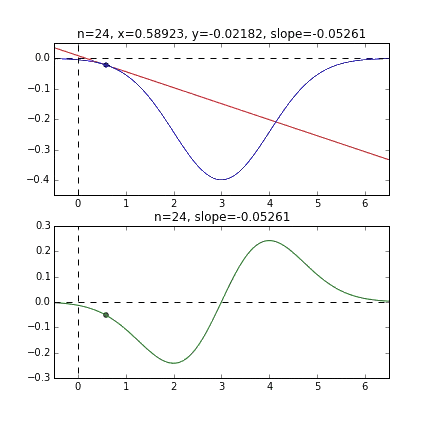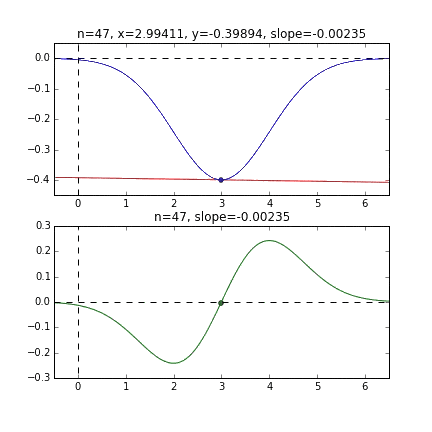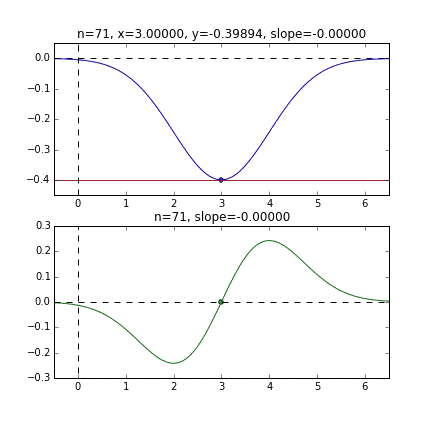
https://qiita.com/kenmatsu4/items/d282054ddedbd68fecb0より引用
次に忘れてはいけないのが変数の初期化です。
init = tf.global_variables_initializer()
sess.run(init)
ここで計算グラフの実行をします。
for epoch in range(train_epochs):
error, _ = sess.run([cost, train_op], feed_dict={X: temperature, Y: vapor})
Xに気温をYに蒸気圧を代入し学習を指定した回数だけ行います。
errorの値はその時点での誤差です。
print(error)
としてあげると誤差がどんどん減ってくのがわかると思います。
w_value, b_value = sess.run([w, b])
そしてこれを行うことでw_valueに学習したwの値が、b_valueに学習したbの値が代入されます。
そして最後に結果をmatplotlibでplotします。
y_learned = temperature * w_value + b_value
plt.plot(temperature, y_learned)
plt.scatter(temperature, vapor, c="r", marker="x", s=20)
plt.tick_params(labelbottom=False, labelleft=False)
plt.tick_params(bottom=False, length=False)
plt.show()
その結果がこれです。

おお!
感動しますね。きれいにグラフがプロットされてます!
「蒸気圧と温度の関係なんて需要がない」、「無駄」と思われた方もいると思いますが自分としては練習になったなと思います。
コード(全体)
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import csv
vapor_sub = []
temperature_sub = []
def load_data(f):
reader = csv.reader(f)
for i, row in enumerate(reader):
if row[0] == "" or row[1] == "":
continue
else:
vapor_sub.append(np.float32(row[0]))
temperature_sub.append(np.float32(row[1]))
with open("data_yokohama.csv", "r") as f:
load_data(f)
vapor = np.round(np.array(vapor_sub), decimals=1)
temperature = np.round(np.array(temperature_sub), decimals=1)
learning_rate = 0.001
train_epochs = 100
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
b = tf.Variable(0., tf.float32)
w = tf.Variable(0., tf.float32)
def model(X, w, b):
return X * w + b
y_model = model(X, w, b)
cost = tf.reduce_mean(tf.square(y_model - Y))
train_op = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
sess = tf.InteractiveSession()
init = tf.global_variables_initializer()
sess.run(init)
for epoch in range(train_epochs):
error, _ = sess.run([cost, train_op], feed_dict={X: temperature, Y: vapor})
print(epoch, error)
w_value, b_value = sess.run([w, b])
sess.close()
print(w_value)
print(b_value)
def humidity_data(temperature):
return temperature * w_value + b_value
print(humidity_data(20))
y_learned = humidity_data(temperature)
plt.plot(temperature, y_learned)
plt.scatter(temperature, vapor, c="r", marker="x", s=20)
plt.tick_params(labelbottom=False, labelleft=False)
plt.tick_params(bottom=False, length=False)
plt.show()
最後に
かなり稚拙な文章になってしまいましたが読んでいただきありがとうございました!
まだ初心者ですのでコメントからどんどんアドバイスお願いします!