はじめに
RepVGGで使用されているre-parameterizationを,PyTorchを使用して実際に計算して確認してみました
実装はImplementing RepVGG in PyTorchを参考にしました
RepVGG
RepVGGは,推論時はVGGのように3×3convとReLUのみのbodyを持ち,訓練時にはMulti-branchのトポロジーを持ちます
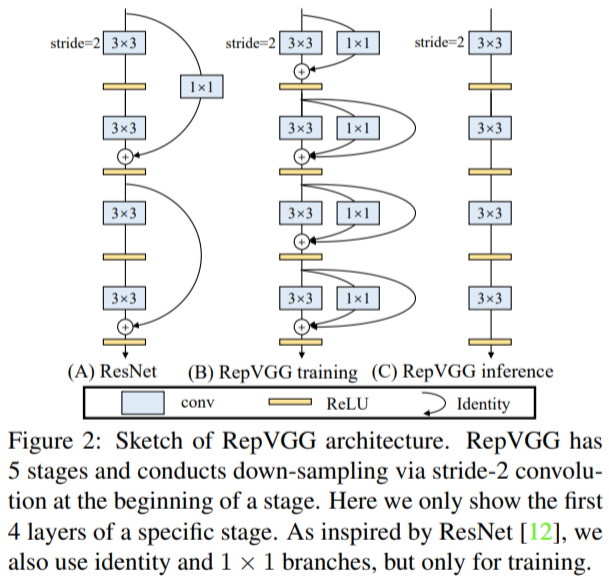
この推論時と訓練時のアーキテクチャの分離は,re-parameterizationテクニックを用いることで実現されています

各re-parameterizationについて以下の順に見ていきます
- (3つの3x3 conv + 各結果の加算) → 3x3 convへのre-parameterization
- (3x3 conv + BN) → 3x3 convへのre-parameterization
- (1x1 conv + BN) → 3x3 convへのre-parameterization
- (identity + BN) → 3x3 convへのre-parameterization
1. (3つの3x3 conv + 各結果の加算) → 3x3 convへのre-parameterization
↓この部分です

2つも3つも一緒なので,(2つの3x3 conv + 各結果の加算) → 3x3 convへのre-parameterizationを確認します
全体のコード
import torch
from torch import nn, Tensor
with torch.no_grad():
# 入力画像
feature_map = torch.ones((1, 2, 7, 7)) # BCHW
feature_map[:, 1, :, :] = 2
print('feature_map')
print(feature_map)
conv1 = nn.Conv2d(2,2,kernel_size=3, padding=1, bias=True)
conv1.weight.fill_(1)
conv1.bias.fill_(10)
print('conv1.weight')
print(conv1.weight)
print('conv1.bias')
print(conv1.bias)
conv2 = nn.Conv2d(2,2,kernel_size=3, padding=1, bias=True)
conv2.weight.fill_(2)
conv2.bias.fill_(20)
print('conv2.weight')
print(conv2.weight)
print('conv2.bias')
print(conv2.bias)
conv_fused = nn.Conv2d(conv1.in_channels, conv1.out_channels, kernel_size=conv1.kernel_size, padding=1)
conv_fused.weight = nn.Parameter(conv1.weight + conv2.weight)
conv_fused.bias = nn.Parameter(conv1.bias + conv2.bias)
print('conv_fused.weight')
print(conv_fused.weight)
print('conv_fused.bias')
print(conv_fused.bias)
print('conv1(feature_map)+conv2(feature_map)')
print(conv1(feature_map)+conv2(feature_map))
print('conv_fused(feature_map)')
print(conv_fused(feature_map))
入力特徴マップの生成
C=2とします
with torch.no_grad():
# 入力画像
feature_map = torch.ones((1, 2, 7, 7)) # BCHW
feature_map[:, 1, :, :] = 2
print('feature_map')
print(feature_map)
feature_map
tensor([[[[1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1.]],
[[2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2.]]]])
2つの3x3 convを定義
conv1 = nn.Conv2d(2,2,kernel_size=3, padding=1, bias=True)
conv1.weight.fill_(1)
conv1.bias.fill_(10)
print('conv1.weight')
print(conv1.weight)
print('conv1.bias')
print(conv1.bias)
conv2 = nn.Conv2d(2,2,kernel_size=3, padding=1, bias=True)
conv2.weight.fill_(2)
conv2.bias.fill_(20)
print('conv2.weight')
print(conv2.weight)
print('conv2.bias')
print(conv2.bias)
conv1.weight
Parameter containing:
tensor([[[[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]]],
[[[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]]]], requires_grad=True)
conv1.bias
Parameter containing:
tensor([10., 10.], requires_grad=True)
conv2.weight
Parameter containing:
tensor([[[[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.]],
[[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.]]],
[[[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.]],
[[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.]]]], requires_grad=True)
conv2.bias
Parameter containing:
tensor([20., 20.], requires_grad=True)
1つの3✕3 convに変換
conv_fused = nn.Conv2d(conv1.in_channels, conv1.out_channels, kernel_size=conv1.kernel_size, padding=1)
conv_fused.weight = nn.Parameter(conv1.weight + conv2.weight)
conv_fused.bias = nn.Parameter(conv1.bias + conv2.bias)
print('conv_fused.weight')
print(conv_fused.weight)
print('conv_fused.bias')
print(conv_fused.bias)
conv_fused.weight
Parameter containing:
tensor([[[[3., 3., 3.],
[3., 3., 3.],
[3., 3., 3.]],
[[3., 3., 3.],
[3., 3., 3.],
[3., 3., 3.]]],
[[[3., 3., 3.],
[3., 3., 3.],
[3., 3., 3.]],
[[3., 3., 3.],
[3., 3., 3.],
[3., 3., 3.]]]], requires_grad=True)
conv_fused.bias
Parameter containing:
tensor([30., 30.], requires_grad=True)
計算結果の確認
print('conv1(feature_map)+conv2(feature_map)')
print(conv1(feature_map)+conv2(feature_map))
print('conv_fused(feature_map)')
print(conv_fused(feature_map))
conv1(feature_map)+conv2(feature_map)
tensor([[[[ 66., 84., 84., 84., 84., 84., 66.],
[ 84., 111., 111., 111., 111., 111., 84.],
[ 84., 111., 111., 111., 111., 111., 84.],
[ 84., 111., 111., 111., 111., 111., 84.],
[ 84., 111., 111., 111., 111., 111., 84.],
[ 84., 111., 111., 111., 111., 111., 84.],
[ 66., 84., 84., 84., 84., 84., 66.]],
[[ 66., 84., 84., 84., 84., 84., 66.],
[ 84., 111., 111., 111., 111., 111., 84.],
[ 84., 111., 111., 111., 111., 111., 84.],
[ 84., 111., 111., 111., 111., 111., 84.],
[ 84., 111., 111., 111., 111., 111., 84.],
[ 84., 111., 111., 111., 111., 111., 84.],
[ 66., 84., 84., 84., 84., 84., 66.]]]])
conv_fused(feature_map)
tensor([[[[ 66., 84., 84., 84., 84., 84., 66.],
[ 84., 111., 111., 111., 111., 111., 84.],
[ 84., 111., 111., 111., 111., 111., 84.],
[ 84., 111., 111., 111., 111., 111., 84.],
[ 84., 111., 111., 111., 111., 111., 84.],
[ 84., 111., 111., 111., 111., 111., 84.],
[ 66., 84., 84., 84., 84., 84., 66.]],
[[ 66., 84., 84., 84., 84., 84., 66.],
[ 84., 111., 111., 111., 111., 111., 84.],
[ 84., 111., 111., 111., 111., 111., 84.],
[ 84., 111., 111., 111., 111., 111., 84.],
[ 84., 111., 111., 111., 111., 111., 84.],
[ 84., 111., 111., 111., 111., 111., 84.],
[ 66., 84., 84., 84., 84., 84., 66.]]]])
同じ計算結果になりました
2. (3x3 conv + BN) → 3x3 convへのre-parameterization
M: 特徴マップ
μ, σ, γ, β: BNのパラメータ
とすると

のようになります
↓実装を見たほうが分かりやすいと思います
全体のコード
import torch
from torch import nn, Tensor
with torch.no_grad():
feature_map = torch.empty((1, 2, 7, 7))
feature_map[:, 0, :, :] = 50
feature_map[:, 1, :, :] = torch.arange(50, 99).reshape(1, 7, 7)
print('feature_map')
print(feature_map)
bn = nn.BatchNorm2d(2)
bn.running_mean.fill_(5)
bn.running_var.fill_(100)
bn.weight.fill_(5)
bn.bias.fill_(20)
bn.eval()
print('bn.running_mean(mean)')
print(bn.running_mean)
print('bn.running_var(std^2)')
print(bn.running_var)
print('bn.weight(gamma)')
print(bn.weight)
print('bn.bias(beta)')
print(bn.bias)
# (50-5)*(5/10) + 20 = 45 * (1/2) + 20 = 42.5
print('bn(feature_map)')
print(bn(feature_map))
conv = nn.Conv2d(2, 2,kernel_size=3, padding=1, bias=True)
print('bn(conv(feature_map))')
print(bn(conv(feature_map)))
bn_std = (bn.running_var + bn.eps).sqrt()
conv_weight = nn.Parameter((bn.weight / bn_std).reshape(-1, 1, 1, 1) * conv.weight) # conv.weightは(C_out, C_in, H, W)
conv_bias = nn.Parameter(bn.bias - bn.running_mean * bn.weight / bn_std)
conv_fused = nn.Conv2d(conv.in_channels, conv.out_channels, kernel_size=conv.kernel_size, padding=1)
conv_fused.load_state_dict({'weight': conv_weight, 'bias':conv_bias})
print('conv_fused(feature_map)')
print(conv_fused(feature_map))
入力特徴マップの生成
値は適当です
import torch
from torch import nn, Tensor
with torch.no_grad():
feature_map = torch.empty((1, 2, 7, 7))
feature_map[:, 0, :, :] = 50
feature_map[:, 1, :, :] = torch.arange(50, 99).reshape(1, 7, 7)
print('feature_map')
print(feature_map)
feature_map
tensor([[[[50., 50., 50., 50., 50., 50., 50.],
[50., 50., 50., 50., 50., 50., 50.],
[50., 50., 50., 50., 50., 50., 50.],
[50., 50., 50., 50., 50., 50., 50.],
[50., 50., 50., 50., 50., 50., 50.],
[50., 50., 50., 50., 50., 50., 50.],
[50., 50., 50., 50., 50., 50., 50.]],
[[50., 51., 52., 53., 54., 55., 56.],
[57., 58., 59., 60., 61., 62., 63.],
[64., 65., 66., 67., 68., 69., 70.],
[71., 72., 73., 74., 75., 76., 77.],
[78., 79., 80., 81., 82., 83., 84.],
[85., 86., 87., 88., 89., 90., 91.],
[92., 93., 94., 95., 96., 97., 98.]]]])
BNの定義
BNのパラメータも適当です
bn = nn.BatchNorm2d(2)
bn.running_mean.fill_(5)
bn.running_var.fill_(100)
bn.weight.fill_(5)
bn.bias.fill_(20)
bn.eval()
print('bn.running_mean(mean)')
print(bn.running_mean)
print('bn.running_var(std^2)')
print(bn.running_var)
print('bn.weight(gamma)')
print(bn.weight)
print('bn.bias(beta)')
print(bn.bias)
bn.running_mean(mean)
tensor([5., 5.])
bn.running_var(std^2)
tensor([100., 100.])
bn.weight(gamma)
Parameter containing:
tensor([5., 5.], requires_grad=True)
bn.bias(beta)
Parameter containing:
tensor([20., 20.], requires_grad=True)
3×3 convの定義と,(3x3 conv + BN) → 3x3 convへのre-parameterization

conv = nn.Conv2d(2, 2,kernel_size=3, padding=1, bias=True)
bn_std = (bn.running_var + bn.eps).sqrt()
conv_weight = nn.Parameter((bn.weight / bn_std).reshape(-1, 1, 1, 1) * conv.weight) # conv.weightは(C_out, C_in, H, W)
conv_bias = nn.Parameter(bn.bias - bn.running_mean * bn.weight / bn_std)
conv_fused = nn.Conv2d(conv.in_channels, conv.out_channels, kernel_size=conv.kernel_size, padding=1)
conv_fused.load_state_dict({'weight': conv_weight, 'bias':conv_bias})
計算結果の確認
print('bn(conv(feature_map))')
print(bn(conv(feature_map)))
print('conv_fused(feature_map)')
print(conv_fused(feature_map))
bn(conv(feature_map))
tensor([[[[16.5714, 11.5451, 11.5955, 11.6459, 11.6962, 11.7466, 0.4305],
[22.4148, 25.0118, 25.1873, 25.3628, 25.5383, 25.7137, 7.3858],
[23.3898, 26.2402, 26.4156, 26.5911, 26.7666, 26.9421, 7.1664],
[24.3649, 27.4685, 27.6440, 27.8194, 27.9949, 28.1704, 6.9471],
[25.3400, 28.6968, 28.8723, 29.0478, 29.2233, 29.3987, 6.7278],
[26.3150, 29.9252, 30.1006, 30.2761, 30.4516, 30.6271, 6.5084],
[37.5233, 48.5330, 48.7859, 49.0389, 49.2918, 49.5448, 30.5362]],
[[13.3822, 3.0390, 2.9962, 2.9534, 2.9106, 2.8678, 7.3584],
[17.7679, 6.5199, 6.5464, 6.5729, 6.5994, 6.6260, 4.8348],
[18.6928, 6.7056, 6.7321, 6.7586, 6.7851, 6.8117, 4.6277],
[19.6176, 6.8913, 6.9178, 6.9443, 6.9709, 6.9974, 4.4205],
[20.5425, 7.0770, 7.1035, 7.1300, 7.1566, 7.1831, 4.2134],
[21.4673, 7.2627, 7.2892, 7.3157, 7.3423, 7.3688, 4.0063],
[35.3246, 30.1079, 30.2486, 30.3892, 30.5299, 30.6705, 15.5543]]]])
conv_fused(feature_map)
tensor([[[[16.6741, 11.6478, 11.6982, 11.7485, 11.7989, 11.8492, 0.5331],
[22.5174, 25.1145, 25.2900, 25.4654, 25.6409, 25.8164, 7.4884],
[23.4925, 26.3428, 26.5183, 26.6938, 26.8692, 27.0447, 7.2691],
[24.4675, 27.5711, 27.7466, 27.9221, 28.0976, 28.2730, 7.0497],
[25.4426, 28.7995, 28.9749, 29.1504, 29.3259, 29.5014, 6.8304],
[26.4177, 30.0278, 30.2033, 30.3788, 30.5542, 30.7297, 6.6111],
[37.6260, 48.6356, 48.8886, 49.1415, 49.3945, 49.6474, 30.6388]],
[[13.4420, 3.0987, 3.0559, 3.0131, 2.9703, 2.9275, 7.4181],
[17.8277, 6.5796, 6.6061, 6.6326, 6.6592, 6.6857, 4.8945],
[18.7525, 6.7653, 6.7918, 6.8184, 6.8449, 6.8714, 4.6874],
[19.6774, 6.9510, 6.9775, 7.0041, 7.0306, 7.0571, 4.4803],
[20.6022, 7.1367, 7.1632, 7.1898, 7.2163, 7.2428, 4.2732],
[21.5270, 7.3224, 7.3489, 7.3755, 7.4020, 7.4285, 4.0661],
[35.3844, 30.1676, 30.3083, 30.4490, 30.5896, 30.7303, 15.6140]]]])
誤差はありますがほぼ同じになっています
3. (1x1 conv + BN) → 3x3 convへのre-parameterization
1×1 conv → 3×3 convに変換すれば後は2と同じです
下の画像のオレンジの部分です

3x3 convの中心に1x1 convのフィルタの値をコピーして,その他の8箇所の重みを0にすれば変換できます
4. (identity + BN) → 3x3 convへのre-parameterization
これもidentity → 3×3のidentity convに変換すれば後は2と同じです
さっきの画像の黄色の部分です
3×3のidentity convについて確認します
畳み込みしても特徴マップの値が変わらない畳み込みです
identity convの実装については
FrancescoSaverioZuppichini/repvgg-8.pyを参考にさせていただきました
全体のコード
import torch
from torch import nn, Tensor
with torch.no_grad():
feature_map = torch.ones((1, 2, 7, 7)) # BCHW
feature_map[:, 1, :, :] = 2
print('feature_map')
print(feature_map)
identity_conv = nn.Conv2d(2,2,kernel_size=3, padding=1, bias=False)
identity_conv.weight.zero_()
in_channels = identity_conv.in_channels
for i in range(in_channels):
identity_conv.weight[i, i % in_channels, 1, 1] = 1
print('identity_conv.weight')
print(identity_conv.weight)
out = identity_conv(feature_map)
print('identity_conv(feature_map)')
print(out)
feature_map
tensor([[[[1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1.]],
[[2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2.]]]])
identity_conv.weight
Parameter containing:
tensor([[[[0., 0., 0.],
[0., 1., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]],
[[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 1., 0.],
[0., 0., 0.]]]], requires_grad=True)
identity_conv(feature_map)
tensor([[[[1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1.]],
[[2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2.]]]])
参考
- RepVGG: Making VGG-style ConvNets Great Again(原論文)
- Implementing RepVGG in PyTorch(実装の参考にしたサイト)
- FrancescoSaverioZuppichini/repvgg-8.py(3×3のidentity convの実装)