Claude APIを使ったAIプロダクト開発 - 基礎編
このコンテンツは、Anthropic が公式に提供している学習コース 「Claude with the Anthropic API」(Anthropic Courses)をベースとしています。コースの内容を日本語で解説しながら、実際のコードとともに学べるように構成しています。
なぜいま Claude API を学ぶのか

Claude を取り巻くプロダクトは、上の図のような階層構造になっています。Claude Code も Claude Cowork も Claude.ai も、すべての土台にあるのは Claude API です。
つまり Claude API を理解することは、Claude エコシステム全体の「共通の基盤」を理解することです。
このコースで得られるのは、大きく2つです。
1. AI を組み込んだアプリを自分で作れるようになる
チャットボットや業務自動化ツールなど、Claude を組み込んだプロダクトをゼロから作れるようになります。API の基礎、ツール連携、エージェント設計、MCP まで一通り押さえられます。
2. Claude Code などのツールを使いこなせるようになる
裏側で何が起きているかが見えると、日々の使い方が「なんとなく動かす」から「狙って動かす」に変わります。プロンプトやツールの設計を、根拠を持って判断できるようになります。
API を学ぶことは、Claude を使った仕事すべての効率を底上げする投資です。
コース概要
Anthropic API を使って Claude をアプリケーションに組み込む方法を、ハンズオン形式で学ぶコースです。単発の API 呼び出しから始まり、マルチターン会話、ツール連携、拡張思考、画像・PDF処理、プロンプトキャッシュ、MCP サーバー開発、エージェント設計パターンまで、AI アプリ構築に必要な知識をひと通りカバーします。
「Claude を使う」から「Claude で作る」へ移行するための、最短ルートです。
前提条件
- Python プログラミングの基礎知識(関数、辞書の基本がわかればOK)
こんな人におすすめ
-
Claude を組み込んだアプリやサービスを作りたい開発者
チャットボット、社内ツール、SaaS への AI 機能追加など、プロダクト開発に直結する知識が手に入ります。 -
Claude Code や MCP をもっと使いこなしたい人
「便利だけど中で何をしているのかよくわからない」状態から抜け出し、ツールの挙動を予測・制御できるようになります。 -
エージェント設計の引き出しを増やしたい人
並列化・チェーン・ルーティングといった設計パターンを、動くコードで理解できます。 -
AI ネイティブな開発スタイルに移行したいエンジニア
従来の Web/バックエンド開発の延長で、AI を一級市民として扱う設計を身につけられます。
学習内容
基礎
- はじめてのAPI呼び出し — APIキーを設定し、Claude APIに1回送信して回答を確認する
- マルチターン会話 — 会話履歴を保持しながら複数回のやり取りを実装する
- モデル動作の制御 — システムプロンプト・temperature・ストリーミングでClaudeの応答をコントロールする
- ツールの利用 — Claudeにツールを定義して外部処理を呼び出せるようにする
拡張機能
- 拡張思考モード — Claudeに推論過程を公開させ、複雑な問題への対応力を高める
- 画像・PDF処理 — 画像分析やPDFからのテキスト抽出・引用生成を実装する
- プロンプトキャッシュ — 繰り返し送信するコンテキストをキャッシュしてコストとレイテンシを削減する
MCP
- MCPサーバー開発 — 標準化されたツールやリソースを提供するサーバーを実装する
- MCPクライアント開発 — MCPサーバーと連携するクライアントを実装する
リソース
下記のノートブックには、この記事と同じ内容が記載されており、また環境構築不要ですぐにPythonコードを実行することができます。
自分でコードを実行するだけでも動作を理解しやすいので、ぜひ活用してみてください!
注意点
ここで指定しているモデルやパラメータなどは、今後変更される可能性があります。
1. はじめてのAPI呼び出し
まずはPythonの input() でユーザーの入力を受け取って、Claude API に1回送信して回答を表示するシンプルなコードを動かしてみましょう!
1.1 APIキーの取得
ClaudeのAPI呼び出しには、APIキーが必要です。
まずはAPIキーを取得しましょう。
-
https://console.anthropic.com/ にアクセス(事前にアカウントを作成しておくこと)
-
「APIキーを取得」をクリック

- 「キーを作成」をクリック
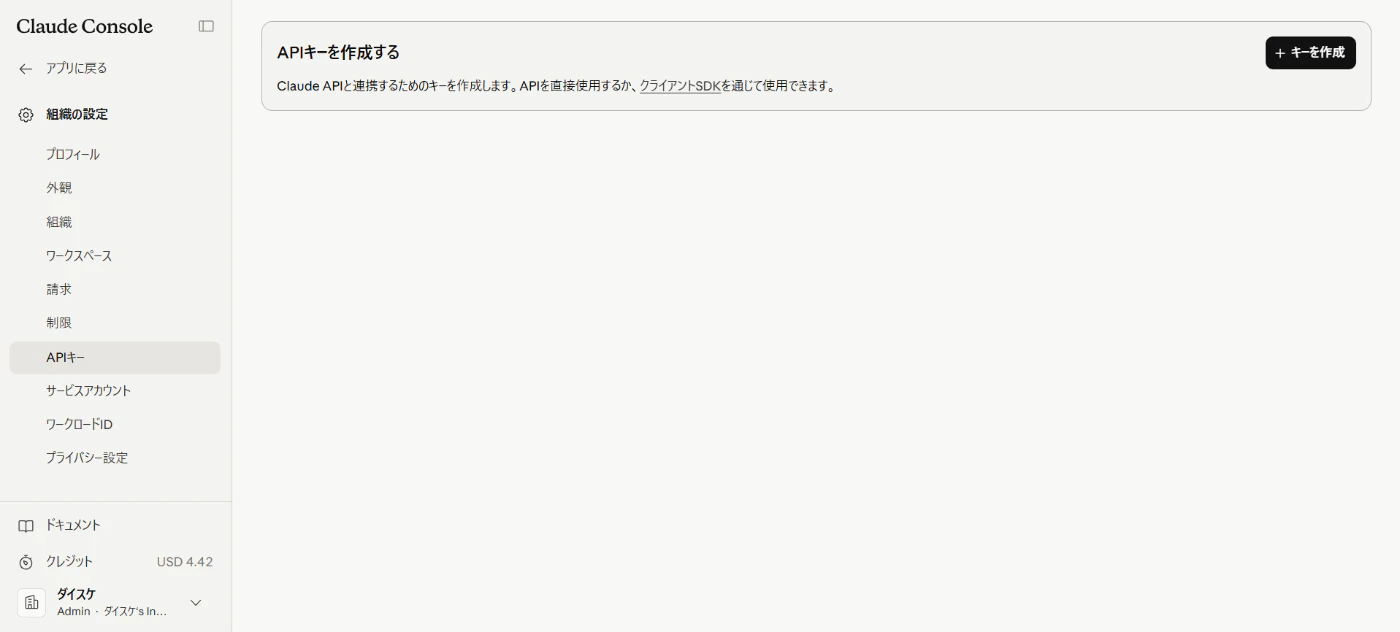
- キー名を入力して、追加をクリック
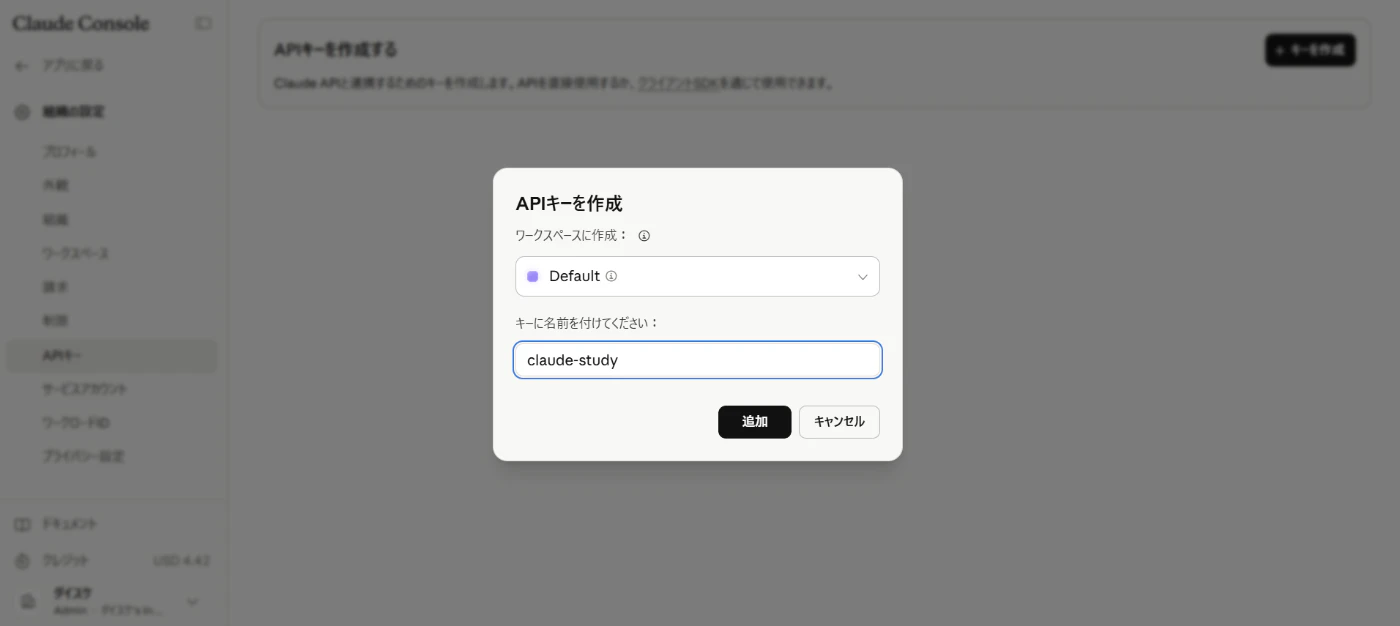
-
表示されるキーをコピー
-
プロジェクトのルートに
.envファイルを作成し、以下を記載する
ANTHROPIC_API_KEY="your-api-key"
1.2 Claude APIの実行
APIキーを環境変数に設定したら、Anthropicの提供するPythonSDKをインストールします。
pip install anthropic python-dotenv
次に環境変数を読み込み、Anthropic Clientを用いて、Claude APIを実行しましょう。
from dotenv import load_dotenv
# 環境変数 ANTHROPIC_API_KEY を読込
load_dotenv()
from anthropic import Anthropic
# Anthropicクライアントを作成(環境変数 ANTHROPIC_API_KEY を自動で参照します)
client = Anthropic()
# Claudeモデルを設定
model = "claude-sonnet-4-5"
# ユーザーの入力を受け取る
user_input = input("質問を入力してください: ")
# Claude呼び出しを実行
message = client.messages.create(
model=model,
# レスポンスの長さを最大1000トークン(1文字≒1〜2トークン)に制限する
max_tokens=1000,
# ユーザーメッセージ
messages=[
{
"role": "user",
"content": user_input
}
]
)
1.3 実行結果を確認
では上記のPythonを実行して、Claude APIの実行結果を確認しましょう!
# 入力: 量子コンピュータとは何ですか?1文で回答してください。
# 呼び出し結果を確認
print(message.content[0].text)
量子コンピュータとは、量子力学の原理(重ね合わせやもつれ)を利用して、従来のコンピュータでは困難な計算を高速に実行できるコンピュータです。
Claude APIを通じて、LLMの回答を取得することができましたね!
意外とシンプルじゃないでしょうか?
ちなみにレスポンス全体には、実行ID・レスポンス内容・使用トークン数などのメタ情報が含まれています。
# レスポンス全体を確認
print(message)
Message(id='msg_019UyprQPqAvTHLXXFVHcYUZ', container=None, content=[TextBlock(citations=None, text='量子コンピュータとは、量子力学の原理(重ね合わせやもつれ)を利用して、従来のコンピュータでは困難な計算を高速に実行できるコンピュータです。', type='text')], model='claude-sonnet-4-5-20250929', role='assistant', stop_reason='end_turn', stop_sequence=None, type='message', usage=Usage(cache_creation=CacheCreation(ephemeral_1h_input_tokens=0, ephemeral_5m_input_tokens=0), cache_creation_input_tokens=0, cache_read_input_tokens=0, inference_geo='not_available', input_tokens=30, output_tokens=69, server_tool_use=None, service_tier='standard'), stop_details=None)
これでClaude APIを通じて、入力に対するLLMの回答を取得することができました!
2. マルチターン会話
1回きりの呼び出しから、会話履歴を保持した複数回のやり取りへと発展させましょう!
2.1 複数回のClaude API実行
ではさっきのコードを使って、複数回Claude APIを実行してみましょう!
from dotenv import load_dotenv
# 環境変数 ANTHOROPIC_API_KEY を読込
load_dotenv()
from anthropic import Anthropic
# Anthropicクライアントを作成
# 環境変数 ANTHROPIC_API_KEY を自動で参照します。
client = Anthropic()
# Claudeモデルを設定
model = "claude-sonnet-4-5"
# ユーザーの入力を受け取る
# 「量子コンピュータとは何ですか?1文で回答してください。」
user_input = input("質問を入力してください: ")
# Claude呼び出しを実行
message = client.messages.create(
model=model,
# レスポンスの長さを最大1000トークンに制限する
max_tokens=1000,
# ユーザーメッセージ
messages=[
{
"role": "user",
"content": user_input
}
]
)
print(message.content[0].text)
量子コンピュータとは、量子力学の重ね合わせやもつれといった性質を利用して、従来のコンピュータでは困難な計算を高速に処理できるコンピュータです。
正常に回答を取得できましたね。
ではこの回答について追加の質問をしてみます。
# ユーザーの再入力を受け取る
# 「別の言い方をしてください。」
user_input2 = input("質問を入力してください: ")
# Claude呼び出しを再実行
message = client.messages.create(
model=model,
max_tokens=1000,
messages=[
{
"role": "user",
"content": user_input2
}
]
)
print(message.content[0].text)
# 他の表現方法を提案します
元の文章が示されていないため、一般的なパターンをご紹介します:
## よくある言い換え例
**丁寧な依頼の場合:**
- 「お願いできますか」→「お願いしてもよろしいでしょうか」
- 「教えてください」→「ご教示いただけますか」
**説明の場合:**
- 「つまり」→「要するに」「言い換えれば」
- 「だから」→「そのため」「したがって」
**意見の場合:**
- 「思います」→「考えます」「感じます」
---
具体的にどの文章を言い換えたいか教えていただければ、より適切な表現をご提案できます。
すると、このように量子コンピュータについての最初の回答を忘れてしまったような回答になりました。
2.2 複数回にわたる会話の実装
複数ターンに渡ってClaude APIを実行し、会話を行うにはどのようにすればよいのでしょうか。
Claude APIは「ステートレス」設計で、各リクエストは完全に独立しています。
前回までの会話を全く覚えていないため、会話の文脈はアプリ側が毎回送り直す必要があります。
つまり、下記のようなリクエストとする必要があります。
message = client.messages.create(
model=model,
max_tokens=1000,
messages=[
{
"role": "user",
"content": "量子コンピュータとは何ですか?1文で回答してください。"
},
{
"role": "assistant",
"content": "量子コンピュータとは、量子力学の重ね合わせや量子もつれなどの性質を利用して、従来のコンピュータでは困難な計算を高速で実行できるコンピュータです。"
},
{
"role": "user",
"content": "別の言い方で説明してください。"
},
]
)
これを実現するコードを実装して、下記を順番に入力してみましょう!
from dotenv import load_dotenv
load_dotenv()
from anthropic import Anthropic
client = Anthropic()
model = "claude-sonnet-4-5"
# 会話履歴を保持するリスト
messages = []
print("チャットを開始します。終了するには 'quit' と入力してください。")
# ループで複数回のやり取りを実現
while True:
user_input = input("\n質問を入力してください: ")
if user_input.lower() == "quit":
break
print(f"\nUser: {user_input}")
# ユーザーの入力をmessagesに追加
messages.append({
"role": "user",
"content": user_input
})
# Claude呼び出し(会話履歴ごと送信)
response = client.messages.create(
model=model,
max_tokens=1000,
messages=messages
)
# アシスタントのレスポンスを取得
assistant_message = response.content[0].text
# アシスタントのレスポンスをmessagesに追加
messages.append({
"role": "assistant",
"content": assistant_message
})
print(f"\nClaude: {assistant_message}")
チャットを開始します。終了するには 'quit' と入力してください。
User: 量子コンピュータとは何ですか?1文で回答してください。
Claude: 量子コンピュータとは、量子力学の原理(重ね合わせやもつれ)を利用して、従来のコンピュータでは困難な特定の計算を高速に実行できるコンピュータです。
User: 別の言い方をしてください。
Claude: 量子コンピュータとは、0と1を同時に表現できる量子ビットを用いて、特定の問題を従来型コンピュータより圧倒的に速く解くことができる次世代型コンピュータです。
チャットを終了します。
これで複数回にわたる会話を実現することができました!
3. モデル動作の制御
Claude APIでは、いくつかのパラメータを設定することでモデルの振る舞いをコントロールできます。
ここでは代表的な3つ — システムプロンプト・temperature・ストリーミング — を学びます。
3.1 システムプロンプトの定義
システムプロンプトとは、会話が始まる前にClaudeに与える「役割や前提条件の指示」です。
ユーザーからの質問(userメッセージ)とは別に、systemパラメータとして渡します。
Claudeはこの指示を前提として、すべての返答を生成します。
カスタマーサポートボットを作る場合などがユースケースになります。
- システムプロンプトなし → Claude は汎用的な AI として応答する
- システムプロンプトあり → Claude は「〇〇社のサポート担当者」として応答する
from dotenv import load_dotenv
load_dotenv()
from anthropic import Anthropic
client = Anthropic()
model = "claude-sonnet-4-5"
# 会話履歴を保持するリスト
messages = []
# システムプロンプトを定義
system_prompt = """
あなたは「豆と葉」というコーヒー・日本茶の専門店のカスタマーサポート担当者です。
【扱う商品】
- コーヒー豆(シングルオリジン・ブレンド)
- ドリップバッグ・カプセルコーヒー
- 日本茶(煎茶・ほうじ茶・抹茶)
- 茶器・コーヒー器具
【対応できること】
- 商品の特徴・おすすめの飲み方
- 注文・配送・返品に関するご案内
- ギフトセットのご提案
【対応ルール】
- お客様には必ず敬語・謙譲語を使い、丁寧にご対応ください
- 回答は簡潔にまとめ、要点を整理してお伝えください
- 対応範囲外のご質問には「担当者よりご連絡いたします」とお伝えください
"""
print("チャットを開始します。終了するには 'quit' と入力してください。")
while True:
user_input = input("\n質問を入力してください: ")
if user_input.lower() == "quit":
break
print(f"\nUser: {user_input}")
# ユーザーの入力をmessagesに追加
messages.append({
"role": "user",
"content": user_input
})
# Claude呼び出し(会話履歴ごと送信)
response = client.messages.create(
model=model,
max_tokens=1000,
messages=messages,
system=system_prompt
)
# アシスタントのレスポンスを取得
assistant_message = response.content[0].text
# アシスタントのレスポンスをmessagesに追加
messages.append({
"role": "assistant",
"content": assistant_message
})
print(f"\nClaude: {assistant_message}")
チャットを開始します。終了するには 'quit' と入力してください。
User: おすすめの商品を教えてください。
Claude: ご質問ありがとうございます。お客様のお好みに合わせておすすめをご提案させていただきます。
**コーヒーがお好きな方には:**
- **シングルオリジンコーヒー豆**:産地ごとの個性的な風味をお楽しみいただけます
- **ドリップバッグ**:手軽に本格的な味わいをお楽しみいただけます
**日本茶がお好きな方には:**
- **煎茶**:爽やかな香りと旨味のバランスが良い定番商品
- **ほうじ茶**:香ばしい香りでリラックスタイムに最適
**ギフトをお探しの方には:**
- コーヒー豆と茶器のセット
- 日本茶詰め合わせセット
もしよろしければ、以下をお聞かせください:
- コーヒーと日本茶、どちらがお好みでしょうか?
- ご自宅用・ギフト用のどちらでしょうか?
- お好みの味わい(苦味・酸味・香ばしさなど)はございますか?
より詳しくご案内させていただきます。
このようにシステムプロンプトに基づいて「豆と葉」というお店のカスタマーサポートとして回答してくれましたね!
3.2 temperatureの設定
temperatureとは、Claudeの回答のランダム性(創造性)を制御するパラメータです。
0〜1の値で指定し、値が小さいほど一貫した回答、大きいほど多様で創造的な回答になります。
| 範囲 | 特徴 | ユースケース |
|---|---|---|
| 低温(0.0〜0.3) | 毎回ほぼ同じ回答 | 事実に基づいた回答 コーディング支援 データ抽出 コンテンツモデレーション |
| 中温(0.4〜0.7) | バランス型 | 要約 教育コンテンツ 問題解決 制約のある創作活動 |
| 高温(0.8〜1.0) | 毎回異なる多様な回答 | ブレインストーミング クリエイティブライティング マーケティングコンテンツ ジョーク生成 |
同じ質問で比べてみましょう。
temperature=0.0 で「コーヒーのキャッチコピーを1つ考えてください。形式・長さ・雰囲気は自由です。」と5回聞くと、毎回ほぼ同じ回答が返ってきます。
temperature=1.0 にすると、毎回違う表現のコピーが返ってきます。
from dotenv import load_dotenv
load_dotenv()
from anthropic import Anthropic
client = Anthropic()
model = "claude-sonnet-4-5"
# 会話履歴を保持するリスト
messages = []
print("チャットを開始します。終了するには 'quit' と入力してください。")
while True:
user_input = input("\n質問を入力してください: ")
if user_input.lower() == "quit":
break
print(f"\nUser: {user_input}")
# ユーザーの入力をmessagesに追加
messages.append({
"role": "user",
"content": user_input
})
# Claude呼び出し(会話履歴ごと送信)
response = client.messages.create(
model=model,
max_tokens=1000,
messages=messages,
# temperatureを設定
temperature=0.0
)
# アシスタントのレスポンスを取得
assistant_message = response.content[0].text
# アシスタントのレスポンスをmessagesに追加
messages.append({
"role": "assistant",
"content": assistant_message
})
print(f"\nClaude: {assistant_message}")
実行結果を見てみましょう。
temperature=1.0 の場合
- 朝の、ひと息の、理由。
- 一杯の余白が、心を満たす。
- 一口で、世界が目覚める。
- 一杯の、ため息。
- 一杯の、深呼吸。
temperature=0.0 の場合
- 一杯の、ほっとする勇気。
- 一杯の、ほっとする勇気。
- 一杯の、ほっとする勇気。
- 一杯の、ほっとする勇気。
- 一杯の、ほっとする勇気。
temperature=0.0 では毎回まったく同じ回答が返ってきます。一方、temperature=1.0 では表現・リズム・コンセプトがそれぞれ異なります。
キャッチコピーのような短い回答でもこれだけ差が出ます。長文の回答(記事・レポート・ストーリーなど)ではこのばらつきがさらに顕著になります。
3.3 レスポンスストリーミング
通常のAPI呼び出しでは、Claudeが回答をすべて生成し終わってから結果が返ってきます。
回答が長い場合、10〜30秒以上ユーザーを待たせることになります。
ストリーミングを使うと、生成された文章をリアルタイムに少しずつ受け取れるため、ユーザーは回答が「書かれていく」様子をすぐに見ることができます。ChatGPTみたいな感じですね。
ストリームイベントの種類
ストリーミングを有効にすると、Claude から以下の順番でイベントが届きます。
| イベント | 内容 |
|---|---|
MessageStart |
メッセージ開始(id、modelなどのメタ情報) |
ContentBlockStart |
コンテンツブロックの開始(種類が確定する) |
ContentBlockDelta |
実際のテキスト差分(表示したいのはここ) |
ContentBlockStop |
コンテンツブロックの終了 |
MessageDelta |
stop_reasonや最終usageなどの終端情報 |
MessageStop |
ストリームの終了 |
ContentBlockDelta イベントのオブジェクトは以下のような構造になっています。
テキストは event.delta.text に格納されています。
RawContentBlockDeltaEvent(
type='content_block_delta',
index=0,
delta=TextDelta(
type='text_delta',
text='量子' # ← 実際のテキストはここ
)
)
1回のイベントで届くテキストは1〜十数文字程度で、これが連続して届くことで回答全体が組み立てられます。
これをシーケンスにすると次のようになります。
コードは次のようになります。
from dotenv import load_dotenv
load_dotenv()
from anthropic import Anthropic
client = Anthropic()
model = "claude-sonnet-4-5"
# 会話履歴を保持するリスト
messages = []
print("チャットを開始します。終了するには 'quit' と入力してください。")
while True:
user_input = input("\n質問を入力してください: ")
if user_input.lower() == "quit":
break
print(f"\nUser: {user_input}")
# ユーザーの入力をmessagesに追加
messages.append({
"role": "user",
"content": user_input
})
# Claude呼び出し(ストリーミング)
# client.messages.stream() コンテキストマネージャを使っても同じことができます
stream = client.messages.create(
model=model,
max_tokens=1000,
messages=messages,
stream=True
)
# ストリーミングでテキストを逐次表示
print("\nClaude: ", end="", flush=True)
assistant_message = ""
for event in stream:
if event.type == "content_block_delta" and event.delta.type == "text_delta":
print(event.delta.text, end="", flush=True)
# ストリーミングされたテキストをassistant_messageに追加し、最終的にmessagesに保存する
assistant_message += event.delta.text
print()
# アシスタントのレスポンスをmessagesに追加
messages.append({
"role": "assistant",
"content": assistant_message
})
チャットを開始します。終了するには 'quit' と入力してください。
User: 量子コンピュータとは何ですか?3文で回答してください。
Claude: 量子コンピュータは、量子力学の原理(重ね合わせやもつれ)を利用して計算を行うコンピュータです。従来のコンピュータが0か1のビットで計算するのに対し、量子ビット(qubit)を使い、0と1を同時に表現できます。特定の問題(暗号解読、分子シミュレーションなど)において、従来のコンピュータより圧倒的に高速な計算が期待されています。
チャットを終了します。
このように、回答を届いた順に少しずつ表示することができました!
4. toolの利用
LLMはテキストを受け取り、テキストを返すことしかできません。また学習済みの情報しか知りません。
単体では「現在の日時を調べる」「ファイルを作成する」「外部APIを呼ぶ」といった操作はできないのです。
tool(ツール) を使うと、この制約を解決できます。
Claudeが「この情報が必要だ」と判断したとき、定義しておいたツールを呼び出してデータを取得し、その結果をもとに回答を生成します。
toolが解決する3つの制約
| 制約 | 例 | ツールで解決 |
|---|---|---|
| リアルタイム情報を知らない | 現在の天気・株価・ニュース | 外部APIを呼び出すツール |
| 正確な計算が苦手な場合がある | 日時の加算・複雑な数値計算 | 計算処理をツールに委譲 |
| 外部システムを操作できない | ファイル作成・リマインダー設定 | システム操作をツールに委譲 |
tool利用フロー
toolを利用するフローは下記のようになります。
ポイントは ClaudeAPIのリクエストに応じて、アプリケーションがtoolを実行し、実行結果をClaudeAPIに送る という点です。
4.1 toolを作ってみよう
ツールというと複雑なものを想像するかもしれませんが、実態はただのPython関数です。
Claudeが指示した関数名と引数を使って、アプリ側が代わりに実行する——それだけです。
まずは get_current_datetime(現在日時を取得するツール)を作成して、ツール呼び出しの仕組みを理解しましょう!
STEP 1:tool本体をPython関数として実装する
STEP 2:ClaudeにtoolをJSON形式で説明する「入力スキーマ」を定義する
STEP 3:Claude API呼び出し時にスキーマを渡す
STEP 4:レスポンスに従ってツールを実行する
STEP 5:ツール実行結果を再度Claudeに送る
4.1.1 tool本体の実装(STEP 1)
では早速、現在日時を取得する get_current_datetime 関数を定義しましょう!
実装時のポイントはバリデーションとエラーメッセージの明確さです。
ツールの実行に失敗した場合、エラーメッセージはそのままClaudeに渡されます。メッセージが具体的であるほど、Claudeが引数を修正して正しく再呼び出しできる可能性が高まります。
from datetime import datetime
def get_current_datetime(date_format="%Y-%m-%d %H:%M:%S"):
if not date_format:
raise ValueError("date_formatを空にすることはできません")
return datetime.now().strftime(date_format)
4.1.2 関数の仕様をJsonで定義する
Claude はPython関数を実行できるように、関数の仕様をJSON形式のスキーマで渡してあげます。
スキーマの構成は3つです。
| フィールド | 役割 |
|---|---|
name |
ツールの識別名。Claudeが呼び出し時に使用する |
description |
ツールの説明。Claudeがいつ・なぜ使うかをここで判断する |
input_schema |
引数の型・説明・必須かどうかを定義するJSONスキーマ |
description は特に重要です。「何を返すか」「どんな場面で使うか」を明確に書くことで、Claudeが適切なタイミングでツールを選択できるようになります。
from anthropic.types import ToolParam
get_current_datetime_schema: ToolParam = {
"name": "get_current_datetime",
"description": (
"指定されたフォーマット文字列に従って現在の日時を返します。"
"現在の日付や時刻を知りたいときに使用してください。"
"現在の日時を文字列として返します。"
),
"input_schema": {
"type": "object",
"properties": {
"date_format": {
"type": "string",
"description": "strftimeフォーマット文字列(例:'%Y-%m-%d %H:%M:%S')。省略時は'%Y-%m-%d %H:%M:%S'を使用。",
"default": "%Y-%m-%d %H:%M:%S"
}
},
"required": []
}
}
4.1.3 Claude API 呼び出し時にスキーマを渡す(STEP 3)
ツール本体と入力スキーマを定義できたので、Claude(LLM)がこれを使えるようにしていきます!
ツールを使えるようにするには、API呼び出しに tools パラメータを追加するだけです。
response = client.messages.create(
model=model,
max_tokens=1000,
messages=messages,
# スキーマをリストで渡す
tools=[get_current_datetime_schema]
)
こうすることで、Claudeがツールを使う必要があると判断した場合、下記のようなレスポンスを返却します。
response = Message(
id="msg_94659bocAb3FaogEAOTYdsou5",
type="message",
role="assistant",
model="claude-sonnet-4-5-...",
stop_reason="tool_use", # ← "tool_use" or "end_turn"
stop_sequence=None,
content=[
ToolUseBlock(
type="tool_use",
# ツール呼び出しのID
id="toolu_013bjeocAb3RZKtQzjiYs56A",
# 呼び出すツール名
name="get_current_datetime",
# Claudeが指定した引数
input={"date_format": "%H:%M:%S"}
)
# TextBlockや複数のToolUseBlockが含まれることもある
],
usage=Usage(
input_tokens=80,
output_tokens=40
)
)
レスポンスのポイントは2つです。
1. stop_reason でループを制御する
これまでの response.stop_reason には "end_turn" が設定されていました。これはClaudeが入力された指示に対して最終的な回答を完了したことを意味します。
ですが、ツールの利用をリクエストする場合、response.stop_reason には "tool_use" が設定されます。この時はツールを実行し、その結果を再度Claudeを送ってあげる必要があります。
2. content にToolUseブロックが含まれる
stop_reason が tool_use の場合、response.content にはToolUseブロックが含まれます。
また content にはTextBlockや複数のToolUseBlockが含まれることもありますが、会話履歴には response.content をそのまま追加します。
messages.append({"role": "assistant", "content": response.content})
4.1.4 レスポンスに従ってツールを実行する(STEP 4)
stop_reason が "tool_use" の場合、content の中のToolUseブロックをループで取り出し、対応するPython関数を実行します。実行結果は tool_results リストにまとめます。
# ツール名と関数を紐づける辞書
TOOL_REGISTRY = {
"get_current_datetime": get_current_datetime
}
# stop_reasonが tool_use の場合
if response.stop_reason == "tool_use":
# toolの実行結果を格納
tool_results = []
for block in response.content:
# type = tool_use以外は無視
if block.type != "tool_use":
continue
# ツール名で対応する関数を検索
tool_fn = TOOL_REGISTRY.get(block.name)
# ツール名で取り出した関数をinvoke
result = tool_fn(**block.input)
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": str(result),
"is_error": False
})
4.1.5 ツール実行結果を再度Claudeに送る(STEP 5)
実行結果をまとめた tool_results を messages に追加し、再度Claude APIを呼び出します。
これによりClaudeは結果を受け取り、最終的な回答の生成に進みます。
# 結果をClaudeに返す
messages.append({"role": "user", "content": tool_results})
response = client.messages.create(
model=model,
max_tokens=1000,
messages=messages,
tools=[get_current_datetime_schema]
)
ここまでの一連のコードは下記のようになります。
下記を実行して、現在時刻を聞いてみましょう!
from anthropic.types import ToolParam
from datetime import datetime
def get_current_datetime(date_format="%Y-%m-%d %H:%M:%S"):
if not date_format:
raise ValueError("date_formatを空にすることはできません")
return datetime.now().strftime(date_format)
get_current_datetime_schema: ToolParam = {
"name": "get_current_datetime",
"description": (
"指定されたフォーマット文字列に従って現在の日時を返します。"
"現在の日付や時刻を知りたいときに使用してください。"
"現在の日時を文字列として返します。"
),
"input_schema": {
"type": "object",
"properties": {
"date_format": {
"type": "string",
"description": "strftimeフォーマット文字列(例:'%Y-%m-%d %H:%M:%S')。省略時は'%Y-%m-%d %H:%M:%S'を使用。",
"default": "%Y-%m-%d %H:%M:%S"
}
},
"required": []
}
}
# ツール関数リスト(定義するたびに追加)
TOOL_REGISTRY = {
"get_current_datetime": get_current_datetime
}
from dotenv import load_dotenv
load_dotenv()
from anthropic import Anthropic
client = Anthropic()
model = "claude-sonnet-4-5"
messages = []
print("チャットを開始します。終了するには 'quit' と入力してください。")
while True:
user_input = input("\n質問を入力してください: ")
if user_input.lower() == "quit":
break
print(f"\nUser: {user_input}")
messages.append({"role": "user", "content": user_input})
while True:
response = client.messages.create(
model=model,
max_tokens=1000,
messages=messages,
tools=[get_current_datetime_schema]
)
messages.append({"role": "assistant", "content": response.content})
print(f"\n [APIレスポンス] stop_reason={response.stop_reason}, content={response.content}")
# stop_reasonを見てループ:tool_use なら実行して再送信、end_turn なら終了
if response.stop_reason == "end_turn":
# 最終回答を表示
final_text = next(b.text for b in response.content if b.type == "text")
print(f"\nClaude: {final_text}")
break
if response.stop_reason == "tool_use":
# toolの実行結果を格納
tool_results = []
for block in response.content:
# type = tool_use以外は無視
if block.type != "tool_use":
continue
# ツール名で対応する関数を検索
tool_fn = TOOL_REGISTRY.get(block.name)
# 該当するツールが存在しない場合、エラーとして結果に追加して次へ
if tool_fn is None:
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": f"未知のツール: {block.name}",
"is_error": True
})
continue
# ツール名で取り出した関数をinvoke
print(f"\n [ツール実行] {block.name}({block.input})")
try:
result = tool_fn(**block.input)
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": str(result),
"is_error": False
})
# ツール実行中にエラーが発生した場合も、エラー内容を結果に追加して次へ
except Exception as e:
error_message = f"ツール実行エラー ({block.name}): {type(e).__name__}: {e}"
print(f"\n [エラー] {error_message}")
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": error_message,
"is_error": True
})
else:
print(f"予期しないstop_reason: {response.stop_reason}")
break
messages.append({"role": "user", "content": tool_results})
チャットを開始します。終了するには 'quit' と入力してください。
User: 現在日時を教えてください
[response] stop_reason=tool_use, content=[ToolUseBlock(id='toolu_013bjeocAb3RZKtQzjiYs56A', caller=DirectCaller(type='direct'), input={}, name='get_current_datetime', type='tool_use')]
[ツール実行] get_current_datetime({})
[response] stop_reason=end_turn, content=[TextBlock(citations=None, text='現在の日時は **2026年5月14日 23時51分10秒** です。', type='text')]
Claude: 現在の日時は **2026年5月14日 23時51分10秒** です。
チャットを終了します。
ツールを実行して最終的な回答を取得できていますね。
これをシーケンスにすると下記のようになります。
またツールの実行にエラーがあった場合のシーケンスは次のようになります。
ツールには具体的なエラーメッセージを設定しておくことで、Claudeが引数を修正して再呼び出しするか、リカバリー不能として回答を返すかを適切に判断できます!
ツール実行の流れがつかめたでしょうか?
4.2 複数のツール実行
では次は複数のツールを呼ぶ例を見てみましょう!
location と datetime_str から天気情報を取得する get_weather 関数を作成します。
本来は外部APIを呼び出すところですが、今回はダミー値を返却するようにします。
from anthropic.types import ToolParam
from datetime import datetime
def get_current_datetime(date_format="%Y-%m-%d %H:%M:%S"):
if not date_format:
raise ValueError("date_formatを空にすることはできません")
return datetime.now().strftime(date_format)
get_current_datetime_schema: ToolParam = {
"name": "get_current_datetime",
"description": (
"指定されたフォーマット文字列に従って現在の日時を返します。"
"現在の日付や時刻を知りたいときに使用してください。"
"現在の日時を文字列として返します。"
),
"input_schema": {
"type": "object",
"properties": {
"date_format": {
"type": "string",
"description": "strftimeフォーマット文字列(例:'%Y-%m-%d %H:%M:%S')。省略時は'%Y-%m-%d %H:%M:%S'を使用。",
"default": "%Y-%m-%d %H:%M:%S"
}
},
"required": []
}
}
def get_weather(location: str, datetime_str: str):
"""ダミー実装 — 実際はOpenWeatherMap等の外部APIを呼び出す"""
if not location:
raise ValueError("locationを空にすることはできません")
if not datetime_str:
raise ValueError("datetime_strを空にすることはできません")
# 本番では外部APIレスポンスを返す
return f"{datetime_str} の {location} の天気: 晴れ、気温 22℃"
get_weather_schema: ToolParam = {
"name": "get_weather",
"description": (
"指定した場所と日時の天気情報を返します。"
"天気・気温・気象状況を知りたいときに使用してください。"
),
"input_schema": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "天気を取得する場所(例:'東京', '大阪', 'Tokyo, JP')"
},
"datetime_str": {
"type": "string",
"description": "天気を取得する日時文字列。(例:'2026-05-14 12:00:00')"
}
},
"required": ["location", "datetime_str"]
}
}
# ツール関数リスト(定義するたびに追加)
TOOL_REGISTRY = {
"get_current_datetime": get_current_datetime,
"get_weather": get_weather
}
from dotenv import load_dotenv
load_dotenv()
from anthropic import Anthropic
client = Anthropic()
model = "claude-sonnet-4-5"
messages = []
print("チャットを開始します。終了するには 'quit' と入力してください。")
while True:
user_input = input("\n質問を入力してください: ")
if user_input.lower() == "quit":
break
print(f"\nUser: {user_input}")
messages.append({"role": "user", "content": user_input})
while True:
response = client.messages.create(
model=model,
max_tokens=1000,
messages=messages,
tools=[get_current_datetime_schema, get_weather_schema]
)
messages.append({"role": "assistant", "content": response.content})
print(f"\n [APIレスポンス] stop_reason={response.stop_reason}, content={response.content}")
# stop_reasonを見てループ:tool_use なら実行して再送信、end_turn なら終了
if response.stop_reason == "end_turn":
# 最終回答を表示
final_text = next(b.text for b in response.content if b.type == "text")
print(f"\nClaude: {final_text}")
break
if response.stop_reason == "tool_use":
# toolの実行結果を格納
tool_results = []
for block in response.content:
# type = tool_use以外は無視
if block.type != "tool_use":
continue
# ツール名で対応する関数を検索
tool_fn = TOOL_REGISTRY.get(block.name)
# 該当するツールが存在しない場合、エラーとして結果に追加して次へ
if tool_fn is None:
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": f"未知のツール: {block.name}",
"is_error": True
})
continue
# ツール名で取り出した関数をinvoke
print(f"\n [ツール実行] {block.name}({block.input})")
try:
result = tool_fn(**block.input)
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": str(result),
"is_error": False
})
# ツール実行中にエラーが発生した場合も、エラー内容を結果に追加して次へ
except Exception as e:
error_message = f"ツール実行エラー ({block.name}): {type(e).__name__}: {e}"
print(f"\n [エラー] {error_message}")
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": error_message,
"is_error": True
})
else:
print(f"予期しないstop_reason: {response.stop_reason}")
break
messages.append({"role": "user", "content": tool_results})
チャットを開始します。終了するには 'quit' と入力してください。
User: 現在の東京の天気は?
[APIレスポンス] stop_reason=tool_use, content=[ToolUseBlock(id='toolu_01JNbHjWa8ttQeStjBuwqMjJ', caller=DirectCaller(type='direct'), input={}, name='get_current_datetime', type='tool_use')]
[ツール実行] get_current_datetime({})
[APIレスポンス] stop_reason=tool_use, content=[ToolUseBlock(id='toolu_013aMHWdSUBf4dWFptwpccxr', caller=DirectCaller(type='direct'), input={'location': '東京', 'datetime_str': '2026-05-15 08:10:13'}, name='get_weather', type='tool_use')]
[ツール実行] get_weather({'location': '東京', 'datetime_str': '2026-05-15 08:10:13'})
[APIレスポンス] stop_reason=end_turn, content=[TextBlock(citations=None, text='現在の東京の天気は**晴れ**で、気温は**22℃**です。', type='text')]
Claude: 現在の東京の天気は**晴れ**で、気温は**22℃**です。
これで複数のツールを利用する動作も確認できました。シーケンスにすると下記のようになります。
また今回はツール実行を指示する回答が2回ありましたが、1回で複数のツール実行を指示されることもあります。
その場合のシーケンスは下記のようになります。
4.3 その他のツール実行
4.3.1 テキストエディタ
テキストエディタツールは、これまでのユーザー定義ツールと異なり、スキーマがClaudeのモデルに組み込まれた組み込みツールです。
自分でスキーマを定義しなくても、ClaudeAPI実行時のtoolsに下記を設定するだけで使えます。
response = client.messages.create(
model=model,
max_tokens=1000,
messages=messages,
tools=[{
# バージョン付きの型名
"type": "text_editor_20250728",
"name": "str_replace_based_edit_tool"
}]
)
Claudeは操作内容に応じて、以下のような input.command を持つToolUseBlockを返します。
// ファイル表示
{
"name": "str_replace_based_edit_tool",
"input": {
"command": "view",
"path": "primes.py",
"view_range": [1, 30]
}
}
// テキスト置換(完全一致・1箇所のみ)
{
"name": "str_replace_based_edit_tool",
"input": {
"command": "str_replace",
"path": "primes.py",
"old_str": "...",
"new_str": "..."
}
}
// ファイル新規作成
// 行指定で挿入(insert_line の後ろに追加)
// ...
アプリ側では command の値で処理を分岐させます。
def handle_editor_tool(block):
command = block.input["command"]
path = block.input["path"]
if command == "view":
view_range = block.input.get("view_range")
# ファイル読み込み or ディレクトリ一覧
...
elif command == "str_replace":
old_str = block.input["old_str"]
new_str = block.input["new_str"]
# old_str を new_str に置換(1箇所のみ)
...
elif command == "create":
# ファイル新規作成
...
elif command == "insert":
# insert_line の後にテキスト挿入
...
4.3.2 Web検索ツール
Web検索ツールも組み込みツールで、tools に指定するだけでClaudeが必要に応じて自動で検索・結果取得まで完結させます。
response = client.messages.create(
model=model,
max_tokens=1000,
messages=messages,
tools=[{
"type": "web_search_20250305",
"name": "web_search"
}]
)
つまりWeb検索ツールの利用フローは下記のようになります。
Claude側で全部やってくれるのはありがたいですね!
4.3.3 ストリーミング時のtool利用
Claudeのストリーミング機能を利用する場合、次のようにイベントの種類を見ながら、届いたテキストを順番に処理していくのでしたね。
では、このストリーミングの仕組みの中でツールを使う場合はどうなるでしょうか。
イベントの流れは同じですが、内容が変わります。まず ContentBlockStart でツール名(name)と呼び出しID(id)が確定します。
RawContentBlockStartEvent(
type='content_block_start',
index=0,
content_block=ToolUseBlock(
type='tool_use',
id='toolu_01...', # ← tool_result に使うID
name='get_current_datetime' # ← 実行する関数名
)
)
続いて ContentBlockDelta にはテキストの代わりにツール引数(JSON)が少しずつ届きます。
RawContentBlockDeltaEvent(
type='content_block_delta',
index=0,
delta=InputJSONDelta(
# メッセージの場合text_delta、ツール実行の場合input_json_delta
type='input_json_delta',
# JSON文字列の一部(まだ不完全)
partial_json='{"date_f'
)
)
partial_json の断片は届くたびにバッファに連結し、MessageStop 後にまとめてパースしてツールを実行します。
そのためツール実行は次のシーケンスのようになります。
4.3.4 ツールまとめ
ここまで、ユーザー定義ツール・テキストエディタ・Web検索・ストリーミング時のツール利用と、様々なツールの使い方を見てきました。
改めて整理すると、ツール実行の流れはシンプルです。
- アプリがClaudeにメッセージ+ツール定義を送る
- Claudeが「このツールをこの引数で呼んでほしい」と指示する(stop_reason="tool_use")
- アプリが実際にツールを実行する
- 実行結果をClaudeに返す
- Claudeが結果をもとに最終回答を生成する
Claude CodeやClaude Coworkを触っていると「AIがファイルを修正したりWeb検索したりしてくれる」と感じますが、この繰り返しです。Claudeの役割は意外とシンプルで、実際に手を動かしているのはアプリ側のプログラムです。
LLMはテキストの入出力しかできません。
ですがプログラムとうまく組み合わせることで、ファイル操作・外部API呼び出し・Excel操作などの便利な機能を実現しているのでした!
5. まとめ
基礎編では、Claude API を使ったアプリ開発の基礎を4つのステップで学びました。
| セクション | 身につけたこと | 主なAPI・パラメータ |
|---|---|---|
| 1. はじめてのAPI呼び出し | APIキーの設定、Clientの初期化、単発リクエストの実行 |
client.messages.create、max_tokens、message.content
|
| 2. マルチターン会話 | 会話履歴を messages リストで管理し、文脈を保持したやり取りを実現 |
messages[]、role: user/assistant
|
| 3. モデル動作の制御 | システムプロンプトで役割を与え、temperatureで回答の幅を調整し、ストリーミングで即時表示を実現 |
system、temperature、stream=True
|
| 4. toolの利用 | Python関数をツールとして定義し、Claudeが必要に応じて呼び出す仕組みを実装 |
tools[]、stop_reason="tool_use"、tool_result
|
これらを組み合わせると、たとえば次のようなアプリが作れます。
- 業務ルールを設定したカスタマーサポートBotに、在庫確認や注文照会のツールを追加する
- 会話履歴を保持しながら、ユーザーの質問に応じて外部APIから最新情報を取得して回答する
ツールさえ充実させてしまえば、Claude.aiっぽいチャットアプリも作れちゃいます!
今後のStep
Claude API を使ったアプリをより高度なものにするために、以下のような記事を書く予定です。
気になる部分だけでも、ぜひ読んでみてください!
拡張機能
- 拡張思考モード — Claudeに推論過程を公開させ、複雑な問題への対応力を高める
- 画像・PDF処理 — 画像分析やPDFからのテキスト抽出・引用生成を実装する
- プロンプトキャッシュ — 繰り返し送信するコンテキストをキャッシュしてコストとレイテンシを削減する
MCP
- MCPサーバー開発 — 標準化されたツールやリソースを提供するサーバーを実装する
- MCPクライアント開発 — MCPサーバーと連携するクライアントを実装する