はじめに
今回、セ・リーグの野球打者成績データを用いて、Pythonでクラスタリング(KMeans)を行い、打者タイプを分類・可視化してみました。
環境
OS: Windws11
開発環境:Jupyter Lab(Anaconda環境)
目的
「打率や長打率といった指標から、打者タイプの傾向を自動的に分類できるのか?」という問いを出発点に、以下のような視点で分析を進めました。
-
どんな特徴を持ったタイプの打者が存在するか?
-
各チームにはどのタイプの打者が多いのか?
使用したデータ
使用したデータは「https://baseball-data.com/ 」さんから、お借りしました。用意した、データは2024年度のセ・リーグ打撃ランキングのデータを使用し、打席数が150打席以上の選手に絞ったデータを準備しました。打席数を150打席以上にした理由は、例えば、打率を見てみると、ヒット数が同じでも、打席が少ない方がよい打率になってしまうなど、分析をする上での信頼性がかけてしまうと思い、今回は規程打席の約1/3(150打席)以上の選手66名に限定しました。
※規定打席とは、プロ野球でリーグが発表する打撃ランキングの対象となるために必要な打席の数である。(Wikipediaより)
[実際のデータ]

分析ステップ
ステップ1. データの取得と前処理
#必要なものをインポート
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# データのURL
url = "https://baseball-data.com/24/stats/hitter-ce/tpa-1.html"
# データの読み込み
df = pd.read_html(url)[0]
# カラム名変更
df.columns = ['順 位', '選手名', 'チーム', '打 率', '試 合', '打 席 数', '打 数', '安 打',
'本 塁 打', '打 点', '盗 塁', '四 球', '死 球', '三 振', '犠 打', '併 殺 打',
'出 塁 率', '長 打 率', 'O P S', 'R C 2 7', 'X R 2 7']
# 文字列は数値に、欠損値はnanに
df_1 = df.apply(pd.to_numeric, errors='coerce')
ステップ2. 特徴量(指標)の作成
今回のクラスタリングでは、「打者のプレースタイルを分類すること」を目的として、以下の6つの指標を特徴量として使用しました。
-
打率
安打を打つ頻度を示す基本的な打撃指標で、アベレージヒッターかどうかの判断に役立ちます。 -
出塁率
安打だけでなく四球や死球も含めた塁に出る能力を示し、選球眼や粘り強さを反映します。 -
長打率
単打以外の長打(2塁打以上)を打つ能力を測るもので、打者のパワーを評価する指標です。 -
三振率 (三振数 ÷ 打席数)
三振の割合を示し、コンタクト力やミートの正確さを逆から測るために用いました。 -
四球率 (四球 ÷ 打席数)
四球の割合から、選球眼や投球の見極め力を捉えるための指標です。 -
純長打率(長打率 − 打率)
通常の長打率は打率が高いと自然と上がってしまうため、「純粋な長打力」を抽出するために導入しました。
これらの指標を組み合わせることで、単に打率が高い・低いといった一軸ではなく、「ミート力」「パワー」「出塁能力」「選球眼」など多面的な視点で打者のタイプを捉えることでき、その結果、たとえば「ミート型で出塁力の高い打者」や「三振も多いが長打力のある打者」など、プレースタイルの異なる打者グループを分類できると思いこの特徴量を決めました。
# 三振率の計算
df_1['三振率'] = df_1['三 振'] / df_1['打 席 数']
# 四球率の計算
df_1['四球率'] = df_1['四 球'] / df_1['打 席 数']
# 純長打率の計算
df_1['純長打率'] = df_1['長 打 率'] - df_1['打 率']
ステップ3. データの標準化
標準化とは、各特徴量の平均を0、標準偏差を1に変換する処理のことで、標準化を行う主な理由は、特徴量のスケール(値の大きさ)が異なると、クラスタリング結果に偏りが出てしまうためです。今回は特徴量ごとに大きさが異なるため、標準化を行いました。具体的には、Pythonの機械学習ライブラリ scikit-learn の StandardScaler を使用し、各特徴量の平均を0、標準偏差を1にしました。
#標準化モジュールのインポート
from sklearn.preprocessing import StandardScaler
# 標準化
scaler = StandardScaler()
df_filtered_scalerd = scaler.fit_transform(df_filtered)
ステップ4. K-means法によるクラスタリング①
クラスタリングとは、簡単に言うと、集団を、ある規則や共通項にそって分類・グルーピングする手法です。その中の一つにk-means法があり、データを「k個のグループ(クラスタ)」に自動的に分けるために使われます。また、今回の分析では、「どんな特徴を持ったタイプの打者が存在するか?」という目的に対して、クラスタリング手法の中でも特にシンプルで直感的なk-means法を採用しました。クラスタ数については、自分のこれまでの野球感を基に4に決めました。
#KMeansのインポート
from sklearn.cluster import KMeans
#クラスタモデルの作成
kmeans = KMeans(n_clusters=4, random_state=0)
# 学習と分類
clusters = kmeans.fit_predict(df_filtered_scalerd)
ステップ5. 各クラスタの特徴を把握(クラスタ数=4の場合)
先ほど、標準化を行いクラスタリング分析を行いましたので、そちらの特徴を見ていきたいと思います。実際に示した表が下記の表になります。表の見方としては、平均を0にして、こからの「ずれ」を表しています。プラスの数字が大きい場合:得意である、優れている傾向があり、マイナス(負の)数字が大きい場合: 苦手である、劣っている傾向があり、0に近い数字の場合: その項目において、平均とほぼ同じであるということになります。
# 各クラスタの特徴を把握
df_filtered_scalerd.groupby('タイプ').mean()
[標準化データでクラスタリングした後の表(クラスタ数=4の場合)]

上記の表より、それぞれの特徴を見ていき、それぞれのタイプに命名をしていきます。
タイプ0: 「ミート型」理由: 三振率(-0.480372)より、三振が非常に少なく、比較的高くコンタクト能力があることが分かります。また、打率(0.640334)と出塁率(0.524192)より、ヒットを量産し、塁に出る能力に長けていると考えられます。一方で、長打率は平均程度、純長打率がマイナスであることから、ホームランなどの一発よりも、単打を積み重ねていくタイプのバッターであると推測できるため、「ミート型」と命名しました。
タイプ1: 「パワー特化型」理由: 打率(-0.557709)と出塁率(-0.595500)が低いにもかかわらず、長打率(0.475267)と純長打率(0.896897)が非常に高い。これは、多少三振が多く、打率が低くても、一度バットに当たれば長打、特にホームランになる可能性が高い選手であることを示しています。そのため、「パワー特化型」と命名しました。
タイプ2:「控えクラス型」理由: 全体的に打撃に関する指標が軒並み低いことが最大の特徴です。打率、出塁率、長打率が低く、攻撃面での貢献はあまり期待できないことから、「控えクラス」と命名しました。
タイプ3:「スラッガー型」理由: このタイプは、打率、出塁率、長打率の全てにおいて突出して高い数値を記録しており、オールラウンダーと言えます。そこから、攻守にわたって中心となる「スラッガー」にふさわしい、理想的な打撃成績を持つタイプであるため、「スラッガー型」と命名しました。
ステップ6. 各チームごとのタイプ分布を円グラフで可視化
ここまでは選手ひとりひとりに着目し、それぞれの選手がどんなタイプに属するのかを分析し、知ることができました。そこで、もう一つの目的である「各チームにはどのタイプの打者が多いのか?」という部分を明らかにするために、球団ごとのタイプ別人数の割合を出してみました。全球団のコードを乗せると長くなってしまうため、阪神タイガースのコードのみを記載します。その他の球団のコードもチーム名を変更しているだけです。
import matplotlib.font_manager as fm
# 日本語フォント
plt.rcParams['font.family'] = 'Meiryo'
fig, axes = plt.subplots(2, 3, figsize=(15, 8))
fixed_colors = {"控えクラス型": '#99FF99', "パワー特化型": '#FF9999',
"スラッガー型": '#FFCC99', "ミート型": '#66B2FF'}
# 阪神のラベル、サイズ
labels_T = df_T_type_all
sizes_T = df_T_type["count"]
colors = [fixed_colors[label] for label in labels_T]
# 円グラフ作成(阪神)
ax_1 = axes[0, 0]
ax_1.pie(sizes_T, labels=labels_T, autopct='%1.1f%%', startangle=90,
counterclock=False, colors=colors)
ax_1.set_title('阪神')
※ステップ6で一度終了予定でしたが、実際に選手名とタイプを目視で確認したところ、レギュラー選手であっても控えクラスに分類されているケースがありました。これは、守備型の選手や育成目的で我慢して起用している選手など、多様な層が控えクラスに含まれているためだと考えられます。そこで、クラスタ数のみを変更して再度分析を行ってみました。
ステップ7. K-means法によるクラスタリング②
クラスタ数4の結果より、もう少し細かく分類をした方がよいと思い、クラスタ数は5にしてみました。
# クラスタ数を5にしてみた場合
kmeans_1 = KMeans(n_clusters=5, random_state=0)
# 学習と変形
clusters_1 = kmeans_1.fit_predict(df_filtered_scalerd)
df_filtered_scalerd_1 = pd.DataFrame(df_filtered_scalerd)
df_filtered_scalerd_1['タイプ'] = clusters_1
df_filtered_scalerd_1.columns = ["打 率", "出 塁 率", "長 打 率", "三振率", "四球率", "純長打率", "タイプ"]
df_filtered_scalerd_1
ステップ8. 各クラスタの特徴を把握(クラスタ数=5の場合)
表の見方はステップ5で説明した通りです。
df_filtered_scalerd_1.groupby('タイプ').mean()
[標準化データでクラスタリングした後の表(クラスタ数=5の場合)]

ステップ5同様に、上記の表より、それぞれの特徴を見ていき、それぞれのタイプに命名をしていきます。
タイプ0: 「控えクラス型」理由: 全ての打撃指標において、他のタイプと比較して極めて低い数値を示している点が特徴です。打率、出塁率、長打率が軒並み低く、さらに三振が非常に多いことから、打撃面でチームへの貢献が難しい選手であることから「控えクラス型」と命名しました。
タイプ1: 「ミート型」理由: 三振率(-0.480372)より、三振が非常に少なく、コンタクト能力が高いと考えられます。また、打率(0.640334)と出塁率(0.524192)が比較的高いことから、安定してヒットを打ち、塁に出る能力に優れていると判断できます。一方で、長打率は平均程度、純長打率がマイナスであることから、ホームランなどの一発よりも、単打を積み重ねていくタイプのバッターであると推測できるため、「ミート型」と命名しました。
タイプ2: 「スラッガー型」理由: このタイプは、打率、出塁率、長打率の全てにおいて突出して高い数値を記録しており、オールラウンダーと言えます。そこから、攻守にわたって中心となる「スラッガー」にふさわしい、理想的な打撃成績を持つタイプであるため、「スラッガー型」と命名しました。
タイプ3: 「育成or衰退型」理由: 控えクラス型と似ているが、打撃指標全体がマイナスで低調ですが、三振が少ないという特徴があります。これは、バットには当たるものの、なかなか結果に繋がらないという状況を示唆している可能性がある。そのため、若手でこれから成長していく段階の選手(「育成型」)や、かつては活躍したものの年齢や怪我などで成績が落ち込んでいる選手(「衰退型」)に多く見られるパターンと考えられるため、「育成or衰退型」と命名しました。
タイプ4: 「パワー特化型」打率(-0.557709)と出塁率(-0.595500)が低いにもかかわらず、長打率(0.475267)と純長打率(0.896897)が非常に高い。これは、多少三振が多く、打率が低くても、一度バットに当たれば長打、特にホームランになる可能性が高い選手であることを示しています。そのため、「パワー特化型」と命名しました。
ステップ9 各チームごとのタイプ分布を円グラフで可視化
ステップ6同様に、もう一つの目的である「各チームにはどのタイプの打者が多いのか?」という部分を明らかにするために、球団ごとのタイプ別人数の割合を出してみました。全球団のコードを乗せると長くなってしまうため、阪神タイガースのコードのみを記載します。その他の球団のコードもチーム名を変更しているだけです。
# 円グラフの作成
fig, axes = plt.subplots(2, 3, figsize=(15, 8))
fixed_colors_1 = {"控えクラス型": '#99FF99', "パワー特化型": '#FF9999',
"スラッガー型": '#FFCC99', "ミート型": '#66B2FF', "育成or衰退型": '#D8BFD8'}
# 阪神のラベル、サイズ
labels_T_1 = df_T_type_all_1
sizes_T_1 = df_T_type_1["count"]
colors_1 = [fixed_colors_1[label] for label in labels_T_1]
# 円グラフ作成(阪神)
ax_1_1 = axes[0, 0]
ax_1_1.pie(sizes_T_1, labels=labels_T_1, autopct='%1.1f%%', startangle=90,
counterclock=False, colors=colors_1)
ax_1_1.set_title('阪神')
分析結果
以下は、各球団に所属する打者をクラスタリングで分類した結果を示しています。
[※再掲 標準化データでクラスタリングした後の表(クラスタ数=4の場合)]

[球団別打者傾向(クラスタ数=4の場合)]
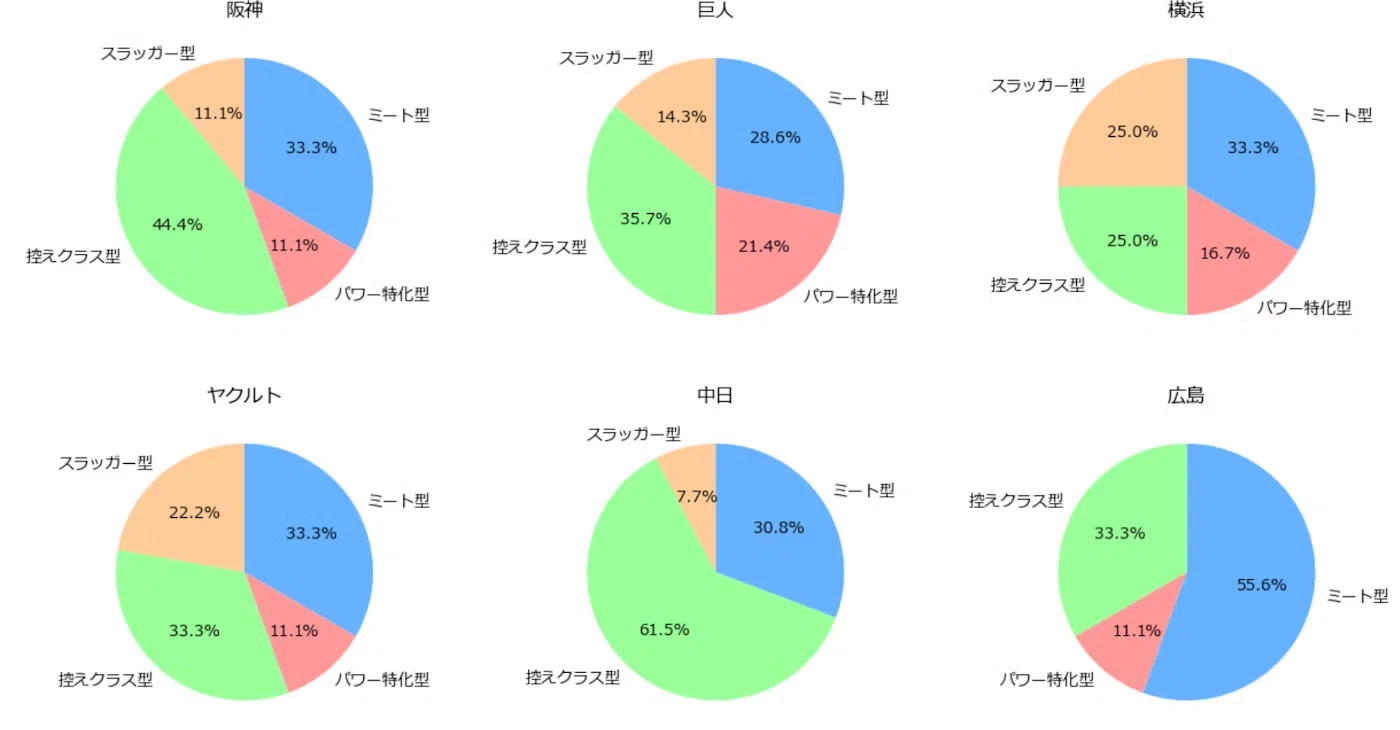
これまでの結果より、このグラフは、打者を「スラッガー型」「ミート型」「パワー特化型」「控えクラス型」の4つのタイプに分類することができました。また、セリーグ全体の傾向を見てみると「控えクラス型」が多くの球団で一定の割合を占める結果となりましたが、レギュラー選手であっても控えクラスに分類されているケースがあったため、あまり信用できる分類ではない結果となりました。
[※再掲 標準化データでクラスタリングした後の表(クラスタ数=5の場合)]

[球団別打者傾向(クラスタ数=5の場合)]

クラスタ数5の場合は、上記の4タイプに加えて新たに「育成or衰退型」というカテゴリを追加し、より詳細な5つのタイプに分類できました。選手名とタイプを目視で確認してみても、かなり現実的な感覚に近い結果となっていました。
まとめ
今回は、クラスタ数の違いによって分類結果がかなり異なるという結果になりました。実際に選手名とタイプを目視で確認したところクラスタ数=4の場合は、レギュラー選手であっても控えクラスに分類されているケースがありました。また、クラスタ数=5の場合はある程度実感覚と近い結果になりました。また、信頼性の高いデータにするため、150打席以上の選手で分析しましたが、100打席以上や規定打席の半分以上の条件にしてみたり、クラスタ数をエルボー法で求めてみたり、他の手法でクラスタリングを試すことで、より正確な分類ができるのではないかと思います。