この記事は “全体像” を つかむ “ハブ記事” です。
実装ステップごとの詳細手順は個別記事にリンクしているので、
まずは全体の流れと完成イメージ
を把握してください。
🎬 完成デモ (GIF)
画像をアップすると 検出枠 & ポケモン名 が返ってくるシンプルな図鑑アプリです。
アノテーションが大変で「ヒトカゲ」・「リザード」・「リザードン」の3種類しか検出できません^^
色違いは対応していますがメガ進化は対応していません!!!
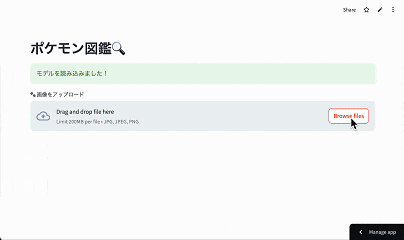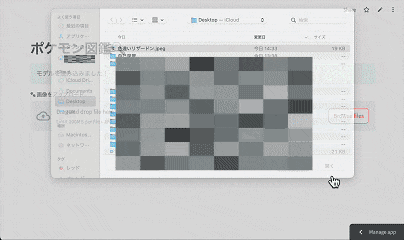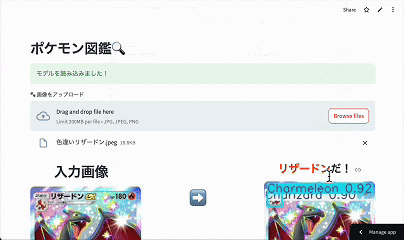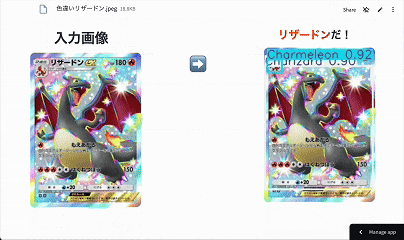
🔗 実際のアプリはこちら
目次
1. このガイドで得られるもの
-
YOLOv8 で学習した検出モデルを
-
Hugging Face Model Hub にホスティングし
-
Streamlit で GUI 化 → Streamlit Community Cloud (SCC) で外部公開
という エンドツーエンドのワークフロー を最短ルートで習得できます。
2. 前提環境 & 必要アカウント
- OS:Windows / macOS / Linux いずれも可
- Python:3.10 以上
- 開発環境:Google Colab
- アカウント:
- GitHub(コード管理 & SCC 連携)
- Hugging Face(モデルホスティング)
- Streamlit Community Cloud(アプリ公開)
3. 全体フロー図
4. ステップ別の流れ
1️⃣ データセット作成
-
画像をネットで収集
-
makesense.ai でラベル付け(YOLO 形式を選択)
-
train : val = 8 : 2 にフォルダ分割
ディレクトリ構造は以下参照
dataset/
├── images/
│ ├── train/ ← 学習用画像(.jpg/.png)
│ └── val/ ← 検証用画像
└── labels/
├── train/ ← train に対応する .txt(YOLOフォーマット)
└── val/ ← val に対応する .txt
- dataset.yaml を準備
記載内容は以下
train: /content/drive/MyDrive/.../ポケモン図鑑/dataset/images/train
val: /content/drive/MyDrive/.../ポケモン図鑑/dataset/images/val
nc: 3
names: ['Charmander','Charmeleon','Charizard']
2️⃣ YOLOv8 でモデル学習
# 環境構築
!pip install ultralytics
from ultralytics import YOLO
# 1. モデルのロード
model = YOLO("yolov8m.pt") # モデルサイズmを事前学習済みのウェイトで読み込み
# 2. 学習実行
results = model.train(
###--- Train settings ---###
data="data.yaml", # データ設定ファイルのパス
epochs=100, # 総エポック数:100
imgsz=640, # 入力画像サイズ:640×640 にリサイズ
batch=16, # バッチサイズ:16
device=0, # GPU0を使用。CPUなら"cpu"、複数GPUなら[0,1]なども可
# project="runs/detect/train",# 出力ディレクトリのパス
# name="pokemon_detector", # プロジェクト内のサブフォルダ名
optimizer="SGD", # オプティマイザの選択
###--- Augmentation Settings ---###
# 色補正強化
hsv_h=0.3, # Hue shift ±30% : 色相(Hue)を -hsv_h~+hsv_h の範囲でランダムにシフト
hsv_s=1.0, # Saturation shift ±100% : 彩度(Saturation)のシフト幅を -hsv_s~+hsv_s で制御
hsv_v=0.5, # Value shift ±50% : 色の鮮やかさを多様化
# シーン合成
mosaic=1.0, # Mosaic : 4つの画像を2×2で合成し、シーンの複雑さを増す
mixup=0.5, # MixUp : 2つの画像をピクセルレベルでブレンドし、ラベルも混合する
copy_paste=0.5, # Copy-Paste : セグメンテーション用ですが、検出タスクでも稀少オブジェクトのバリエーションを増やすのに有用
# 自動オーグメンテーション
auto_augment='randaugment' # AutoAugment : 分類タスク向けにRandAugmentやAutoAugmentなどの自動ポリシーを適用
)
⚠️学習モデルはデフォルトで次のパスで保存されます。
runs/detect/train/weights/best.pt
3️⃣ Hugging Face にモデルをアップロード
⚠️APIキーは外部に漏らさない!
🔗 詳しくはこちら → モデルアップロード編
4️⃣ Streamlit で Web GUI を構築
-
@st.cache_resourceでモデルをキャッシュ -
画像アップロード → 画像検出 → 検出枠付き画像表示
-
st.spinner("推論中...") で UX 改善
import streamlit as st
from PIL import Image
import cv2
import numpy as np
from ultralytics import YOLO
import requests
import os
from huggingface_hub import hf_hub_download, login
st.set_page_config(page_title="Pokemon Detector", layout="wide")
st.header("ポケモン図鑑🔍")
# ログイン処理をキャッシュ化
@st.cache_resource
def login_once(token):
login(token=token)
# Streamlit Secrets からトークンを取得してログイン
token = st.secrets["HUGGINGFACE_TOKEN"]
login_once(token)
@st.cache_resource
def load_yolo_model():
repo_id = "username/your-trained-yolo-repo"
filename = "best.pt"
model_path = hf_hub_download(
repo_id=repo_id,
filename=filename,
use_auth_token=token # トークンで認証ダウンロード
)
model = YOLO(model_path)
return model
model = load_yolo_model()
st.success("モデルを読み込みました!")
uploaded_file = st.file_uploader("🐾 画像をアップロード", type=["jpg","jpeg","png"])
if uploaded_file:
# 元画像の読み込み(PIL → numpy に変換)
pil_img = Image.open(uploaded_file).convert("RGB")
img_np = np.array(pil_img)
# 推論
with st.spinner("検出中…"):
results = model.predict(pil_img, imgsz=640, conf=0.25)
res = results[0]
# バウンディングボックスとクラスIDの取得
boxes = res.boxes.xyxy.cpu().numpy() # shape (N,4): x1,y1,x2,y2
class_ids = res.boxes.cls.cpu().numpy().astype(int)
confidences = res.boxes.conf.cpu().numpy()
names_map = res.names # {class_id: name}
# 英語→日本語の辞書
class_map_ja = {
"Charmander": "ヒトカゲ",
"Charmeleon": "リザード",
"Charizard": "リザードン"
}
# ─── 閾値付きボックス付き画像を生成 ───────────────────
annotated = res.plot() # BGR numpy array
rgb_annotated = cv2.cvtColor(annotated, cv2.COLOR_BGR2RGB)
# 面積を計算 → 最も大きいものを選択
areas = (boxes[:,2] - boxes[:,0]) * (boxes[:,3] - boxes[:,1])
if len(areas) > 0:
sort_idx = np.lexsort((-confidences, -areas)) # 面積→信頼度降順
idx = sort_idx[0]
x1, y1, x2, y2 = boxes[idx].astype(int)
crop = img_np[y1:y2, x1:x2]
class_id = class_ids[idx]
en_name = names_map[class_id]
label = class_map_ja.get(en_name, en_name)
else:
crop = None
label = None
# レイアウト:3カラム
col1, col2, col3 = st.columns([1,1,1])
with col1:
# ── 中央寄せ開始 ───────────────────────
st.markdown("<h2 style='text-align:center'>入力画像</h2>", unsafe_allow_html=True)
st.image(pil_img, use_container_width=True)
st.markdown("</div>", unsafe_allow_html=True)
# ── 中央寄せ終了 ───────────────────────
with col2:
st.markdown(
"<h1 style='text-align: center; margin-top: 60px;'>➡️</h1>",
unsafe_allow_html=True
)
with col3:
if label is not None:
# 名前を大きく表示
st.markdown(f"<h3 style='text-align: center;'><span style=\"color:#FF4500;\">{label}</span>だ!</h3>",
unsafe_allow_html=True)
# 切り出し画像を表示
st.image(rgb_annotated, use_container_width=True)
else:
st.subheader("検出結果なし")
st.write("画像内に検出できるポケモンがいませんでした。")
5️⃣ Streamlit Community Cloud(SCC) で公開
-
GitHub に全ファイル push
-
SCC ダッシュボード → New app → リポジトリ指定
-
URL 発行 → 友達にシェア 🥳
🔗 詳しくはこちら → SCC デプロイ編
5. 最後に
いいね ❤️ & ストック ⭐️ が励みになります。
質問・フィードバックはコメントでお待ちしています!