
AIを使って映像から通行量(歩行者量)を調査するソフトを作ったけど、最初は解析精度が低くて使い物にならず、いろいろ苦労してカウントの精度を上げた話です。車両の映像解析をした時にも苦労しましたが、歩行者は車両より小さい上バラバラの方向に移動するので、まったく別の苦労がありました。解析結果のムービーはこちら。映像解析は面白い&奥深いですねえ。
サマリー
・歩行者量を正しくカウントするための要件
・物体検出の手法と学習モデルの選定
・軌跡の描画機能によるノイズの発見と除去
・トラッキング方法の検証と機能追加
・正しいカウントを実現するための機能追加
・まとめ
歩行者量を正しくカウントするための要件
以前、車両の通行量を映像解析し際にトラッキングしたり、速度を出したりしててそれなりの結果が出せたので、「歩行者も楽勝では?」と考えてソフトを開発しましたがとんでもなく苦労しました。
そもそも「映像から歩行者を正しくカウントする」というのは、歩行者が何にいるか?という基本的なカウントに始まって、どうせならどっちに向かって歩いているか?とか、早く歩いているか・誰かを待っているか…などまでを映像から調べたいところです。
これらの「調べたいこと」を分解すると、これからソフトには以下の要件が必要になります。
1) 映像内の歩行者を正しく検出できるか?
2)移動する歩行者を正しく追跡できるか?
3)歩行者の移動を正しくカウントできるか?
このうち、1)は1枚の静止画から歩行者を正しく(かつ高速に)検出できる性能が必要で、2)は連続する静止画(つまり映像)から正しく「同一の」歩行者をトラッキングできる性能が必要。そして3)は歩行者の移動に関する属性(方向や速度・距離など)を検知してカウントする性能が必要…ということになります。
特に3)は「画面内の歩行者数のカウント」ではなく「移動方向別にカウントする」となると、カウント方法の工夫が必要になります。
例えばこれが車両だと通行する車線ごとに進む方向が決まっているので、「同一車線上の車の数=移動方向が同じ車の数」となるためカウントが楽でした。しかし歩行者は移動方向別に車線が決められておらずフリーダムに移動するため、カウント方法にも工夫が必要となります。
さらにはこれにプラスして、解析結果をいかに分かりやすくビジュアライズするか?という課題もありますが、これは結構深い話なので(すでに苦労しました)、別の記事として紹介する予定です。
なお今回は開発にあたっては「できるだけ無料公開されていて、商用利用もできるものをベースにして必要な機能を追加する」という方針をとりました。
物体検出の手法と学習モデルの選定
物体検出に何を採用するかは大きな問題で、定番のYolo V3のほか、M2DetとかCBNetとかいろいろ手法があり今でも競争が激しいようです(M2Det以降はあまり話題になってない気がしますが…)。ランキングはこちらにあります。
ただこのランキングは物体検出性能だけで、処理速度や学習の容易さなどは考慮されてないので映像解析目的では使えないものも多いので注意が必要です(1フレームの検出に数秒かかるものもある)。
さらにライセンスが商用利用可でソースを公開しなくてもいいやつで、できればトラッキングもついてるサンプルコードが公開されている…という観点で探すと、GitHubで1.1Kものスターを集めてるdeep_sort_yolov3がよさそうです。という訳で物体検出の手法はYoloV3を使うことになりました。
しかし同じYolo V3でも学習モデル(ウェイトファイル)が異なれば、速度や検出精度は全く別物になります。公開されているYolo用の学習モデルごとのランキングはこちらです。
公開されている無償のウェイトファイルの中では定番のYOLOv3-608、速さが命のYOLOv3-tiny、バランスの取れたYOLOv3-sppが良さそうです。実際に解析してみると以下の結果になりました。
YOLOv3-608の物体検出結果

処理速度は0.211133347秒/f(GPUはNVidia Geforce1080/8GB使用)
YOLOv3-tinyの物体検出結果

処理速度は0.132815607秒/f(GPUはNVidia Geforce1080/8GB使用)
YOLOv3-sppの物体検出結果

処理速度は0.207326508秒/f(GPUはNVidia Geforce1080/8GB使用)
となりましたので、今回の開発ではYOLOv3-sppを採用することにします。
なお最も高精度な物体検出を求めるなら専用で学習させたウェイトファイルを作るのが一番ですが、ここでは「最初にすでにあるものを使って評価して、それからチューニングする」という開発方針だったので、一般公開されているウェイトファイルから選びました。またdeep_sort_yolov3はKerasベースなので、Darknetオリジナルのウェイトファイルをh5ファイルに変換して測定しました。念のため。
軌跡の描画機能によるノイズの発見と除去
deep_sort_yolov3を改造してウエイトファイル(h5)を変更できるようにし、カウントやログの必要最低限の機能を実装してざっと試したところ、残念ながら精度が良くないことが分かりました。同じ歩行者を重複してカウントしたり、まっすぐ歩いているはずなのに細かく往復しているような座標移動があります。30fpsという一番細かい分解能で調べているのに、多数のノイズが混じっている。具体的には同一IDの歩行者がカウンターラインを超えるときに複数回カウントすることがある。
まっすぐ歩いているはずなのにこのカウントは変なので、まずは同一IDではカウンターライン毎に1度しかカウントしない機能を付けました。しかしそれは根本的な解決ではないため、原因を調査するために軌跡を描画する機能を追加しました。こんな感じです。

物体検出した枠(正確にはトラッカーの枠)の中心点を前のフレームから直線でつないで、歩行者がどのように歩いているとシステムが認識しているかを視覚化したわけです。すると衝撃の事実が分かりました。
歩行者は直線的に歩いているはずなのに軌跡はギザギザで、ノイズまみれでした。カウンターライン近辺でも中心点がギザギザに移動しているように見えるため、同じIDなのに複数回カウンターラインを超えることがあったのです。
このノイズがどこから来たか調べたところ、移動する歩行者を物体検出するとフレーム毎に枠が比率や大きく変わり、これがノイズになったようです。歩行者が歩くために手足を大きく広げると物体検出枠が横長になり、逆に手足を振り終えると枠が縦長になるためそれだけで中心点が移動しているように見えるのですね。車両だとタイヤしか動かないため移動時の形態変化がほとんどなく、検出枠の中心点も直線移動することがほとんどだったので、これは盲点でした。これを解決するために、分解能を落とすことにしました。

画像は左が30fp、右が3fpsに落としたものです。間引きした方が軌跡がきれいになり実際の進行方向とも一致するようになりました。これなら方向や距離も正しくとれそうです。しかも間引きすることで映像としての処理量も減るため、解析速度を上げることができて一石二鳥ですね。
トラッキング方法の検証と機能追加
もともと歩行者は車両と比べて圧倒的にサイズが小さく、またカップルで歩いたりするためカメラに対して重なり(オクルージョン)が発生しやすい。そのうえさらにfpsを落としてしまうので、出力映像を見てみるとトラッキングに失敗してしまう事も多い。
そこで本当にdeep_sortがトラッキング手法としてイケてるのか調べるために、AI映像解析の数をこなしている中華系の人たちが大好きなdlibをdeep_sort_yolov3に組み込んでみて、トラッキング性能を比較してみました。
トラッキング性能を比較するのは解析結果のムービーを見るのが一番ですが、それだと時間がかかるので追加した軌跡の描画機能を使ってみることにしました。この画像のうち、赤や青の色が付いた軌跡はカウントが正しくできているもので、白いラインはカウンターラインを超えていないもの、そして問題の「白いドットや破線」が正しくトラッキングできていないものになります。
要するに歩行者として物体検出できなかったり、あるいは別IDとして一瞬だけ検出できる・・・というのを繰り返すと、破線状態になってしまう訳ですね。それぞれのトラッキング方式による結果は以下の通りです。
deep_sortによる軌跡の描画

dlibによる軌跡の描画
これを見るとdeep_sortの方がやや成績がいい。判断の基準は、「白い線が少ない方が優秀と考える」「短い線が少ない方が優秀と考える」です。また解析速度もdeep_sortの方が早い。この理由を考えてみると、dlibは画像の特徴量を追いかけるため、映像上のサイズが小さくて形態変化が大きい歩行者にはそもそも不向きで、かつトラッカー枠をYolo検出枠に合わせる実装にしたため、処理時間がかかっているーーという予想になりそう。よってトラッキング手法としてはdeep_sortをそのまま採用することにします。
ただそれでもトラッキングが十分ではないため、機能を追加することにしました。
ログを見てみるとトラッキングが途切れるのは、ID42としてトラッキングしていた歩行者が次の処理タイミングでID53として現れる--という感じになります。そこでログにステイタスの項目を追加し、それ以降登場しないIDを「End」・新しく登場したIDを「New」としました。そして最寄りのEndとNewをつなげることで、トラッキングは切れても軌跡としてつなげることができました。
これを「End2New」と名付け、これが適用された場合は軌跡を指定した色で描画するようにしました。
サンプルは以下となります(左はEnd2Newがオフ。右がオンで黄色のラインが軌跡の補間です。すいません、ちょっと画像が地味ですね。時間があれば撮りなおします)。

正しいカウントを実現するための機能追加

物体検知とトラッキング(正確には軌跡の補間)にメドがついたので、次は歩行者の「振舞い」の検出と正しいカウントについて検証します。
サンプルの映像では上図のように上下左右方向つまり十字路に道が開けており、歩行者の移動方向別に正しくカウントするのが最終的な要件となります。車両と違うのは歩行者は自由な方向に移動するため、移動方向を確定するには継続的な「観察」が必要となります。例えば横移動したように見えてもそれは混雑を避けるためであり、最終的には上から下へ移動している--といったことも普通に起こります。
そこでこのソフトでは画面内に複数のカウンターラインを設置して「カウンターラインを超えた方向別にカウントする」「複数のカウンターラインを超えた歩行者は、最後に超えたカウンターラインの方向を最終とする」という仕様にしました。
軌跡でいうと、色がついている軌跡はカウンターラインごとに設定した「方向カラー」ですね。左から右に交差すると方向カラーが赤に設定され、さらに移動して上から下へ交差すると方向カラーが緑になります(軌跡は最後に得た方向カラーで更新されます)。
ところが当初の機能でカウントしたところ、歩行者のほとんどが上下に移動しているにもかかわらず、左右移動のカウンター数が不自然に多い。これは「カウンターラインと交差したらカウントする」という単純な仕様だったためです。カメラを真上に取り付けているわけではないので、歩行者は上下に移動しているのに映像上はナナメに移動しているように見えるため、これを全部カウントしているわけですね。これはマズイ。実際に軌跡を確認しても、明らかに上下方向に移動している歩行者も左右の方向カラー(ピンクと緑)が付いてます。
角度制限なしの軌跡

※この図では上下方向のカウンターラインは削除しています。
そこで左右に移動する歩行者の特徴を捉えるために、ログ機能で軌跡の角度(X軸に対する角度)を取るようにしました。
特にカウンターラインとの交差したときの角度をログから洗い出してみると、-160とか170度とかが多い。逆に上下方向に移動する歩行者は-12とか25度など左右方向の歩行者と比べると交差するときの角度が浅いことが分かったため、カウント機能に仕様を追加して、角度の閾値を設けるようにしました。
例えばThreshold=20とした場合は、カウンターラインと方向ラインの交差する角度に対して±20度の角度のみをカウントするようにしました。図ではカウンターラインと方向ラインは直交して(交差角度は180度)いるので、160~200度と-160~-200度で交差する軌跡だけをカウントするようにした。結果は以下のようになります。
角度制限ありの軌跡

少し見えにくいですが、緑のラインが1本だけ水平に交差していますね。他はすべて白の軌跡で、左右方向の移動はカウント対象外となっており成功です。本当は左から右に移動している歩行者も1名いるのですが、カウンターラインの手前で重なってしまい、検出できませんでした。残念!ムービーはこちらです。
なお角度にプラスマイナスがあるのは、移動方向によるものです。下から上にカウンターラインを超えたときはプラスの角度、逆に上から下に超えた時はプラスの角度になります。移動の方向も取れるので良い感じですね。
またログに軌跡の長さも記録するようにして確認したところ、カウンターラインとの交差時にやたら長い軌跡が記録されていた。これはトラッキングの失敗やEnd2Newのミスによるもので、例えばある歩行者のIDが離れた場所にいる良く似た別の歩行者とマッチングするため軌跡が不自然に長くなる。これを防ぐため、カウント時には軌跡の角度と共に長さにも閾値を設け、閾値外の軌跡が交差した場合はカウントしないよう制限を設けた。これによりトラッキングや軌跡の補間ミスによるカウントミスはあるものの、誤カウントは減らすことができました。
まとめ
せっかくAIを使うので、映像を入力するだけで全自動で解析を完了してくれる…というのが理想なのですが、現実はそこまで甘くはありません。物体検出時のYoloスコア値やnon_max_suppressionの設定、トラッキングの際のカルマンフィルタの設定などまずは物体検出からトラッキングまでの基本設定が必要となります。
加えてカウントを正確に行うため、fpsの間引き数を検討したり歩行者の移動速度(距離)の平均やカウンターラインとの交差時の角度を調べて閾値を設定する必要があります。
ただ歩行者の移動速度などはラッシュ時などでは若干早くなりそうですが、一度閾値を設定してしまえばその後は使いまわしができそうです。またトラッキングや軌跡の補間ミスについては、現在のウエイトファイル(学習モデル)ではこれ以上の精度アップは難しいため、解析対象となる映像専用で学習させたウエイトファイルを用いることで、物体検出の底上げを図ってカウントの精度アップにつなげることができそうです。
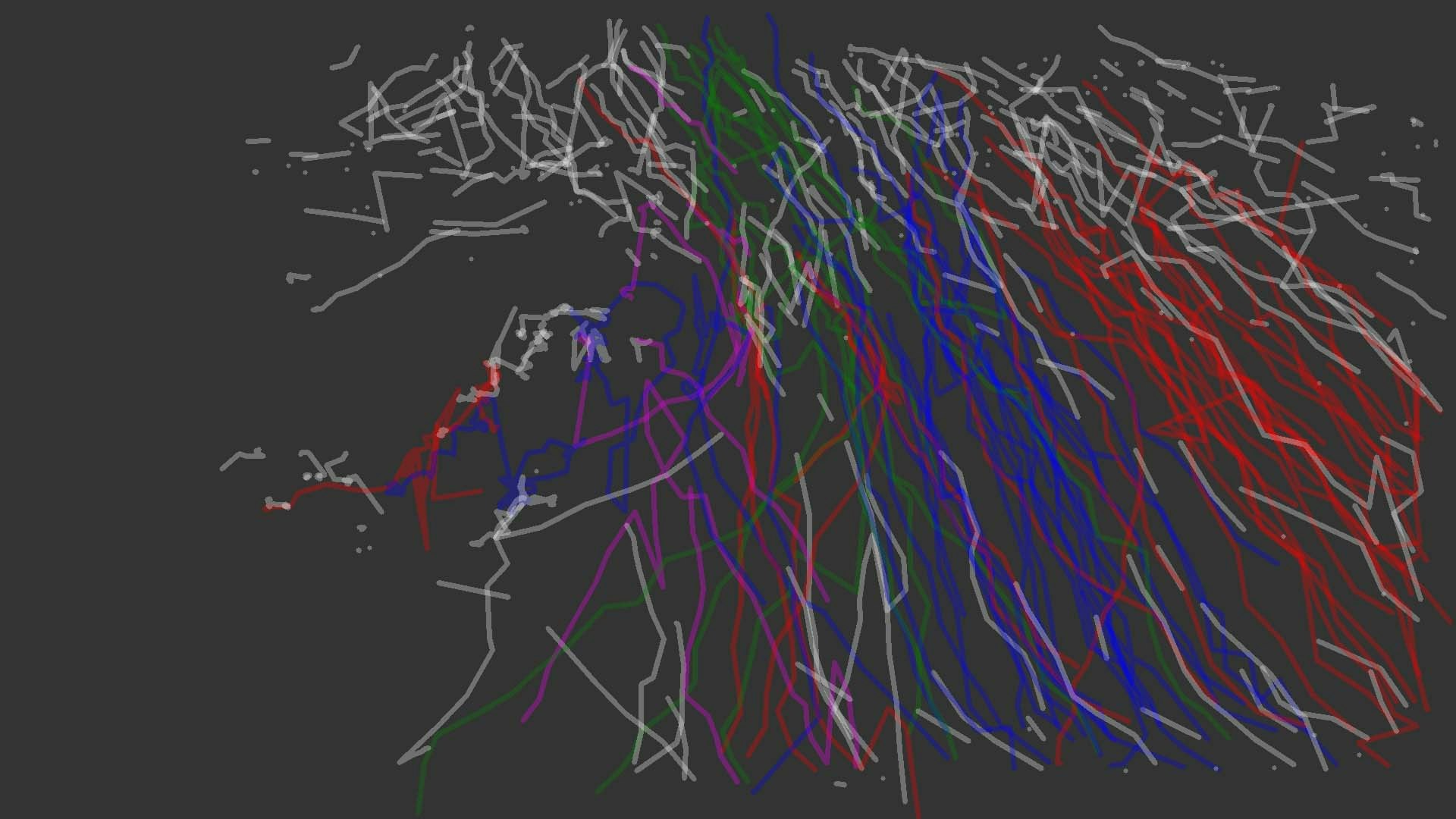
なお現在、解析結果の視覚化についても実験しています。
図は27分くらいの映像を視覚化したもので、4方向で合計3000本ほどの軌跡(白の軌跡はカウントから除外)を描画しています。

すさまじいですね。まるで前衛芸術家の作品のようです。膨大な数の軌跡をどう描画すれば一目でわかるのか?が課題になりそうです。
あと黄色い円は滞留を示すもので、要するに動きが少なかった範囲ですね。お店の近くや案内板、曲がり角などで滞留が発生しているので狙い通りです。視覚化については今チャレンジしている機能追加のめどが立ったら、別記事で書きますね。
関連記事
・2022年:YOLOXの映像解析で車両の速度をAIで算出して渋滞を判定するのに苦労した~その1:リアルタイム処理編
・2022年:YOLOXの映像解析で車両の速度をAIで算出して渋滞を判定するのに苦労した~その2:速度算出手法編