
サマリー
Teslaというのは電気自動車のことではありません。データセンターなどに使われているとても高いGPUを積んだNVIDIA製のボードで120万円とかします。GeForceはゲーミングPCとかで使われているコンシューマ向けGPUのボードで、そこそこいいやつでも6万円くらい。幸いなことに、どちらでもYolo V3とか動いて物体検出などのディープラーニング用途に使えます。
だったら価格が1/20のGeForceでどこまでTeslaと同じようなことができるか試すために、FHD映像を3並列で映像解析させてみました。
これは前回記事「ケチ上等!GPU費用を節約するため4台のカメラ映像を1度に映像解析するのに苦労した」の続きでもあります。前回記事ではGPU費用を節約するためのケチ作戦として4本の映像を1つにまとめて解析する方法でGPU節約効果があることを検証しましたが、「ケチ作戦1」で考えていた「1枚のGPUボードで複数の映像を解析する」手法にミスがあり、本来できるはずのことができてませんでした(よく考えたらVRAMが4GBしかないGTX1050でもFHD映像を解析できたので、VRAM8GBのGTX1080で並行処理できなはずがない?)。
今回の検証の背景には、GPU費用の節約があります。
例えば32台のカメラが24時間365日垂れ流しているFHD映像を解析する場合、私はケチなので以下のように考えてしまいます。
・4映像をまとめて1映像として処理させればGPU代が節約できるね(←前回記事で検証済み)
・4映像をまとめた映像を1枚のGPUで複数同時処理できればさらにGPU代が節約できるね(今回の検証目的)
もしGPU代を節約しない場合、カメラ32台の映像を処理するためにVRM8GBのRTX2070が32枚(単価6万円としてもGPU代だけで192万円税別)とか買わないといけないわけです。オンプレではなくデータセンター使っちゃうと、VRAM32GBのTesla V100だと1枚で4カメラ処理できるとして単価120万でGPU代は960万円かかりますね。人工知能バブルが終わった今、GPU代にお金がかかるのは現実的ではありまえせん。
仮に4映像を1つにまとめてさらに1枚のGPUで2つの映像を同時処理できれば、GPU4枚で32台のカメラからの映像が処理できます。1枚のGPUで3枚の映像を同時処理できれば、GPU3枚で済みます!GPU節約効果はなんと1/8以上!
この節約効果を書いただけで私の頭の中に「とらたぬ」「絵もち」という言葉が浮かびます。それで本当かどうか試してみました。参考にさせていただいたのは、前回記事のコメントで情報を頂きました「KerasでGPUメモリの使用量を抑える方法」です。
GPUに並列処理させるにはKerasのメモリ割当方法の指定が必須
私の実装ではkeras-yolo3を使って、Yolo V3で物体検出を行っています。初期設定では、keras-yolo3で起動するとKerasがGPUメモリを「あるだけ」確保してしまうので、そりゃ「ケチ作戦1」で考えた2本同時の並行処理なんてできませんね。
ただしこれはKerasのメモリ割当方法を変更することで、並行処理があっさり可能になりました。
メモリ割当の方法は3つあります。
1)メモリがあるだけ(使えるだけ)確保する
2)処理に必要な最小限のメモリだけ確保する
3)合計GPUメモリの割合指定で確保する
1)は並行処理には論外なので、2)か3)ですね。フレキシブルに対応できそうなのは2)で、運用・設備計画としてコントロールしやすそうなのは3)ですね。また2)と3)それぞれの方式で、何枚まで並行処理出来て、1枚当たりの処理速度がどれくらい下がるか?にも興味がありますね。そこで実際にやってみました。
比較用基準値の設定
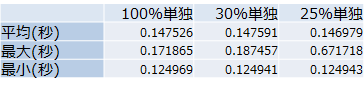
この表は4画面のマルチ映像(FHD)をKerasのメモリ割当が「100%」「30%」「25%」に設定したものをそれぞれ単独で実施し、1000フレームの映像を処理した場合に1フレームあたりにかかった時間(単位は秒)をまとめています。
今回使用したのはVRAM8GBのNVIDIA GTX1080なので、簡単に言うと「8GB」「2.4GB」「2GB」のメモリ割当で処理したことになりますね。
ビックリしたのが、100%と30%と25%にあまり差がみられないことですね。平均だけで判断すると、25%割当が一番高スコアです(数字が少ない方が高速に処理できる)。とにかくこれ(25%単独)を基準値として、並行処理をしたときにどれくらい処理速度が落ちるか検証してみましょう。
なお本来ならば、32台のカメラの別映像を並行処理したいところですが、今回は処理速度の検証のため並行処理でもまったく同じマルチ映像を解析しています。
最小限のメモリだけ確保する
ソースコードは以下になります。model.pyに手を加えます。
import tensorflow as tf
from keras import backend as K
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
K.set_session(sess)
1)2映像を並行処理
結果はこうなりました。
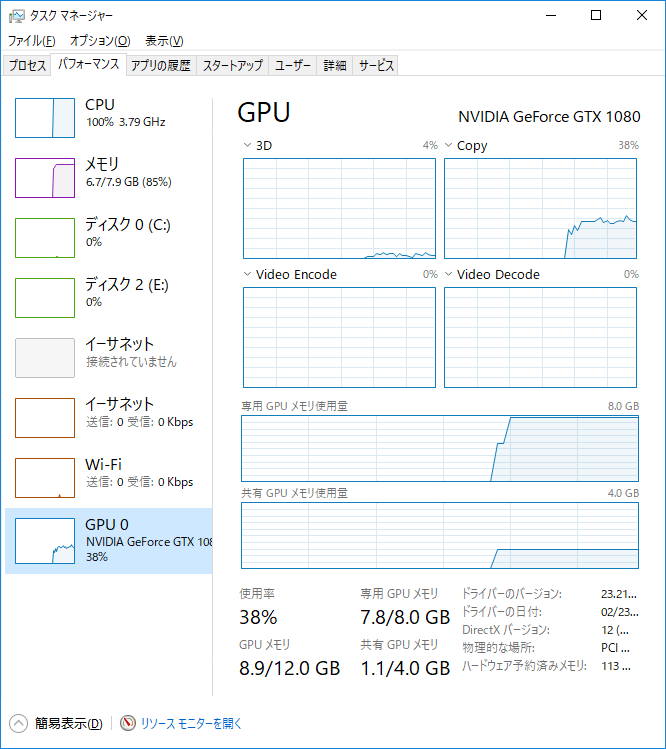

2本の映像を並行処理して、その平均が1フレームあたり0.204477秒。基準値は0.147591秒なので1本あたりの効率(基準値/スレッド平均)は72%です。
CPUの使用率は38%なので、もう1スレッドくらいいけそうですね。
2)3映像を並行処理
ところが調子に乗って3本目を実行してみると、こんな結果になりました。
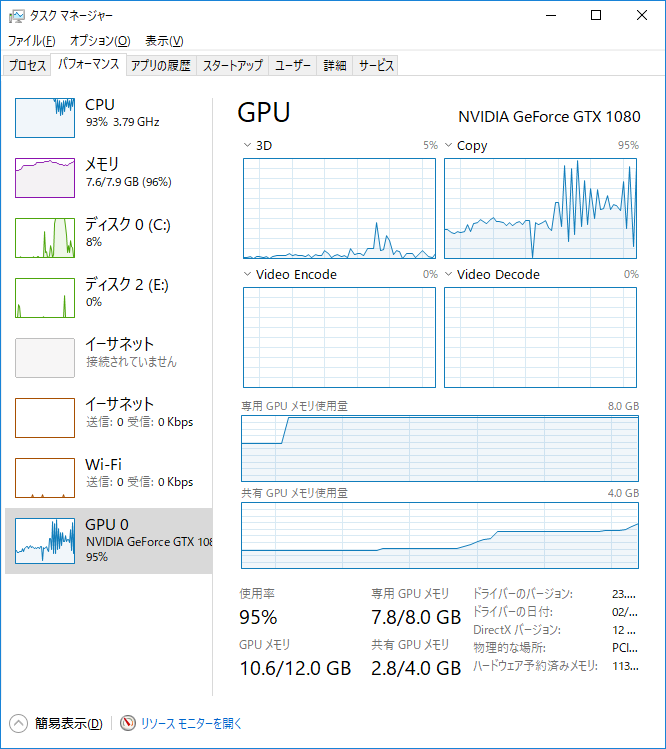

効率が**9.22%!**92.2%の間違いではありません。これでは並行処理より1本ずつ解析した方がよほど早いです。
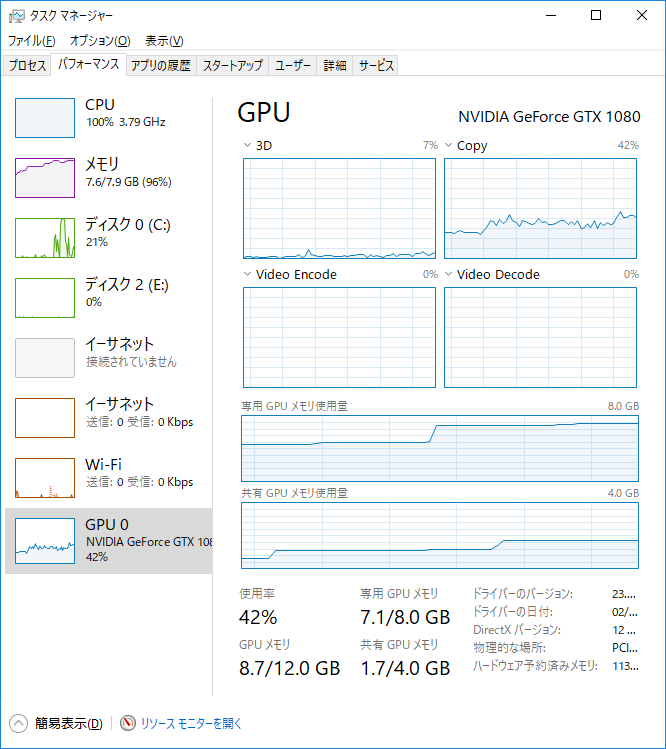
タスクマネージャーのスクリーンショットは3本目のスレッドを立ち上げたあとに撮ったものですが、前の2本より後から立ち上げた3本目の方が処理が高速です(それでも遅いですが)。
注目すべきはGPUの使用率のグラフで、ギザギザがひどい。スクリーンショットでは95%になってますがこの値は一律ではなく、44%⇒62%⇒84%⇒95%⇒55%とか目まぐるしく変わります。見た感じ、どうも1本目と2本目のメモリが足りなくなって、交互に使い分けている風にも見えます。
また3本目を実行したとき、いろいろエラー(抜粋)が表示されました。
totalMemory: 8.00GiB freeMemory: 3.36GiB
failed to allocate 1.51G (1620679680 bytes) from device: CUDA_ERROR_OUT_OF_MEMORY
Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.14GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
結果的にはスレッド3本とも最後までRUNしましたが、これはダメです。
合計GPUメモリの割合指定で確保する
model.pyに手を加えるソースコードは以下になります。「KerasでGPUメモリの使用量を抑える方法」のまんまですね。以下の例では0.4を指定しているので、例えば使用可能なメモリ合計が8GBなら3.2GBを割り当てて他には手を出さないことになります。
import tensorflow as tf
from keras import backend as K
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.4
sess = tf.Session(config=config)
K.set_session(sess)
今回のテストでは「割り当てたGPUメモリが多い方が処理速度に貢献するのでは?」と考えて、2並列の時は0.3ずつ、3並列の時は0.25ずつ割り当てて実験しました。ただし基準値を計測した際にはメモリ割当が100%・30%・25%とあまり差がなかったため、FHD映像では違いがないのかもしれません。
1)2映像を並行処理
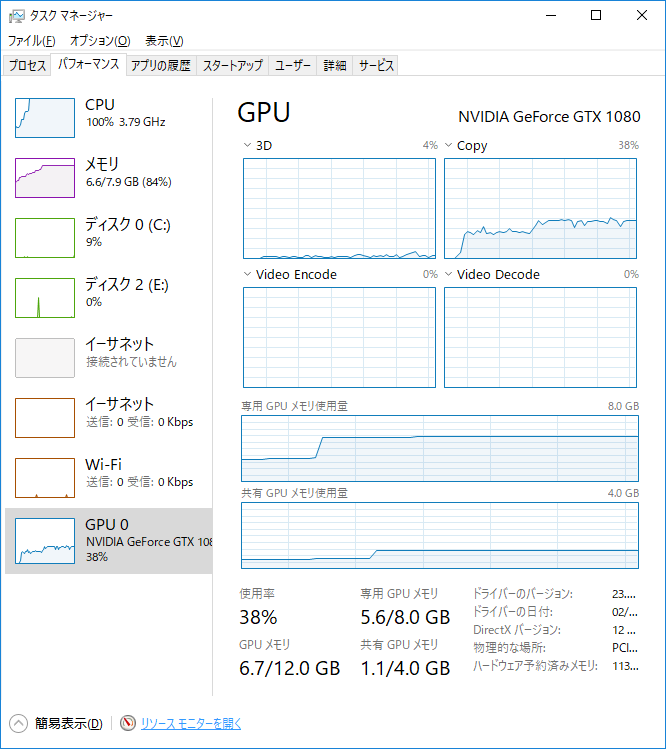

スレッドそれぞれ30%のメモリ割当にして2本並列で実行したところ、結果としては危なげなく動きました。1本あたりの効率は71.55%です。
2)3映像を並行処理
メモリ割当が30%のままではスレッドは3本起動しなかったので、25%に落として再チャレンジ。

結果としてはこれも危なげなく動きました。1本あたりの効率は57.28%です。
結果と感想
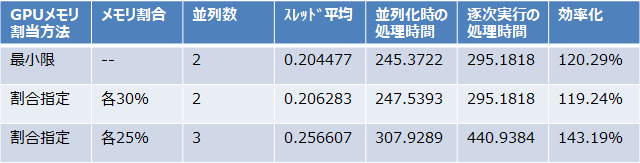
これまでの結果をまとめてみました。新しい項目は以下のように算出しています。
「並列化時の処理時間」=スレッド平均×並列数×1000(解析フレーム数)×1.2(起動時オーバーヘッドなど)
「逐次実行の処理時間」=25%または30%単独実行の基準値×並列数×1000(解析フレーム数)
「効率化」=「逐次実行の処理時間」÷「並列化時の処理時間」
一番効率化がいいのは25%の割合指定で3並列化したものですね。1本ずつ順番に3本実行すると440秒かかるものを並列化で307秒で処理できます。なお上記の指揮で「起動時オーバーヘッドなど」として1.2倍しているのは、Kerasとtensorflowのロードが複数同時にできず、ここだけは逐次処理になってしまうからです。他にうまいやり方があるかもしれない?
私の感想としては、
・メモリ割り当てを最小限にする方式はヤバイ。間違えて3個目を立てるとすべて死ぬ。
・自分で使うなら、割合指定方式。こっちの方が使いやすくて安全(他スレッドが死なない)な気がする。
・並列化は期待したほど早くないかも?
・MPSやNVIDIAの仮想環境もテストしてみたい。
・パフォーマンスを落とさず並行処理できる本命は仮想環境なのかなあ?
・高いTeslaだとパフォーマンスを落とさず並行処理できる…と思うのは実は夢かも?
・いずれにせよGPUをケチって1時間の映像を1時間以内で処理するのはまだ工夫が必要らしい
以上です。最後までお読みいただき、ありがとうございました。
関連記事
・ケチ上等!GPU費用を節約するため4台のカメラ映像を1度に映像解析するのに苦労した
・[ディープラーニングで故障車両を発見するのに苦労した]
(https://qiita.com/ComputerVision/items/4f377bc3eb5e601676ac)
・[ディープラーニングで映像から速度を正確に算出するのに苦労した]
(https://qiita.com/ComputerVision/items/d5358632209c67dab325)
・ディープラーニングによる映像解析で車両をトラッキングするのに苦労した
・ディープラーニングで交通量調査の映像解析精度を上げるのに苦労した
・SSD_KerasをWindowsで使って交通量調査できるか試してみた
・YOLO V3を使った交通量調査ソフトを作って苦労した