今回の記事では、TensorFlow Hub(TF-HUB)を使った花画像の分類を試してみます。プログラムについてはTF-HUBの公式チュートリアルがわかりやすかったのでそれを参考にしています。また、一連のプロセスの中で独自に画像データを収集し、それを教師データにして学習できるかもやってみます。
TensorFlow Hubについて
<概要>
TensorFlow Hubという機械学習の事前学習済みモデルが集まった書庫のようなリポジトリがあります。これは、機械学習モデルの再利用可能な部分を公開・利用・発見するためのライブラリです。TensorFlowグラフの自己完結型のピースで、転移学習という手法によって、異なるタスク間で重みや資産を再利用する事ができます。
転移学習のメリットは次の通りです。
・小さいデータセットでモデルを訓練できる
・汎化を改善する
・学習のスピードを上げる
<トップページ>
では、実際にTensorFlow Hub(TF-HUB)を試してみましょう。
以下のURLからTF-HUBのページにアクセスします。

TF-HUBのトップページが表示されました。現在(2019/3/28)だと227個の事前学習済みモデルが登録されています。内訳は以下の通りです。
入力データの形式:テキスト(46)、画像(179)、動画(2)
アルゴリズム:テキスト埋め込み(46)、画像分類(71)、画像特徴ベクトル(71)、画像生成(22)、画像その他(物体検出(2)、ランドマーク検出(1)、画像拡張(6))、動画分類(2)
検索窓から「tf2」と検索すると、「TensorFlow 2.0 Preview」バージョンのモジュールが利用可能です。これはSavedModel 2.0フォーマットに対応しているため、ライブラリバージョンは、TensorFlow 2.0・TensorFlow Hub 0.3.0がインストールされた環境で実行するようにしてください。
<モデルの検索>
さて、実際にモデルを検索してみましょう。
検索窓から「tf2」、モジュールタイプが「image-feature-vector」で絞り込むと以下の2つが出てきます。これらのモデルについては後述しますが、ここでは2行目の「tf2-preview/inception_v3/feature_vector」を選択してください。
事前学習済みモデル「tf2-preview/inception_v3/feature_vector」の概要ページ
が表示されました。モデルの特徴や、掲載された論文、元となったデータセットの説明等が載っています。画面右部の「Open Colab notebooks」からColaboratoryのチュートリアルページへアクセスできます。
Colaboratoryの設定
<GPUの有効化>
「ランタイム」→「ランタイムのタイプを変更」から「ノートブックの設定」が開けます。「ランタイムのタイプ」は「Python3」、「ハードウェアアクセラレータ」は「GPU」を選択し、保存してください。

Colaboratoryの使い方についてはこちら↓の記事が詳しいので参照してみてください。
【秒速で無料GPUを使う】深層学習実践Tips on Colaboratory
https://qiita.com/tomo_makes/items/b3c60b10f7b25a0a5935
<ライブラリのインストール>
TensorFlowのGPU用ライブラリをインストールします
―――――――――――――――――――――――――――――――
!pip install -U --pre tensorflow-gpu --quiet
―――――――――――――――――――――――――――――――
TF-HUB用のライブラリをインストールします
―――――――――――――――――――――――――――――――
!pip install 'tensorflow-hub>=0.3'
―――――――――――――――――――――――――――――――
インストール後の諸情報を確認してみましょう
―――――――――――――――――――――――――――――――
from future import absolute_import, division, print_function
import os
import matplotlib.pylab as plt
import numpy as np
import tensorflow as tf
import tensorflow_hub as hub
print("Version: ", tf.version)
print("Eager mode: ", tf.executing_eagerly())
print("Hub version: ", hub.version)
print("GPU is", "available" if tf.test.is_gpu_available() else "NOT AVAILABLE")
―――――――――――――――――――――――――――――――
結果
―――――――――――――――――――――――――――――――
Version: 2.0.0-alpha0
Eager mode: True
Hub version: 0.3.0
GPU is available
―――――――――――――――――――――――――――――――
バージョンは最新版の「2.0.0-alpha0」、Eagerモードはオン、GPUが有効化されている事がわかります。
<モジュールの選択>
次に、TF-HUBのモジュールを選択しましょう。事前学習済みモデルにはいくつかの種類があり、現在TF2.0用で公開されている画像特徴ベクトル(image-feature-vector)の抽出用には「inception_v3」と「mobilenet_v2」の二つがあります。 これらはTF-Slimの実装を使っており、こちらの比較表から「inception_v3」の方が精度が高そうなので、今回はこれを使います。モジュールに関しては、Colaboratoryの画面UIからプルダウンで選べます。バッチサイズは「64」として進めます。
https://github.com/tensorflow/models/blob/master/research/slim/README.md#pre-trained-models
―――――――――――――――――――――――――――――――
module_selection = ("inception_v3", 299, 2048) #@param ["("mobilenet_v2", 224, 1280)", "("inception_v3", 299, 2048)"] {type:"raw", allow-input: true}
handle_base, pixels, FV_SIZE = module_selection
MODULE_HANDLE ="https://tfhub.dev/google/tf2-preview/{}/feature_vector/2".format(handle_base)
IMAGE_SIZE = (pixels, pixels)
print("Using {} with input size {} and output dimension {}".format(
MODULE_HANDLE, IMAGE_SIZE, FV_SIZE))
BATCH_SIZE = 64 #@param {type:"integer"}
―――――――――――――――――――――――――――――――
結果
―――――――――――――――――――――――――――――――
Using https://tfhub.dev/google/tf2-preview/inception_v3/feature_vector/2 with input size (299, 299) and output dimension 2048
―――――――――――――――――――――――――――――――
入力に使う画像のサイズは299×299ピクセル、出力次元は2048となっています。
<教師データの準備>
次に、学習に使う画像の教師データをダウンロードしましょう。「tf.keras.utils.get_file」関数はデフォルトで「~/.keras」配下に画像をダウンロードしますが、「cache_dir」で任意のディレクトリを指定する事もできます。Colaboratoryはデフォルトで「sample_data」にサンプルデータセットを持っているため、今回はそちらに追加する形にします。
―――――――――――――――――――――――――――――――
data_dir = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True,
cache_dir="sample_data") #キャッシュ保存用ディレクトリを指定
―――――――――――――――――――――――――――――――
ダウンロードはすぐに完了します。
変数「data_dir」にはダウンロード先のパス(「’sample_data/datasets/flower_photos’」)が文字列で格納されています。
Colaboratory画面左部のパネル→「ファイル」タブからディレクトリ構成を確認できます。

ダウンロードした画像を可視化してみましょう。
―――――――――――――――――――――――――――――――
#matplotlibを日本語化するライブラリ
!pip install japanize-matplotlib
―――――――――――――――――――――――――――――――
―――――――――――――――――――――――――――――――
import cv2
from matplotlib import pyplot as plt
import glob
import os
import pandas as pd
import japanize_matplotlib
指定したディレクトリから画像のパスとラベルのセットを抽出する
def create_data(path, sample_size):
targets = []
images = []
for label in glob.iglob(path):
if "LICENSE.txt" in label:
continue
count = 1
for image in enumerate(glob.iglob(label + "/*")):
targets.append(label.split("/")[-1])
images.append(image[1])
count += 1
if count > sample_size:
break
df = pd.DataFrame(list(zip(targets, images)), columns=["label", "path"])
df = df.sample(frac=1).reset_index(drop=True)
df_ = df.groupby('label').head(sample_size).reset_index(drop=True).sort_values('label')
targets_ = [x[0] for x in df_.values.tolist()]
images_ = [x[1] for x in df_.values.tolist()]
return targets_, images_
画像を表示する
def show_images(target, images, sample_size=10, figsize=(20,18)):
class_num = len(set(target))
fig, axes = plt.subplots(class_num, sample_size, figsize=figsize,
subplot_kw={'xticks': (), 'yticks': ()})
for target, image, ax in zip(target, images, axes.ravel()):
obj = cv2.imread(image)
if obj is None:
continue
obj = cv2.cvtColor(obj, cv2.COLOR_BGR2RGB)
ax.imshow(obj)
ax.set_title(target)
sample_size=4
target, images = create_data("sample_data/datasets/flower_photos/*", sample_size)
show_images(target, images, sample_size, figsize=(18,18))
―――――――――――――――――――――――――――――――

これをkerasの前処理用モジュール「ImageDataGenerator」で読み込むことにしましょう。先ほど画像のダウンロード先に指定した「data_dir」から、画像ファイルのパスとラベル名を対で読み込む事ができます。トレーニング画像の拡張(水増し)をしたい場合は、「do_data_augmentation」フラグを「True」に設定してください。
―――――――――――――――――――――――――――――――
datagen_kwargs = dict(rescale=1./255, validation_split=.20)
valid_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
**datagen_kwargs)
valid_generator = valid_datagen.flow_from_directory(
data_dir, subset="validation", shuffle=False,
target_size=IMAGE_SIZE, batch_size=BATCH_SIZE)
do_data_augmentation = True #@param {type:"boolean"}
if do_data_augmentation:
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rotation_range=40,
horizontal_flip=True,
width_shift_range=0.2, height_shift_range=0.2,
shear_range=0.2, zoom_range=0.2,
**datagen_kwargs)
else:
train_datagen = valid_datagen
train_generator = train_datagen.flow_from_directory(
data_dir, subset="training", shuffle=True,
target_size=IMAGE_SIZE, batch_size=BATCH_SIZE)
―――――――――――――――――――――――――――――――
―――――――――――――――――――――――――――――――
Found 731 images belonging to 5 classes.
Found 2939 images belonging to 5 classes.
―――――――――――――――――――――――――――――――
トレーニング用/検証用に5クラスの画像が準備された事がわかります。
<モデルの定義>
次に、モデルの定義をしてみましょう。TF-HUBのモジュールでは、転移学習とファインチューニングのいずれかをフラグによって切り替える事ができます。速度を重視したい場合は転移学習、精度を重視したい場合はファインチューニングを選ぶと良いようです。今回はデフォルト(「do_fine_tuning」 = False)の転移学習で試してみましょう。
―――――――――――――――――――――――――――――――
do_fine_tuning = False #@param {type:"boolean"}
―――――――――――――――――――――――――――――――
次は、tf.keras.SequentialのAPIを使って、層を積み重ねていきます。最初にhub.KerasLayerでモジュールを読み込み、ドロップアウト層、全結合層と繋げましょう。ネットワークが組み終わったら、モデルをビルドします。今回のTF2.0のアップデートにおいては、こういった部分の記述の簡略化がポイントになったようです。
―――――――――――――――――――――――――――――――
print("Building model with", MODULE_HANDLE)
model = tf.keras.Sequential([
hub.KerasLayer(MODULE_HANDLE, output_shape=[FV_SIZE],
trainable=do_fine_tuning),
tf.keras.layers.Dropout(rate=0.2),
tf.keras.layers.Dense(train_generator.num_classes, activation='softmax',
kernel_regularizer=tf.keras.regularizers.l2(0.0001))
])
model.build((None,)+IMAGE_SIZE+(3,))
model.summary()
―――――――――――――――――――――――――――――――
結果
―――――――――――――――――――――――――――――――
Building model with https://tfhub.dev/google/tf2-preview/inception_v3/feature_vector/2
Model: "sequential"
Layer (type) Output Shape Param #
keras_layer (KerasLayer) multiple 21802784
dropout (Dropout) multiple 0
dense (Dense) multiple 10245
Total params: 21,813,029
Trainable params: 10,245
Non-trainable params: 21,802,784
―――――――――――――――――――――――――――――――
最適化手法や損失関数、評価指標を指定し、コンパイルします。
―――――――――――――――――――――――――――――――
model.compile(
optimizer=tf.keras.optimizers.SGD(lr=0.005, momentum=0.9),
loss=tf.keras.losses.CategoricalCrossentropy(label_smoothing=0.1),
metrics=['accuracy'])
―――――――――――――――――――――――――――――――
<学習の実行・評価>
以上で準備は整いました。いよいよトレーニングを開始してみます。
―――――――――――――――――――――――――――――――
steps_per_epoch = train_generator.samples // train_generator.batch_size
validation_steps = valid_generator.samples // valid_generator.batch_size
hist = model.fit_generator(
train_generator,
epochs=5, steps_per_epoch=steps_per_epoch,
validation_data=valid_generator,
validation_steps=validation_steps).history
―――――――――――――――――――――――――――――――
―――――――――――――――――――――――――――――――
Epoch 1/5
45/45 [==============================] - 91s 2s/step - loss: 1.5222 - accuracy: 0.3605 - val_loss: 1.3432 - val_accuracy: 0.6236
Epoch 2/5
45/45 [==============================] - 79s 2s/step - loss: 1.1092 - accuracy: 0.7630 - val_loss: 1.0514 - val_accuracy: 0.8054
Epoch 3/5
45/45 [==============================] - 78s 2s/step - loss: 1.0515 - accuracy: 0.8039 - val_loss: 1.0007 - val_accuracy: 0.8352
Epoch 4/5
45/45 [==============================] - 76s 2s/step - loss: 1.0130 - accuracy: 0.8250 - val_loss: 0.9916 - val_accuracy: 0.8295
Epoch 5/5
45/45 [==============================] - 77s 2s/step - loss: 0.9944 - accuracy: 0.8469 - val_loss: 0.9538 - val_accuracy: 0.8693
―――――――――――――――――――――――――――――――
5エポック回して、val_accuracyは0.8693となりました。学習曲線もプロットしてみましょう。
―――――――――――――――――――――――――――――――
plt.figure()
plt.ylabel("Loss (training and validation)")
plt.xlabel("Training Steps")
plt.ylim([0,2])
plt.plot(hist["loss"])
plt.plot(hist["val_loss"])
plt.figure()
plt.ylabel("Accuracy (training and validation)")
plt.xlabel("Training Steps")
plt.ylim([0,1])
plt.plot(hist["accuracy"])
plt.plot(hist["val_accuracy"])
―――――――――――――――――――――――――――――――
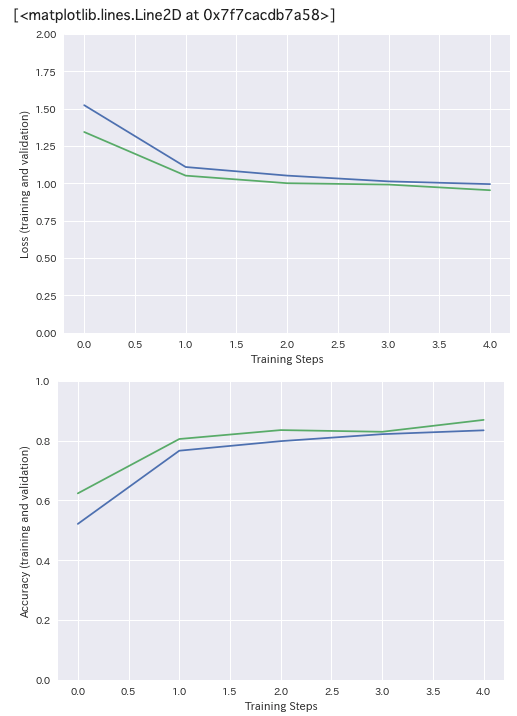
今回は学習用データが2939枚、検証用データが731枚という事であまりデータ量は多くないですが、なかなか良い精度が出たのではないでしょうか。
<オリジナルの教師データを追加し、画像分類してみる>
今度は、自分で教師データを準備してみましょう。色々と方法はあると思いますが、google_images_downloadというライブラリはさっと試す分には便利です。今回はこちらを使ってWeb上から画像を集めてみましょう。内部的にはseleniumなどを使ってスクレイピングしているようです。
<画像データの収集>
pipでライブラリをインストールします。
―――――――――――――――――――――――――――――――
!pip install google_images_download
―――――――――――――――――――――――――――――――
次に検索のプログラムを書いていきます。
引数「keywords」に収集したい画像の検索キーワードを入力できます。「,」で区切れば、それぞれが別フォルダとして指定のディレクトリにダウンロードされます。今回のチュートリアルで使っている「sample_data/datasets/flower_photos/」を、引数「output_directory」に設定しましょう。先ほど取得したデータセット「flower_photos」の5クラス(daisy, dandelion, roses, sunflowers, tulips)に、3クラス(アジサイ、アサガオ、リンドウ)追加します。後に使うテストデータと混ざらないようにするため、引数「time_range」に'{“time_min”:”01/01/2017″,”time_max”:”12/31/2017″}’を指定し、2017年の画像のみを対象とします。
―――――――――――――――――――――――――――――――
from google_images_download import google_images_download #importing the library
response = google_images_download.googleimagesdownload() #class instantiation
arguments = {"keywords":"アジサイ,アサガオ,リンドウ","limit":100,"print_urls":True, "output_directory":"sample_data/datasets/flower_photos/", "time_range":'{"time_min":"01/01/2017","time_max":"12/31/2017"}'} #creating list of arguments
paths = response.download(arguments) #passing the arguments to the function
print(paths) #printing absolute paths of the downloaded images
―――――――――――――――――――――――――――――――
ダウンロード中のログはこのように出ます。
―――――――――――――――――――――――――――――――
Item no.: 1 --> Item name = アジサイ
Evaluating...
Starting Download...
Image URL: https://upload.wikimedia.org/wikipedia/commons/thumb/1/15/Hydrangea_of_Shimoda_%E4%B8%8B%E7%94%B0%E3%81%AE%E3%81%82%E3%81%98%E3%81%95%E3%81%84_%282630826953%29.jpg/1200px-Hydrangea_of_Shimoda_%E4%B8%8B%E7%94%B0%E3%81%AE%E3%81%82%E3%81%98%E3%81%95%E3%81%84_%282630826953%29.jpg
Completed Image ====> 1. 1200px-hydrangea_of_shimoda_%e4%b8%8b%e7%94%b0%e3%81%ae%e3%81%82%e3%81%98%e3%81%95%e3%81%84_%282630826953%29.jpg
Image URL: https://storage.tenki.jp/storage/static-images/suppl/article/image/2/23/233/23311/1/large.jpg
Completed Image ====> 2. large.jpg
Image URL: https://www.jalan.net/news/img/2018/04/d3d77_0000806446_1-670x443.jpg
Completed Image ====> 3. d3d77_0000806446_1-670x443.jpg
Image URL: https://www.toho-u.ac.jp/sci/bio/column/j5mt8h000000bexy-img/200807_01.jpg
Completed Image ====> 4. 200807_01.jpg
Image URL: https://www.i-iro.com/wp-content/uploads/images/hydrangea-iro-2-680x420.jpg
Completed Image ====> 5. hydrangea-iro-2-680x420.jpg
Image URL: http://www.muse-park.com/wordpress/wp-content/themes/muse-park/img/seasonal-flower/flower05_01.jpg
Completed Image ====> 6. flower05_01.jpg
Image URL: http://www.hana300.com/ajisai98.jpg
・・・
―――――――――――――――――――――――――――――――
ダウンロード完了後、ファイル一覧から3クラス(アジサイ、アサガオ、リンドウ)が追加された事がわかります。今回は1クラスあたり100枚の画像を収集しましたが、より多くの画像を集めたい場合には検索キーワードを変えたり、オプションとしてseleniumをかますなどしてみてください。
再度画像を可視化してみましょう。
―――――――――――――――――――――――――――――――
sample_size=10
target, images = create_data("sample_data/datasets/flower_photos/*", sample_size)
show_images(target, images, sample_size)
―――――――――――――――――――――――――――――――

画像はColaboratoryのファイル一覧から一枚ずつ開き確認することもできるので、ノイズになりそうな画像は「ファイルを削除」するなどしてデータセットを整えてください。

<データの再読み込み>
データセットが更新されたので、これを使ってもう一度学習をしてみましょう。
―――――――――――――――――――――――――――――――
datagen_kwargs = dict(rescale=1./255, validation_split=.20)
valid_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
**datagen_kwargs)
valid_generator = valid_datagen.flow_from_directory(
data_dir, subset="validation", shuffle=False,
target_size=IMAGE_SIZE, batch_size=BATCH_SIZE)
do_data_augmentation = True #@param {type:"boolean"}
if do_data_augmentation:
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rotation_range=40,
horizontal_flip=True,
width_shift_range=0.2, height_shift_range=0.2,
shear_range=0.2, zoom_range=0.2,
**datagen_kwargs)
else:
train_datagen = valid_datagen
train_generator = train_datagen.flow_from_directory(
data_dir, subset="training", shuffle=True,
target_size=IMAGE_SIZE, batch_size=BATCH_SIZE)
―――――――――――――――――――――――――――――――
結果
―――――――――――――――――――――――――――――――
Found 788 images belonging to 8 classes.
Found 3172 images belonging to 8 classes.
―――――――――――――――――――――――――――――――
ImageDataGeneratorを使って再度画像の読み込みをすると、クラス数が8に増えている事がわかります。
<追加データで学習の実行>
先ほどのコードで再度学習を実行してみます。
―――――――――――――――――――――――――――――――
do_fine_tuning = False #@param {type:"boolean"}
print("Building model with", MODULE_HANDLE)
model = tf.keras.Sequential([
hub.KerasLayer(MODULE_HANDLE, output_shape=[FV_SIZE],
trainable=do_fine_tuning),
tf.keras.layers.Dropout(rate=0.2),
tf.keras.layers.Dense(train_generator.num_classes, activation='softmax',
kernel_regularizer=tf.keras.regularizers.l2(0.0001))
])
model.build((None,)+IMAGE_SIZE+(3,))
model.summary()
model.compile(
optimizer=tf.keras.optimizers.SGD(lr=0.005, momentum=0.9),
loss=tf.keras.losses.CategoricalCrossentropy(label_smoothing=0.1),
metrics=['accuracy'])
steps_per_epoch = train_generator.samples // train_generator.batch_size
validation_steps = valid_generator.samples // valid_generator.batch_size
hist = model.fit_generator(
train_generator,
epochs=5, steps_per_epoch=steps_per_epoch,
validation_data=valid_generator,
validation_steps=validation_steps).history
―――――――――――――――――――――――――――――――
注)途中、画像の読み込みに失敗する事がありますので、その場合は画像を削除してください。
―――――――――――――――――――――――――――――――
!rm "sample_data/datasets/flower_photos/アサガオ/95. marubarukou300.2.jpg"
―――――――――――――――――――――――――――――――
先程と同じように5エポック実行します。
―――――――――――――――――――――――――――――――
Epoch 1/5
49/49 [==============================] - 99s 2s/step - loss: 1.7797 - accuracy: 0.3707 - val_loss: 1.4744 - val_accuracy: 0.6185
Epoch 2/5
49/49 [==============================] - 90s 2s/step - loss: 1.3507 - accuracy: 0.7099 - val_loss: 1.2566 - val_accuracy: 0.7578
Epoch 3/5
49/49 [==============================] - 88s 2s/step - loss: 1.2364 - accuracy: 0.7621 - val_loss: 1.1531 - val_accuracy: 0.8151
Epoch 4/5
49/49 [==============================] - 86s 2s/step - loss: 1.1875 - accuracy: 0.7849 - val_loss: 1.1246 - val_accuracy: 0.8281
Epoch 5/5
49/49 [==============================] - 85s 2s/step - loss: 1.1651 - accuracy: 0.8123 - val_loss: 1.1044 - val_accuracy: 0.8581
―――――――――――――――――――――――――――――――
今度は、val_accuracyは0.8581となりました。追加したクラスに関してはノイズ画像の削除等しておらずそのまま使っているためか、若干下がってますね。学習曲線もプロットしてみましょう。
―――――――――――――――――――――――――――――――
plt.figure()
plt.ylabel("Loss (training and validation)")
plt.xlabel("Training Steps")
plt.ylim([0,2])
plt.plot(hist["loss"])
plt.plot(hist["val_loss"])
plt.figure()
plt.ylabel("Accuracy (training and validation)")
plt.xlabel("Training Steps")
plt.ylim([0,1])
plt.plot(hist["accuracy"])
plt.plot(hist["val_accuracy"])
―――――――――――――――――――――――――――――――
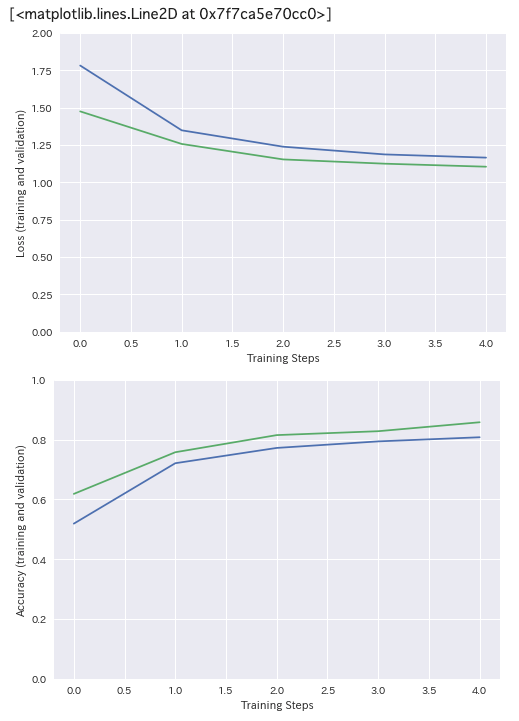
<テストデータで予測してみる>
モデルができたので、テストデータを使って分類を試してみましょう。先ほどの学習用データとは違う画像でテストしたいため、引数「time_range」に'{“time_min”:”01/01/2018″,”time_max”:”12/31/2018″}’を指定し、2018年の画像のみを対象とします。出力先ディレクトリ「output_directory」はテスト用のものを指定します。
―――――――――――――――――――――――――――――――
TEST_DATA_DIR = "test_data/datasets/flower_photos/"
!mkdir -p {TEST_DATA_DIR}
―――――――――――――――――――――――――――――――
―――――――――――――――――――――――――――――――
from google_images_download import google_images_download #importing the library
response = google_images_download.googleimagesdownload() #class instantiation
arguments = {"keywords":"アジサイ,アサガオ,リンドウ,dandelion,roses,tulips,daisy,sunflowers","limit":100,"print_urls":True, "output_directory":TEST_DATA_DIR,"time_range":'{"time_min":"01/01/2018","time_max":"12/31/2018"}'} #creating list of arguments
paths = response.download(arguments) #passing the arguments to the function
print(paths) #printing absolute paths of the downloaded images
―――――――――――――――――――――――――――――――
再度ImageDataGeneratorでテスト画像の読み込みを準備します。
―――――――――――――――――――――――――――――――
test_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
**datagen_kwargs)
test_generator = test_datagen.flow_from_directory(
TEST_DATA_DIR, shuffle=False,
target_size=IMAGE_SIZE, batch_size=BATCH_SIZE)
―――――――――――――――――――――――――――――――
―――――――――――――――――――――――――――――――
Found 778 images belonging to 8 classes.
―――――――――――――――――――――――――――――――
8クラス、778枚のテストデータが用意できました。
それではモデルの予測をしてみます。
―――――――――――――――――――――――――――――――
y_prob = model.predict_generator(test_generator, verbose=1)
―――――――――――――――――――――――――――――――
枚数も多くないのですぐに完了します。
それでは予測結果を可視化してみましょう。
―――――――――――――――――――――――――――――――
from sklearn import preprocessing
import pandas as pd
#予測確率をラベルに変換
#例: [[9.9109542e-01, 6.4130645e-04, 6.3536654e-04, 3.0492968e-03,8.3755807e-04, 1.0973219e-03, 1.1702350e-03, 1.4735168e-03]]→['daisy']
def prob_to_labels(y_prob, generator):
y_classes = y_prob.argmax(axis=-1)
labels = [x for x in generator.class_indices.keys()]
le = preprocessing.LabelEncoder()
le.fit(labels)
result = le.inverse_transform(y_classes)
return list(result)
#ラベルごとに指定した件数を取得
def filter_data(targets, generator, sample_size=10):
images = generator.filepaths
df = pd.DataFrame(list(zip(targets, images)), columns=["label", "path"])
df = df.sample(frac=1).reset_index(drop=True)
df_ = df.groupby('label').head(sample_size).reset_index(drop=True).sort_values('label')
targets_ = [x[0] for x in df_.values.tolist()]
images_ = [x[1] for x in df_.values.tolist()]
return targets_, images_
sample_size=10
targets = prob_to_labels(y_prob, test_generator)
targets, images = filter_data(targets, test_generator, sample_size)
show_images(targets, images, sample_size)
―――――――――――――――――――――――――――――――

テストデータに対してもまずまずの分類ができてそうです。今回自分で追加した3クラス(アサガオ、アジサイ、リンドウ)も結構良さそうですね。
<まとめ>
オリジナルの教師データを使う場合でも、tf.kerasのシーケンシャルなAPIによって、画像の読み込みから学習・予測までがシームレスに実行できる事がわかりました。TF-HUBには、昨年話題となった汎用言語表現モデルのBERTなど、画像以外にも様々なモデルがあります。是非みなさんも試してみてください。