この記事は
の続編vol.3です。
Webclassの更新を調べるツールを作ります。
スクレイピングライブラリを実験
エディター、Python環境とseleniumのインポートが終わった段階でまず何をするか。
いきなり目的のスクレイピングをしようと思っても右往左往するので少しスクレイピングをお試ししてみることにしました。
ログインが必要なサイトのスクレイピングはハードルが高いので、まず公開Webページのスクレイピングを実験します。
BeautifulSoupとかRequestsというライブラリを使用した記事はたくさんあるので一瞬で実装できます。どちらのライブラリも標準でインストールされていないのでインストールは必要です。 “win”+“R”→cmdでインストールです。
pip install beautifulsoup4
#末尾の4は現時点でのバージョンです
pip install requests
公開されているテンプレートコードを参照して、カスタマイズすることで大学のニュースの見出しを抽出しコマンドプロンプトにまとめて表示することが出来ました。感動!
各種ブラウザの検証ツール(デベロッパーツー)のセレクトモードを使えば任意の場所のHTMLソースが分かるので完璧です。(一部の動的なオブジェクトはこれでは取れない可能性があります...一旦requestsで取得したソースを印字すれば動的なオブジェクトなのか分かると思います。)
ここまでの話は実際のWebclassの更新検知ツールにはあんまり関係ないです。なぜならrequestsは指定したURLのHTMLソースを返してくれますが、ログインが必要なページの場合ログインページのHTMLソースが返ってきてしまい本来のコンテンツを取得できないのです。残念
使用ライブラリ決定
ということで一通りPythonのスクレイピングライブラリをお試ししたところで本題のWebclassのスクレイピングに戻ります。HTMLデータの抽出というとBeautifulSoupが有名ですが、seleniumでもデータ抽出できます。前回の記事のおまけの部分ですね。
しかしseleniumはブラウザを実際に操作しデータ抽出をしているので動作速度が遅いです。(加えて全部ブラウザの実動作で抽出するのは個人的にスマートだと思わない。)
ということでseleniumはログイン画面のみに、BeautifulSoupは目的のコンテンツのデータ抽出に特化することとしました。結果論ですが最終的に完成したツールにrequestsライブラリは使ってません。
ログイン処理の実装
流れは以下の通りです。
- Webclassのページをドライバーで開くように指示
- 自動的に大学のポータルログイン画面へ移動(大学側の仕様)
- ID、パスワード入力フォームを探し、入力
- ログインボタンを探しクリック
- 自動的にWebclassのログイン画面に移動(大学側の仕様)
- ID、パスワード入力フォームを探し、入力
- ログインボタンを探しクリック
- Webclassのホーム画面へ遷移完了
driver.get('https://e-learning.〜〜ac.jp/webclass/')
#実際には大学のポータルログイン画面に転送される
sleep(2)
id_element_s = driver.find_element(By.ID,'floatingInput')
id_element_s.send_keys(ID)
pw_element_s = driver.find_element(By.ID,'floatingPassword')
pw_element_s.send_keys(PW)
login_button_s = driver.find_element(By.CLASS_NAME,'button')
login_button_s.click()
sleep(2)
#以下Webclassのログイン画面
id_element_w = driver.find_element(By.ID,'username')
id_element_w.send_keys(ID)
pw_element_w = driver.find_element(By.ID,'password')
pw_element_w.send_keys(PW)
login_button_w = driver.find_element(By.ID,'LoginBtn')
login_button_w.click()
直接WebclassのURLへ飛ぶようにドライバーへ指定していますが、実際には大学のポータルログイン画面へ転送されています。最初から転送される前提でドライバーにURLを渡してログインしています。
最終的な完成版ではログイン画面へ遷移出来なかった場合へのエラー対処を加えていますが、おおよその流れは先程のコードが中心です。
できれば入力フォームやログインボタンの指定はIDで行いたいのですが、IDが無い要素はclass名指定しています。今回はclass名重複が無いことを確認しましたが、ID名の方が重複しにくいので安心だと思います。
コース名とコースURLを抽出
学期だけでなく、ターム制の授業も含めて3ヶ月に一度ほどプログラムコードを変更するのは面倒なので、コード側で履修講義や学期変更に対応出来るようにします。
Webclassのホーム画面には現在登録されているコース一覧が時間割のような表形式で表示されるのでここから教科名とそのURLを抽出してリスト化します。
この作業の時点ではログイン処理は終わっているので、BeautifulSoup・find_allメソッドで行います。
ここでリスト化された「コース名」「コースURL」を別で作成する更新を調べる関数に引き渡します。
更新を調べる関数
先程の「コース名」「コースURL」を受け取ります。
今回の更新検知対象は、
- タイムラインの内容(日付も含む)
- 課題・資料・アンケート等のメインコンテンツ(コンテンツ名・コンテンツの種類名・有れば実行可能期間)
です。
流れは以下の通りです。
-
受け取ったコースURLをもとにページを開き、タイムラインの内容(日付も含む)を取得する。
-
コース名のタイムラインに紐付けられたcsvファイルがあれば開き、先程取得した最新のタイムラインの内容と差異があれば、更新ありなので、差異の部分を変数に格納する。
csvファイルは最新のタイムラインの内容に書き換え閉じます。 -
コース名のコンテンツに紐付けられたcsvファイルがあれば開き、先程取得した最新のコンテンツの内容と差異があれば、更新ありなので、差異の部分を変数に格納する。
実行可能期間は正規表現利用して、いい感じに修正します。
csvファイルは最新のコンテンツの内容に書き換え閉じます。 -
ここまでの差異を格納した変数を返す。
csvが存在しないということは新規コースの可能性があるということなので変数には“新規コースの可能性”という文字列を入れます。
with open('~.csv', 'w',newline='',encoding='utf_8')とすればコンテンツがないコースにも空のファイルが出来ます。
私の確認が間違っていなければ、課題・資料・アンケート等のメインコンテンツの内容はhtmlのソースにそのまま書かれているのですが、タイムラインの内容はページを読み込んで若干タイムラグがあり動的に表示されているようで、sleep()処理を挟まないとソースコードにタイムラインの情報が含まれなかったので厄介でした。
更新を通知する 〜LINE Notify〜
各コースごとに上記の更新を調べる関数を適用し、返ってきた変数の文字列を結合します。これが更新の内容になるわけです。
どのように通知するかですが、この手の場合Slackが用いられることが多いようです。しかし、私自身がSlackを入れていないため、今回はLINEを利用することにしました。
LINE Notifyは個人で使っているくらいでは、余裕で無料枠内に収まるので太っ腹サービスだと思います。
LINEに自分だけのグループを作成します。そしてLINE Notifyの公式ページにログインしてAPIのトークンを取得します。適用するトークルームを自分だけのグループすれば自分だけに通知されます。
LINE NotifyのAPIをPythonで利用する記事はウェブ上にかなり多いので、他の方の参考にしました。ここで送信する内容は、先程の更新差異を結合した変数とすれば、準備は完了です。
ひとまず完成
ここまでで完成したプログラムを実行すると、このような形で通知できます。モザイクの部分は教科名です。
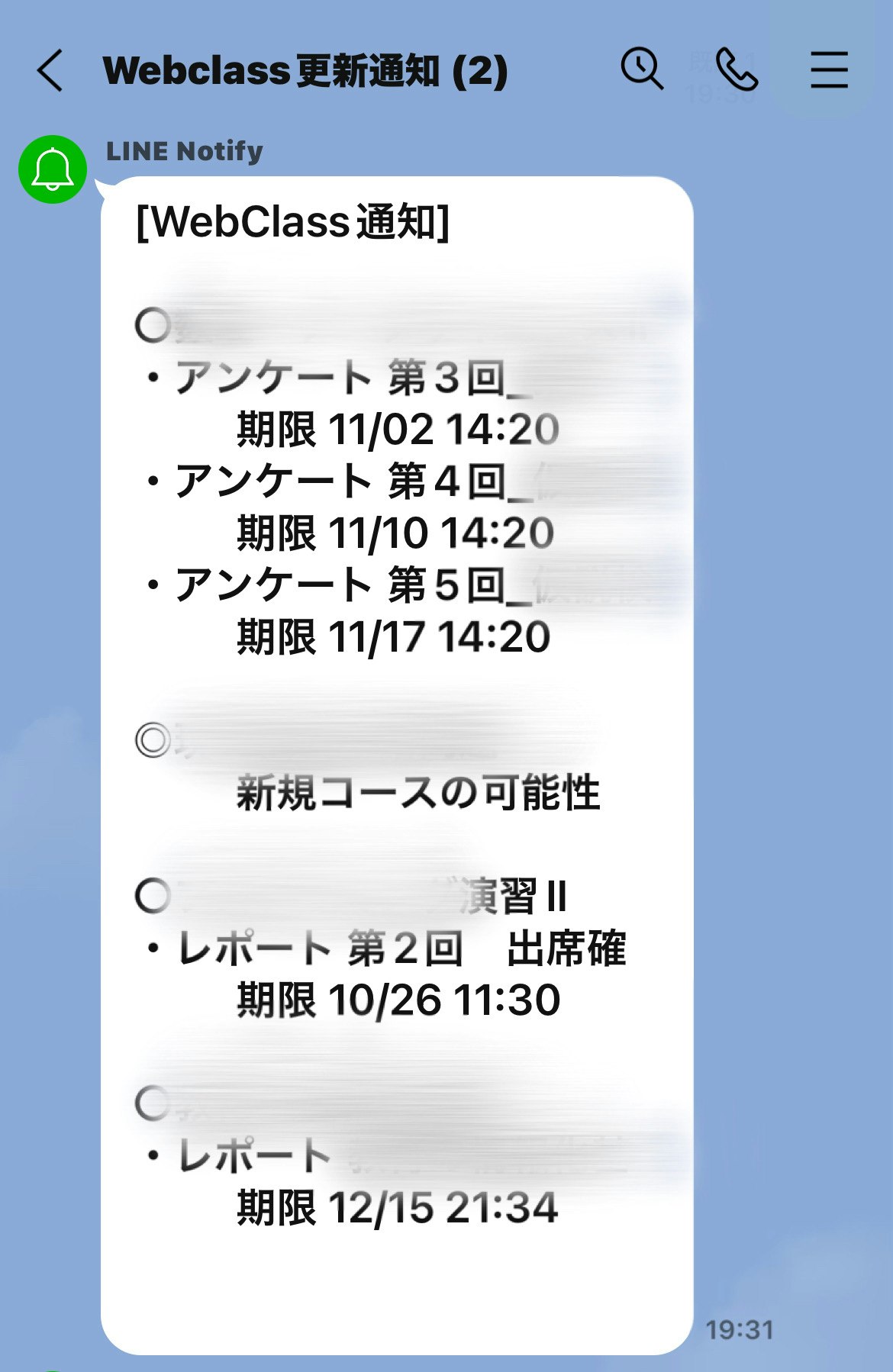
次はスクレイピングエラーが出た場合と、更新差異がなかった時通知です。
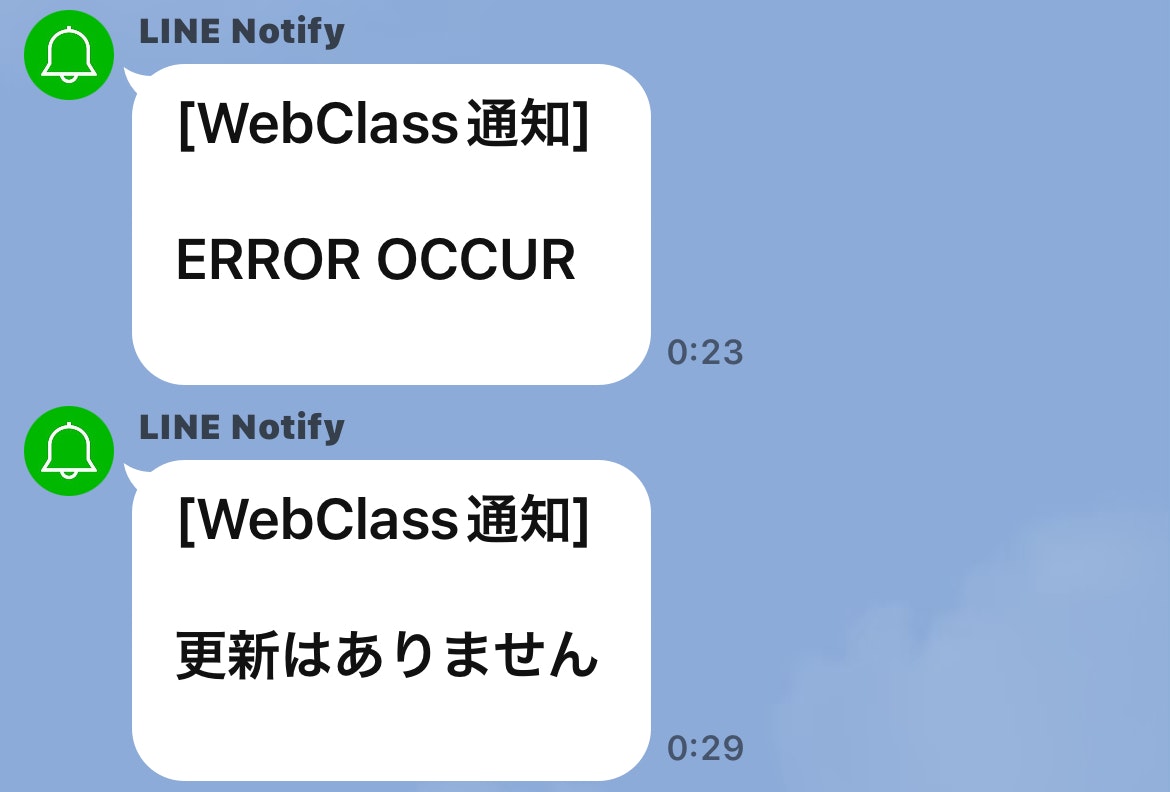
このプログラムを手動で実行すればこのように通知がきます。このPythonファイルを実行するバッチファイル(.bat)をデスクトップに置いておけばダブルクリックで更新チェックと通知を行うことができます。
定期的にチェックを行いたい時は、ウィンドウズのタスクスケジューラ機能を利用すれば、自動実行できます。(パソコンが常にインターネット環境につながっていればの話ですが...)
続編に向けて
駆け足でここまで完成させましたが、まだまだ課題が残ります。
- やっぱりGUI(いわゆる操作画面)を作りたい
- パソコンが常にインターネットにつながっているとは限らないため、タスクスケジューラ機能があまり実用的ではない。
☝️これは手持ちのiPhoneでPythonファイルを実行できれば解決するのですが、少し面倒くさい。
そんなこんなでまだソフトウェア化やクラウド化、スマホのネイティブアプリ化なんかを目指して続編に続きます。