はじめに
仕事でアンケート収集する機会があり、自由回答形式の分析が面倒なので何かいい方法がないかと探している所で「ネガポジ分析」ができる「極性辞書」の存在を知ったので試してみようと思いました。今回は練習として、自分が好きなミスチルの歌詞を分析してみました。
ネガポジ分析の流れ
分析の流れとしては、
- 歌詞を Janome で形態素解析
- 形態素解析した単語に 単語感情極性対応表 を使ってネガポジ度を付与
- 曲ごとにネガポジ度の平均値を算出
という流れで進めます。
単語感情極性対応表
分析を始める前に、まずは使用する極性辞書の中身を確認しておきます。
日本語の極性辞書としては、以下の2つが有名です。
「日本語評価極性辞書」は、検証してみましたが、あまり精度良く分類できませんでした。
原因としてはいくつかありますが、原因のうちのひとつとして収録されている単語数が少なく、評価できなかった単語が多かったということがあります。日本語評価極性辞書は「名詞編」と「用言編」があり、「名詞編」には13,314の名詞、「用言編」には5,280の動詞や形容詞が収録されています。
対して、「単語感情極性対応表」はリソースに「岩波国語辞書(岩波書店)」を使用しており、55,125の単語が含まれています。
また「日本語評価極性辞書」の場合は、単語を「ポジティブ」か「ネガティブ」といった分け方をしていますが、「単語感情極性対応表」は -1.0 を最もネガティブ、 +1.0 を最もポジティブとして -1.0 から +1.0 で単語のネガポジ度を数値化しています。
「単語感情極性対応表」は上記のリンクからダウンロードでき、中身は以下のようになっています。
優れる:すぐれる:動詞:1
良い:よい:形容詞:0.999995
喜ぶ:よろこぶ:動詞:0.999979
褒める:ほめる:動詞:0.999979
めでたい:めでたい:形容詞:0.999645
賢い:かしこい:形容詞:0.999486
善い:いい:形容詞:0.999314
適す:てきす:動詞:0.999295
天晴:あっぱれ:名詞:0.999267
祝う:いわう:動詞:0.999122
功績:こうせき:名詞:0.999104
・
・
・
今回は一番左の単語名と一番右のスコアのみを使用します。後で使いやすいように辞書型にしておきます。
import pandas as pd
# 極性辞書をデータフレームで読み込み
df_dic = pd.read_csv('pn_ja.dic', sep=':', names=("Word", "読み", "品詞", "Score"), encoding='shift-jis')
keys = df_dic["Word"].tolist()
values = df_dic["Score"].tolist()
dic = dict(zip(keys, values))
歌詞を Janome で形態素解析
日本語を形態素解析できる有名なライブラリは「Janome」と「Mecab」がありますが、「Janome」がpipで簡単にインストールできるので「Janome」を使いました。
pip install janome
今回は2021年10月時点で発売されている全てのミスチルの歌詞を格納したデータフレームを用意しました。曲名のカラム名は「曲名」、歌詞のカラム名は「歌詞」としています。
そのデータフレーム内の全ての歌詞を形態素解析します。
今回は複合名詞、動詞、形容詞を歌詞から抽出します。複合名詞とは、例えば「自然言語処理」を形態素解析すると、「自然」、「言語」、「処理」と分類されますが、複合名詞で分類すると「自然言語処理」と分類されます。
from janome.tokenizer import Tokenizer
from janome.analyzer import Analyzer
from janome.charfilter import *
from janome.tokenfilter import *
# 歌詞をデータフレームからリストに変換
song_info = df_file[["曲名", "歌詞"]]
t = Tokenizer()
song_list = []
for song_name, song_lyrics in zip(song_info['曲名'], song_info['歌詞']):
# 複合名詞を抽出
a = Analyzer(token_filters=[CompoundNounFilter()])
result = [token.base_form for token in a.analyze(song_lyrics) if token.part_of_speech.split(',')[0] in ['名詞']]
# 動詞と形容詞を抽出
result2 = [token.base_form for token in t.tokenize(song_lyrics)
if token.part_of_speech.split(',')[0] in ['動詞','形容詞']]
result.extend(result2)
result_list = [song_name, result]
song_list.append(result_list)
分類した単語の中には「ん」や「よう」のような、それ単体では意味が分からない単語も含まれているので分析対象外にしておきます。管理がしやすいように、名詞、動詞、形容詞に分けて対象外の単語をリスト化しておきます。
これで、曲ごとに含まれている単語をリスト化することができたので、後でネガポジ度を計算するために曲ごとの単語数をリストに加えておきます。
for song in song_list:
for stopword in stopwords:
song[1] = [i for i in song[1] if i != stopword]
song_word_num = len(song[1])
song.append(song_word_num) # song[2]
単語感情極性対応表 を使ってネガポジ度を付与
歌詞に含まれている単語が「単語感情極性対応表」に含まれている場合はそのスコアを追加します。辞書に単語が無い場合はNoneがリストに追加されます。
# 辞書で判定
results = []
for sentence in song[1]:
word_score = []
score = dic.get(sentence)
word_score = (sentence, score)
results.append(word_score)
# 判定を曲情報に追加
song.append(results)
曲ごとにネガポジ度の平均値を算出
上記で歌詞に含まれている単語に「単語感情極性対応表」でネガポジ度を与えることができたので、曲ごとのネガポジ度を算出します。曲ごとのネガポジ度は2パターン算出してみます。
- 辞書に無い単語は無かったものとしてスコアを算出する(スコア1)
- 辞書に無い単語はスコア 0 として算出する(スコア2)
「単語感情極性対応表」は -1.0 と最もネガティブ、+1.0 を最もポジティブとしてスコアを出しているので、0 はポジティブでもネガティブでもないニュートラルな単語という判定になります。よって、2番目のスコアが正しい算出方法とは言えませんが、1番目の算出方法でも適切な分類結果にならないと推測したため、2番目でもスコアを出してみました。
1番目の算出方法で適切な分類結果にならないパターンとしては、辞書に含まれていない単語が歌詞中に多い場合です。この場合、分類された数少ない単語でネガポジ度を算出するため、歌詞全体を捉えた分析とは言えません。
# 曲のスコアを2パターンで判定。「Noneを含むパターン」と「Noneを含まないパターン」
score = 0
score1 = 0
score2 = 0
for word in song[3]:
if word[1] != None:
score += word[1]
score1 = score / song[2] # スコアの合計 / 全形態素数
cnt = sum(not (i[1] == None) for i in song[3]) # Noneを含まない形態素数
score2 = score / cnt # スコアの合計 / Noneを含まない形態素数
# スコアを曲情報に追加
song.append(cnt)
song.append(score1)
song.append(score2)
結果を確認する
スコア1のポジティブ上位5曲を見てみます。
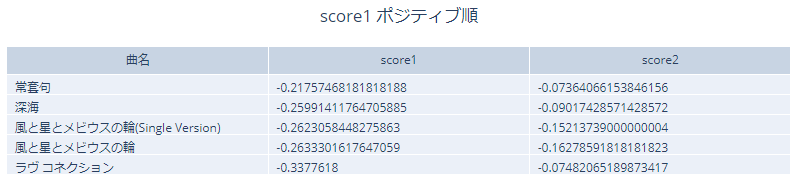
ポジティブというより、割とネガティブな印象の曲が多いです。そもそもポジティブ1位の曲がスコアがマイナスなので、全曲がネガティブという結果になっています。
1位の「常套句」の分類結果を見てみます。
[('君', None), ('僕', None), ('不安', -0.8296190000000001), ('今日', 0.172375), ('明日', -0.600093), ('想い', None),
('君', None), ('君', None), ('何', None), ('気分', -0.651613), ('君', None), ('君', None), ('君', None), ('君', None),
('君', None), ('...」', None), ('君', None), ('君', None), ('何', None), ('君', None), ('君', None), ('君', None),
('今日', 0.172375), ('悲しみ', -0.9992409999999999), ('間', -0.800953), ('君', None), ('君', None), ('何', None),
('気分', -0.651613), ('君', None), ('君', None), ('君', None), ('君', None), ('君', None), ('思う', -0.9023389999999999),
('寂しい', -0.999028), ('付く', -0.999763), ('会う', None), ('会う', None), ('会う', None), ('会う', None),
('愛す', 0.992131), ('思う', -0.9023389999999999), ('美しい', 0.9928879999999999), ('言う', None), ('決まる', None),
('膨れる', -0.928492), ('からかう', -0.849356), ('会う', None), ('会う', None), ('想う', None), ('会う', None),
('会う', None), ('愛す', 0.992131), ('嬉しい', 0.998871), ('揺れる', -0.834046), ('狂おしい', -0.143181), ('会う', None),
('会う', None), ('会う', None), ('会う', None), ('愛す', 0.992131), ('会う', None), ('会う', None), ('愛す', 0.992131)]
全単語数が65個に対して分類結果がNone(辞書に無い)言葉が43個あります。歌詞に含まれている単語(名詞、動詞、形容詞)の約34%しか分析に使えていません。このような状況を考慮して、スコア2も見てみます。
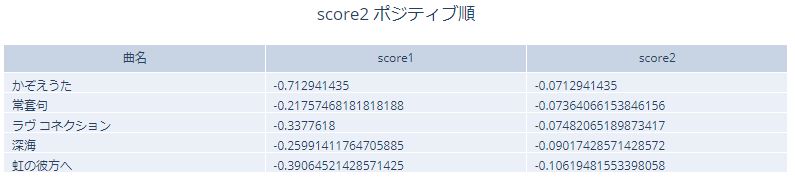
こちらもポジティブ、ネガティブ混ざっていて、うまく分析できていません。1位の「かぞえうた」の分類結果を見てみます。
[('うた', None), ('なに', None), ('なに', None), ('やみ', None), ('ひとつふたつ', None), ('ひとつ', None),
('こころ', None), ('あなた', None), ('なん', None), ('かなしみ', None), ('ひとつふたつ', None), ('ひとつ', None),
('ぼう', None), ('うた', None), ('むりなんかしなくてもひとりふたりもうひとりと', None), ('いつか', None),
('ょにうたいたいなえがおのうた僕ら', None), ('以上', -0.5695720000000001), ('風', -0.9796440000000001), ('稲穂', None),
('なに', None), ('ひとつふたつ', None), ('ひとつ', None), ('あなた', None), ('ぼう', None), ('うたひとつふたつ', None),
('ひとつ', None), ('びににたきえない', None), ('ぼう', None), ('うた', None), ('かぞえる', None), ('かぞえる', None),
('かぞえる', None), ('さがしあてる', None), ('とえる', None), ('たとえる', None), ('こえる', None), ('わすれる', None),
('ふりだす', None), ('はじめる', None), ('わらえる', None), ('わらえる', None), ('つられる', None), ('いっす', None),
('思う', -0.9023389999999999), ('脆い', -0.9953350000000001), ('小さい', None), ('弱い', None), ('揺れる', -0.834046),
('柔らかい', None), ('たくましい', None), ('強い', None), ('信じる', 0.00328739), ('かぞえる', None), ('かぞえる', None),
('こごえる', None), ('うむ', None), ('かぞえる', None), ('さがしあてる', None), ('ゆれる', None)]
全単語数が60個に対して、分類できたのが6個のみです。歌詞がほぼひらがなであったため分類できませんでした。辞書を使用する際に、読みも考慮に入れたほうがいいという結果になりました。
今回の分類結果は全体がネガティブなスコアなので、分類できていない単語数が多い方が0に近づいてポジティブ上位となってしまうので、やはりこのスコア2の算出方法は適切ではありません。
スコア1のネガティブ上位5曲を見てみます。
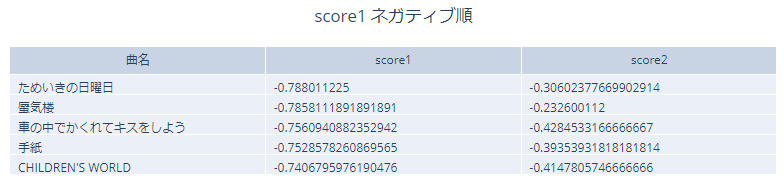
こちらもやはりうまく分類できていません。ネガティブな曲が多いですが、ポジティブな曲も混ざっている印象です。
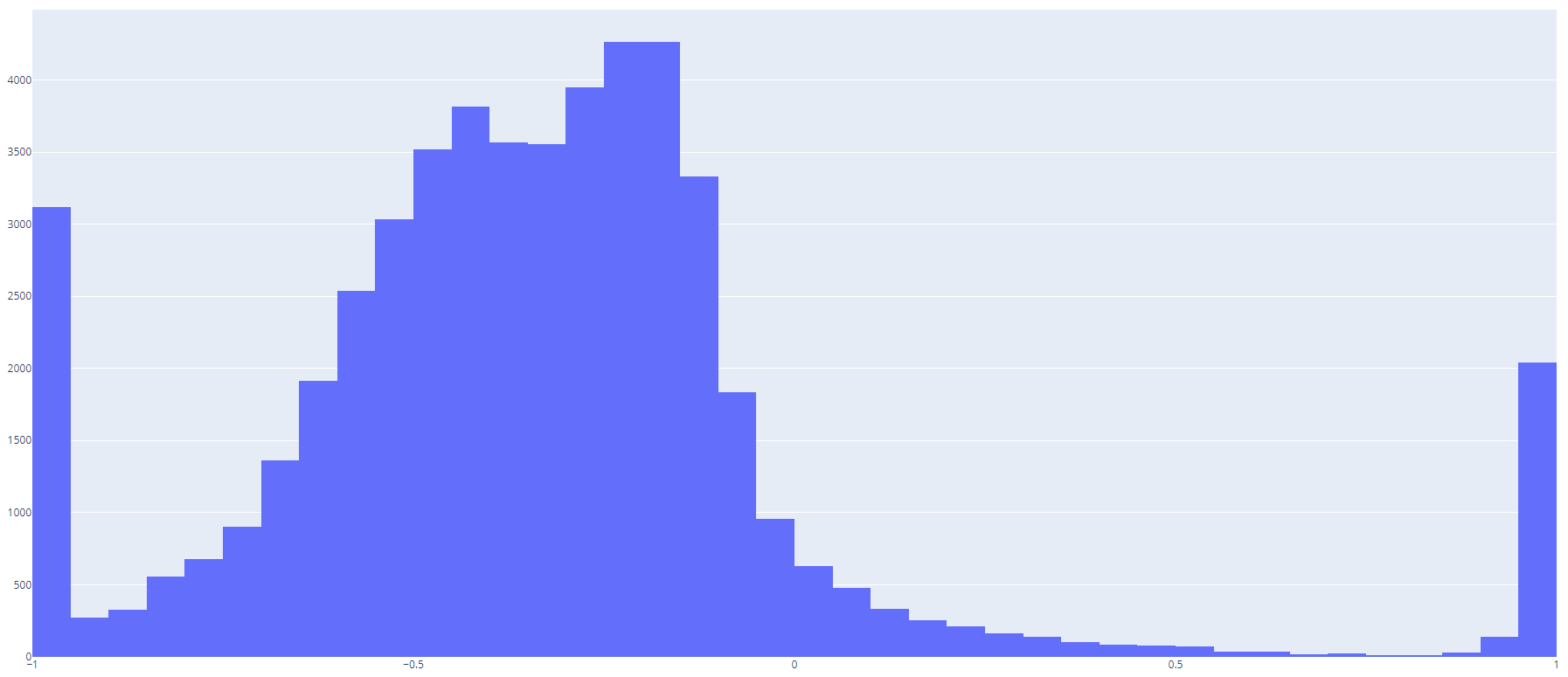
全曲の分類結果の全体像は下記のようになっています。
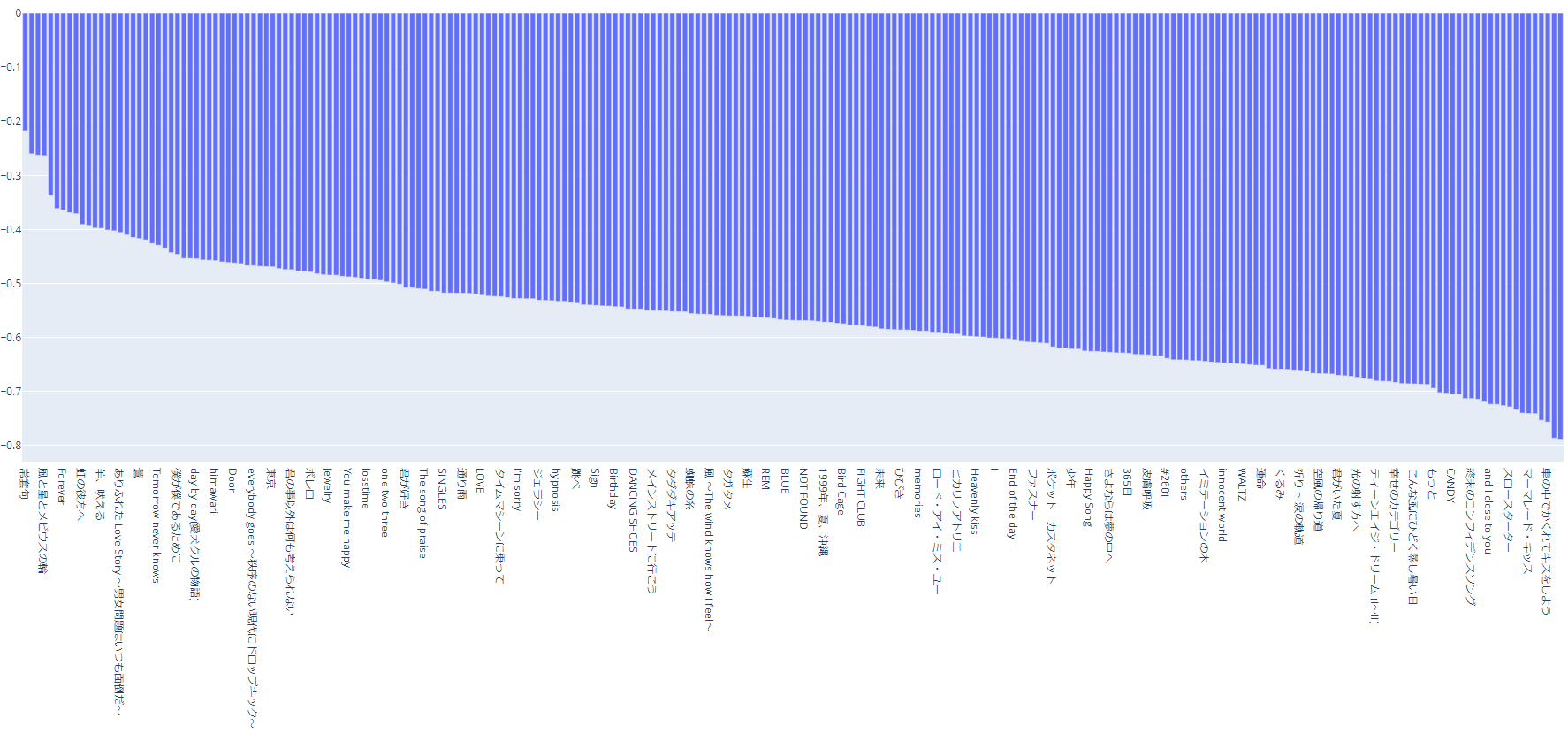
単語感情極性対応表 のスコアのヒストグラム(0.05刻み)を見てみると、下記のようになっています。下記のような構成となっているので、全体がネガティブに分類されるのは納得です。
感情分析はとても難しい
今回検証してみて、やはり感情分析は難しいと感じました。難しいポイントとしては、
- 日本語は単語がいろいろな形に変わるので、全てのパターンをカバーするのは難しい
- ひらがな、カタカナ、漢字、英語など、文章の中にいろいろな形の言語が混ざっている
- 文章を単語に区切るのがそもそも難しい
- 同じ単語でも文脈で違う意味になる場合がある
精度を上げるためには、形態素解析の精度を上げることと、自分の使用する環境に合わせた極性辞書の自作などが必要になりそうです。
今回使用していない 日本語評価極性辞書 を使った分析はこちらに記載しています。若干、今回とは違った分析結果になった部分、同じような分析結果になった部分はありますが、やはり難しかったです。
上記の辞書以外にも、Googleの「Cloud Natural Language API」でも感情分析ができるので、こちらでも試してみようと思います。
今回は、「3. Pythonによる自然言語処理 5-3. 日本語文の感情値分析[単語感情極性値対応表]」の記事を参考にさせていただきました。