はじめに
Azureクラウドアプリケーションアーキテクチャガイドより、ビッグデータアーキテクチャに関してまとめます。
連載目次
Azureアーキテクチャガイドまとめ 1 【はじめに】
Azureアーキテクチャガイドまとめ 2【N層】
Azureアーキテクチャガイドまとめ 3 【Webキューワーカー】
Azureアーキテクチャガイドまとめ 4 【マイクロサービス】
Azureアーキテクチャガイドまとめ 5 【CQRS】
Azureアーキテクチャガイドまとめ 6 【イベントドリブンアーキテクチャ】
Azureアーキテクチャガイドまとめ 7 【ビッグデータアーキテクチャ】 → 本記事
Azureアーキテクチャガイドまとめ 8 【ビッグコンピューティングアーキテクチャ】
ビッグデータの背景と最近の流れ
まずはビッグデータが発生した背景と、それを取り巻く近年の流れを整理します。
以下に挙げる変化により、そのままの形では解析に要する計算資源の確保が現実的でないほどに大きなデータセットの蓄積が可能になりました。
- ストレージコストの低下
- データ収集手段の増加
- データ収集のスピードアップ
これに応じて、データを分割し、並列処理を行い、最終的にそれらを統合して分析結果を出力する、というアーキテクチャの要請が強くなっていきます。HadoopやApache Sparkは、そんな中開発されたオープンソースフレームワークの代表選手です。
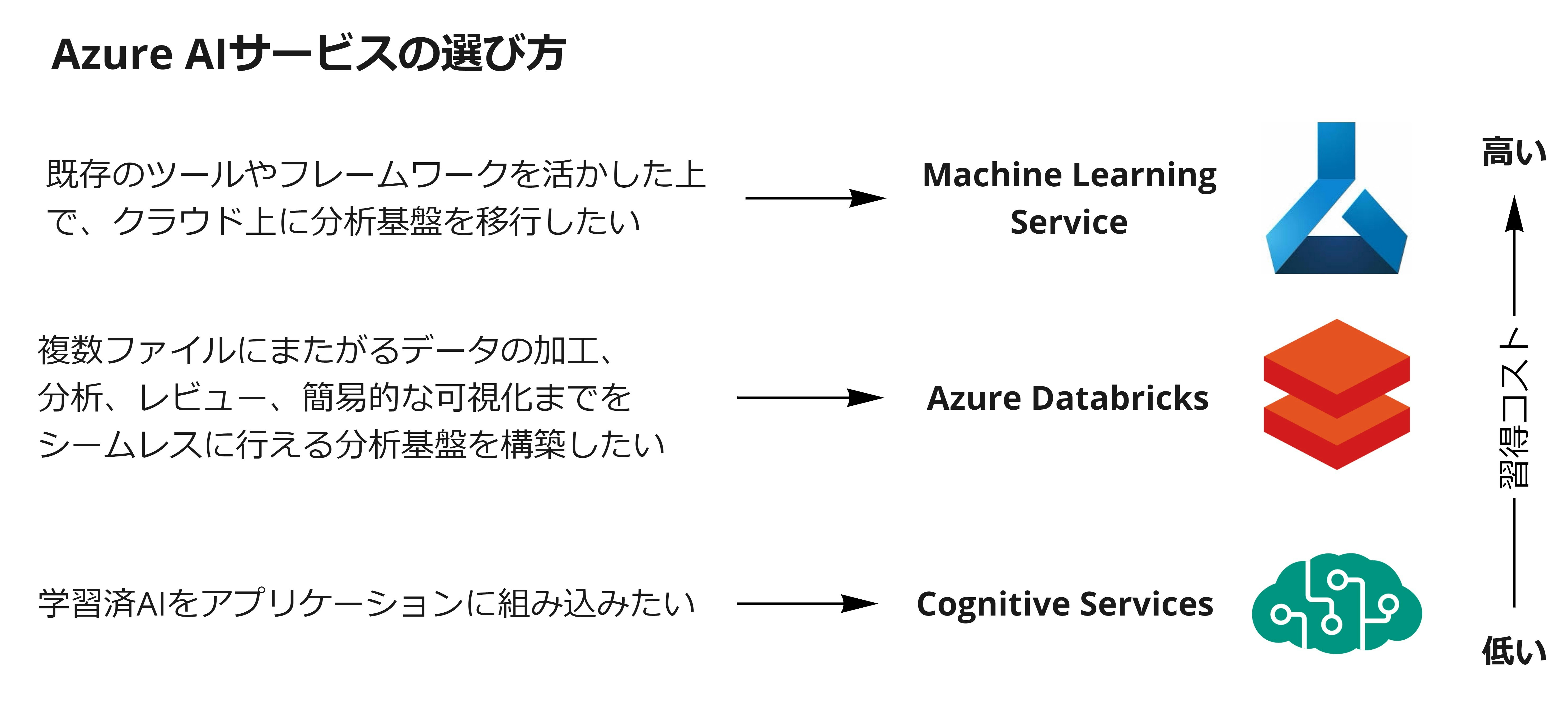
以前はこれらを使いこなすために高いスキルが必要でしたが、現在はハードルを数段下げてくれるAIサービスが揃ってきています。Azureサービスで代表的なものは以下の3種類。
- Machine Learning Services: 専門家向け分析基盤
- Databricks: 非専門家にも扱いやすい分析基盤
- Cognitive Services: AIのアプリ実装のためのAPI
以下のように自身のスキルや要件に応じて選ぶのが良さそうです。
概要
スタイルの説明に入ります。従来のデータベースシステムにとって、大きすぎる/複雑すぎるデータの処理や分析を行うのに適したアーキテクチャです。例えば以下のようなケース。
- 保管中のビッグデータソースのバッチ処理
- 伝送中のビックデータのリアルタイム処理
- ビックデータの対話的な調査
- 予測分析
- 機械学習
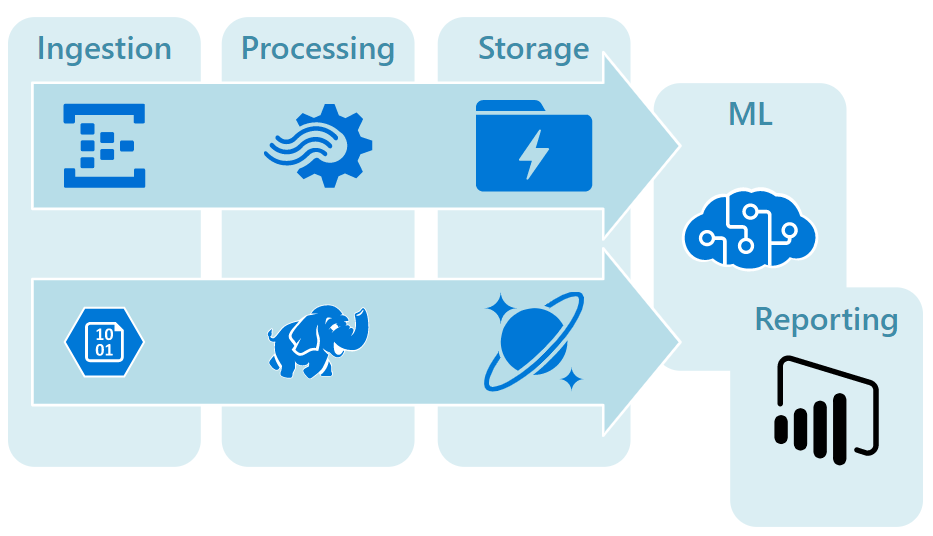
コンポーネント
ほとんどのビックデータアーキテクチャには次のコンポーネントの一部、またはすべてが含まれます。
-
データソース
- アプリケーションデータストア (RDBなど)
- 静的ファイル (ログファイルなど)
- リアルタイムデータソース (IoTデバイスなど)
-
ストレージ
- 一般にデータレイクと呼ばれる
- 分散型ファイルストア
- 様々な形式の大規模ファイルを大量に保存
-
バッチ処理
- データセットが非常に大きいため、バッチ処理が必要
-
リアルタイムのメッセージ取り込み
- キャプチャして保存する手段をアーキテクチャに取り込む
- メッセージ取り込みストア
- ストリーム処理
- 分析データストア
- 分析とレポート作成
- オーケストレーション
データを集めるところから含めると、ざっくりと以下のような流れになります。
対応するAzureサービス
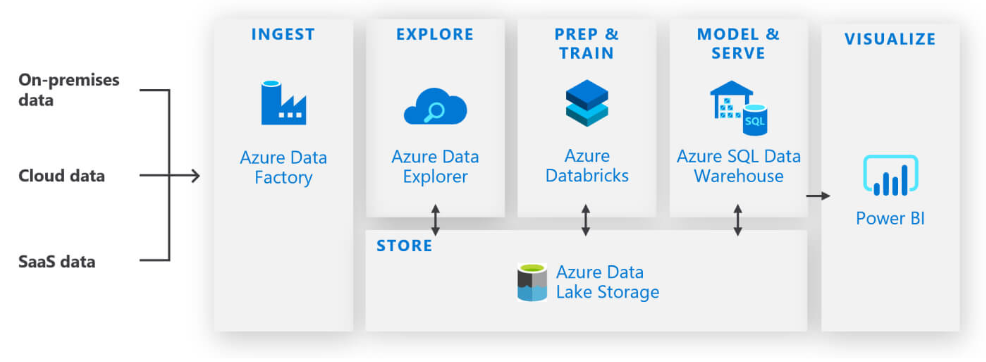
データの保存や中継点に使用するサービス、HadoopベースのテクノロジスタックであるHDInsightに加えて、よりマネージドな分析環境構築が可能なAIサービス群もまとめます。
Machine Learning Service
- モデルの構築
- クラウドからエッジまで場所を選ばないデプロイ
- デスクトップからオンデマンドでのスケーリング
- 自動化された特徴量エンジニアリング、アルゴリズム選択、ハイパーパラメータスイープ
- ドラッグアンドドロップ対応のビジュアルインターフェイスあり
-
MLOps (機械学習用のDevOpcs)
- 学習のライフサイクル全体の管理
- パイプラインの構築・効率化
- デプロイ済モデルのパフォーマンス管理
- 各種データサイエンス向けフレームワーク及びライブラリサポート
Azure Databricks
- 高速で最適化されたApache Spark環境を数分でセットアップ
- Azure Machine Learningがネイティブ統合
- 自動でスケーリング
- GitHubとAzure DevOpsで容易にノートブックのバージョン管理
- 各種データサイエンス向けフレームワーク及びライブラリサポート
- 多種の言語サポート
- Python
- Scala
- R
- Java
- SQL
- データの取得から分析から可視化までのシームレスな連携
Cognitive Services
以下5つのカテゴリで、学習済AIのAPIが用意されています。本当に数多くのサービスがあるので、こちらをチェックしてみてください。プレビューを見てみるだけでも面白いですよ。
- 視覚
- 音声
- 言語
- 決定
- 検索
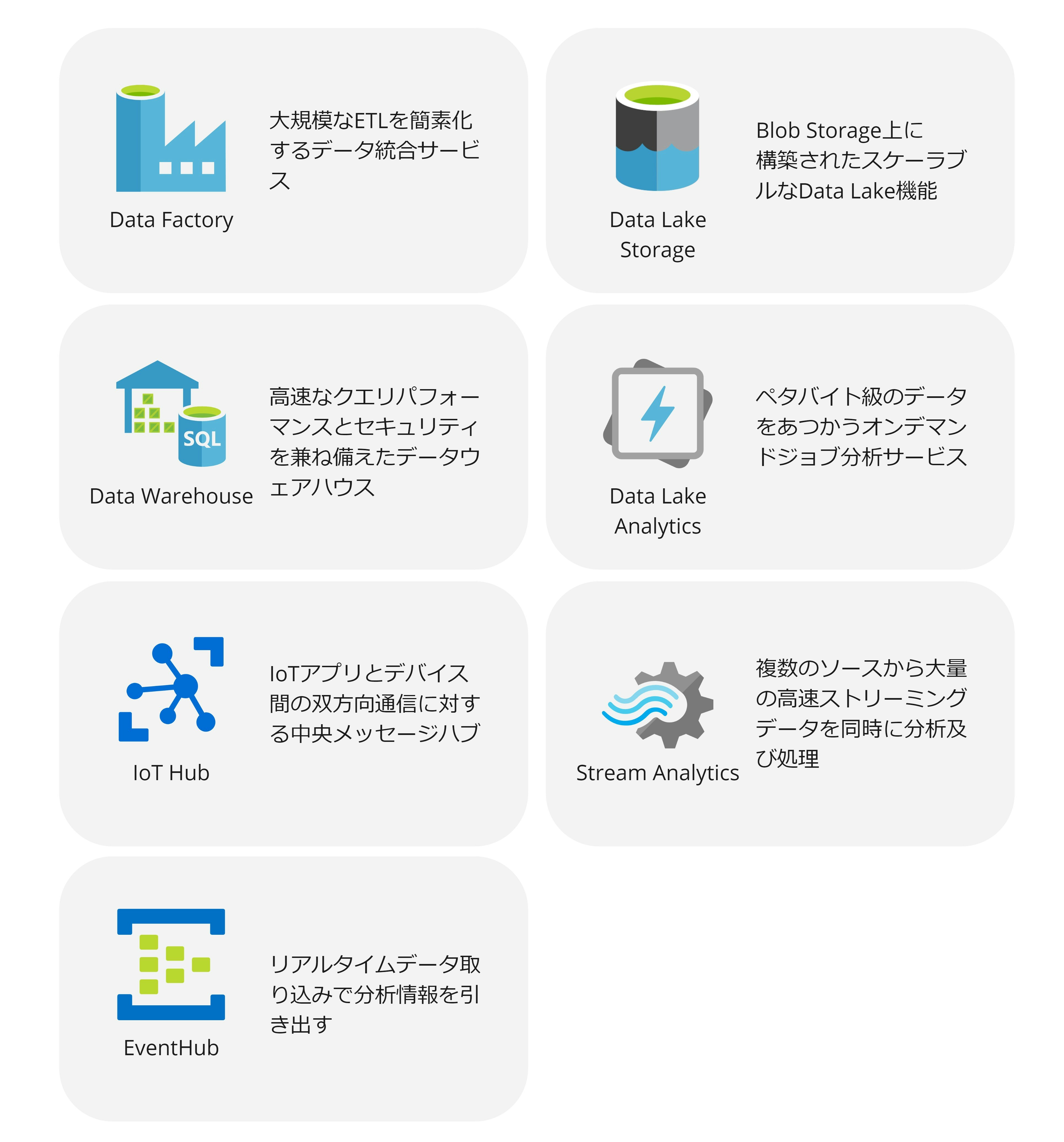
データの保存や中継点に使用するサービス
分析基盤のコアサービス周辺を支えるサービス群です。
- Azure Data Factory
- Azure Data Lake Storage
- Azure Data Lake Analytics
- Azure Data Warehouse
- Azure Stream Analytics
- Azure Event Hub
-
Azure IoT Hub
HDInsight
Apache Hadoopのオープンソース分析プラットフォーム各種を統合的に使えるようにしたサービスがHDInsightです。
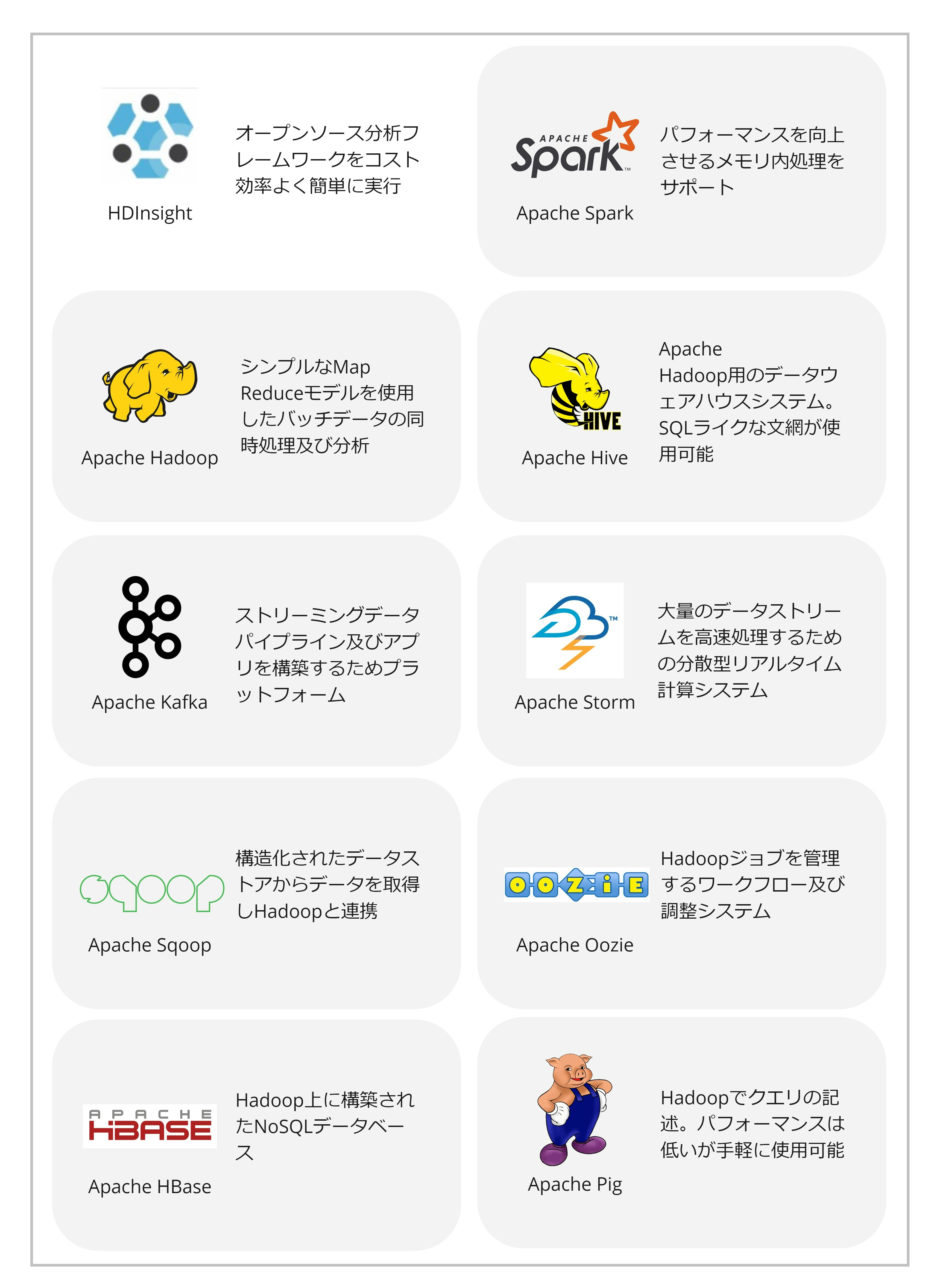
利点
- AzureマネージドサービスとApacheテクノロジを混在させ、既存のスキルや投資を活用
- 並列処理によるハイパフォーマンス
- スケールアウトプロビジョニングによる柔軟な拡張性
- 既存のソリューションとの相互運用性
課題
-
複雑性
- 複数の処理が必要になるので、複雑なアーキテクチャになる
- 構築、テスト、トラブルシューティングが困難な作業になりやすい
- パフォーマンス最適化のために多数の構成設定を使用する必要がある場合あり
-
スキルセット
- 高度に専門的で他のアプリケーションアーキテクチャでは一般的でないフレームワークや言語
- 一方で普及している言語に基づいた新しいAPIも生まれている
-
テクノロジの成熟度
- テクノロジの多くは現在も進化中
- Sparkのような新しいテクノロジの場合、新リリースのたびに大幅な変更や機能拡張も
- マネージドサービスも今後進化していく可能性が高い
-
セキュリティ
- データはデータレイクに集中的に保存
- このデータへのアクセス保護に困難が伴う場合も
ベストプラクティス
本アーキテクチャのベストプラクティスは以下の通り。AIサービスの活用によって、かなりのパートがカバーされます。
-
並列処理
- 静的データファイルを分割可能な形式で作成・保存
- 複数のクラスターノードの並列実行でジョブ時間の短縮
-
データの分割
- データファイルとテーブルなどのデータ構造を分割
- クエリで用いられるテーブルの分割
- データ取り込みやジョブスケジューリングの簡略化
-
データレイクの使用
- 「収集 → 蓄積 → 処理 → 分析・ビジュアライズ」の順になるような分析基盤
- データは処理の前にスキーマを適用
- アーキテクチャに柔軟性が生まれ、データ取り込みのボトルネックを防げる
-
適所でのデータ処理
- データを分散データストアで処理し、必要な構造に変換して分析へ
- 変換 → 抽出 → 読み込みの順
-
使用率と時間コストのバランス
- クラスターの処理時間、個数、単価を考慮
- 最も費用対効果の高い構成にする
-
クラスターリソースの分割
- ワークロードに応じて分割することでパフォーマンスを向上
-
データ取り込みの調整・オーケストレーション
- Azure Data Factoryやオーケストレーションワークフロー、パイプラインを使用
-
機密データの除外
- データ取り込みの早い段階で機密性の高いデータを除外し、データレイクに保存されないようにする
まとめ
ビッグデータアーキテクチャの特徴と使用されるサービスについて見ていきました。次回は最後の一つ、ビッグコンピューティングアーキテクチャについてまとめます。お楽しみに!
参考リンク
Azureアーキテクチャセンター
Azureクラウドアプリケーションアーキテクチャガイド ダウンロードページ
ビッグデータアーキテクチャ